 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Value Decomposition via Unit-Wise Attentive State Representation for Cooperative Multi-Agent Reinforcement Learning
May 12, 2023


In cooperative multi-agent reinforcement learning (MARL), the environmental stochasticity and uncertainties will increase exponentially when the number of agents increases, which puts hard pressure on how to come up with a compact latent representation from partial observation for boosting value decomposition. To tackle these issues, we propose a simple yet powerful method that alleviates partial observability and efficiently promotes coordination by introducing the UNit-wise attentive State Representation (UNSR). In UNSR, each agent learns a compact and disentangled unit-wise state representation outputted from transformer blocks, and produces its local action-value function. The proposed UNSR is used to boost the value decomposition with a multi-head attention mechanism for producing efficient credit assignment in the mixing network, providing an efficient reasoning path between the individual value function and joint value function. Experimental results demonstrate that our method achieves superior performance and data efficiency compared to solid baselines on the StarCraft II micromanagement challenge. Additional ablation experiments also help identify the key factors contributing to the performance of UNSR.
WILD-SCAV: Benchmarking FPS Gaming AI on Unity3D-based Environments
Oct 14, 2022
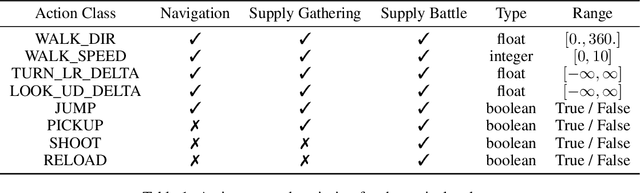

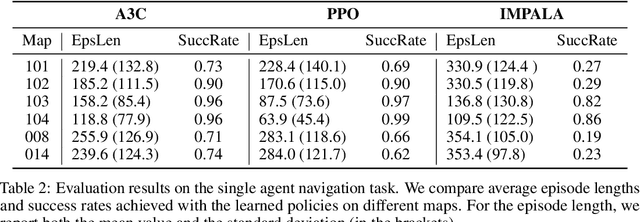
Recent advances in deep reinforcement learning (RL) have demonstrated complex decision-making capabilities in simulation environments such as Arcade Learning Environment, MuJoCo, and ViZDoom. However, they are hardly extensible to more complicated problems, mainly due to the lack of complexity and variations in the environments they are trained and tested on. Furthermore, they are not extensible to an open-world environment to facilitate long-term exploration research. To learn realistic task-solving capabilities, we need to develop an environment with greater diversity and complexity. We developed WILD-SCAV, a powerful and extensible environment based on a 3D open-world FPS (First-Person Shooter) game to bridge the gap. It provides realistic 3D environments of variable complexity, various tasks, and multiple modes of interaction, where agents can learn to perceive 3D environments, navigate and plan, compete and cooperate in a human-like manner. WILD-SCAV also supports different complexities, such as configurable maps with different terrains, building structures and distributions, and multi-agent settings with cooperative and competitive tasks. The experimental results on configurable complexity, multi-tasking, and multi-agent scenarios demonstrate the effectiveness of WILD-SCAV in benchmarking various RL algorithms, as well as it is potential to give rise to intelligent agents with generalized task-solving abilities. The link to our open-sourced code can be found here https://github.com/inspirai/wilderness-scavenger.