 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaturn: An Optimized Data System for Large Model Deep Learning Workloads
Paper and Code

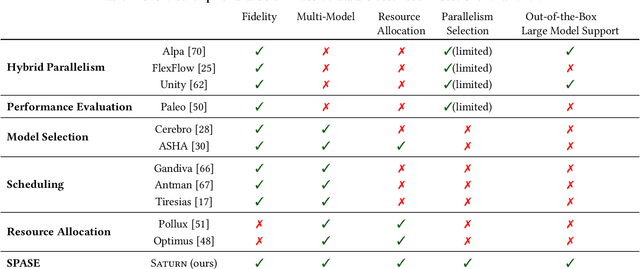

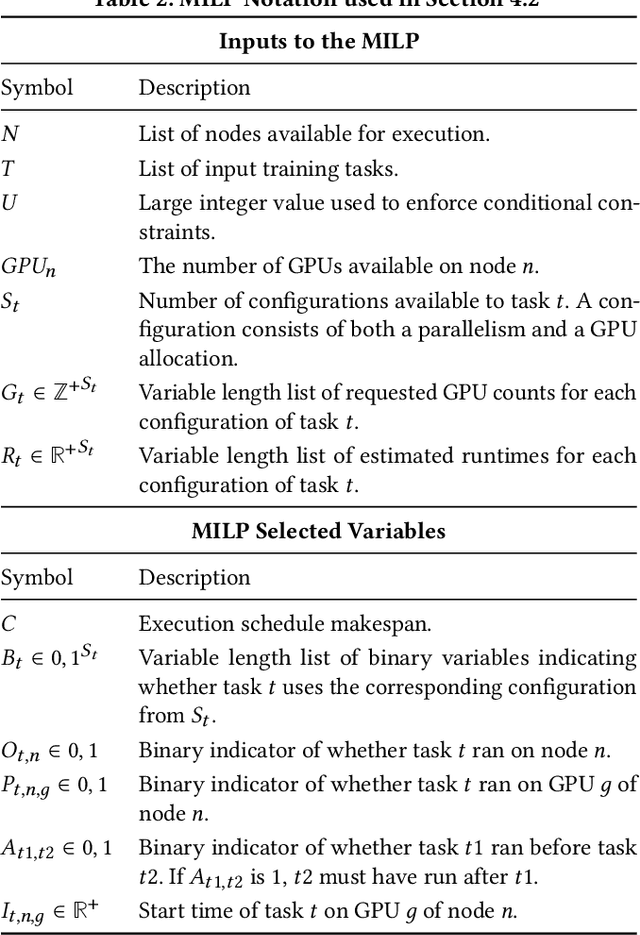
Large language models such as GPT-3 & ChatGPT have transformed deep learning (DL), powering applications that have captured the public's imagination. These models are rapidly being adopted across domains for analytics on various modalities, often by finetuning pre-trained base models. Such models need multiple GPUs due to both their size and computational load, driving the development of a bevy of "model parallelism" techniques & tools. Navigating such parallelism choices, however, is a new burden for end users of DL such as data scientists, domain scientists, etc. who may lack the necessary systems knowhow. The need for model selection, which leads to many models to train due to hyper-parameter tuning or layer-wise finetuning, compounds the situation with two more burdens: resource apportioning and scheduling. In this work, we tackle these three burdens for DL users in a unified manner by formalizing them as a joint problem that we call SPASE: Select a Parallelism, Allocate resources, and SchedulE. We propose a new information system architecture to tackle the SPASE problem holistically, representing a key step toward enabling wider adoption of large DL models. We devise an extensible template for existing parallelism schemes and combine it with an automated empirical profiler for runtime estimation. We then formulate SPASE as an MILP. We find that direct use of an MILP-solver is significantly more effective than several baseline heuristics. We optimize the system runtime further with an introspective scheduling approach. We implement all these techniques into a new data system we call Saturn. Experiments with benchmark DL workloads show that Saturn achieves 39-49% lower model selection runtimes than typical current DL practice.