 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydra: A System for Large Multi-Model Deep Learning
Paper and Code
Oct 23, 2021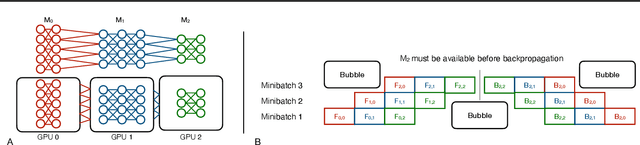

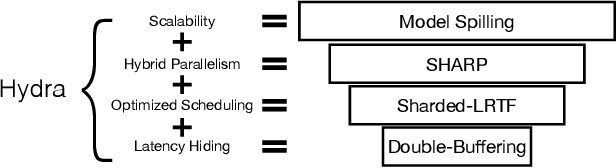
Training deep learning (DL) models that do not fit into the memory of a single GPU is a vexed process, forcing users to procure multiple GPUs to adopt model-parallel execution. Unfortunately, sequential dependencies in neural architectures often block efficient multi-device training, leading to suboptimal performance. We present 'model spilling', a technique aimed at models such as Transformers and CNNs to move groups of layers, or shards, between DRAM and GPU memory, thus enabling arbitrarily large models to be trained even on just one GPU. We then present a set of novel techniques leveraging spilling to raise efficiency for multi-model training workloads such as model selection: a new hybrid of task- and model-parallelism, a new shard scheduling heuristic, and 'double buffering' to hide latency. We prototype our ideas into a system we call HYDRA to support seamless single-model and multi-model training of large DL models. Experiments with real benchmark workloads show that HYDRA is over 7x faster than regular model parallelism and over 50% faster than state-of-the-art industrial tools for pipeline parallelism.