 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Diffusion Model for Multi-Agent Dynamic Task Decomposition
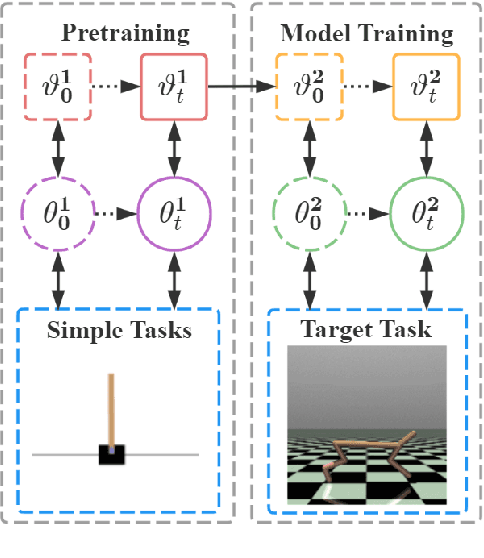
Nov 17, 2025Task decomposition has shown promise in complex cooperative multi-agent reinforcement learning (MARL) tasks, which enables efficient hierarchical learning for long-horizon tasks in dynamic and uncertain environments. However, learning dynamic task decomposition from scratch generally requires a large number of training samples, especially exploring the large joint action space under partial observability. In this paper, we present the Conditional Diffusion Model for Dynamic Task Decomposition (C$\text{D}^\text{3}$T), a novel two-level hierarchical MARL framework designed to automatically infer subtask and coordination patterns. The high-level policy learns subtask representation to generate a subtask selection strategy based on subtask effects. To capture the effects of subtasks on the environment, C$\text{D}^\text{3}$T predicts the next observation and reward using a conditional diffusion model. At the low level, agents collaboratively learn and share specialized skills within their assigned subtasks. Moreover, the learned subtask representation is also used as additional semantic information in a multi-head attention mixing network to enhance value decomposition and provide an efficient reasoning bridge between individual and joint value functions. Experimental results on various benchmarks demonstrate that C$\text{D}^\text{3}$T achieves better performance than existing baselines.
Concept Learning for Cooperative Multi-Agent Reinforcement Learning
Jul 27, 2025

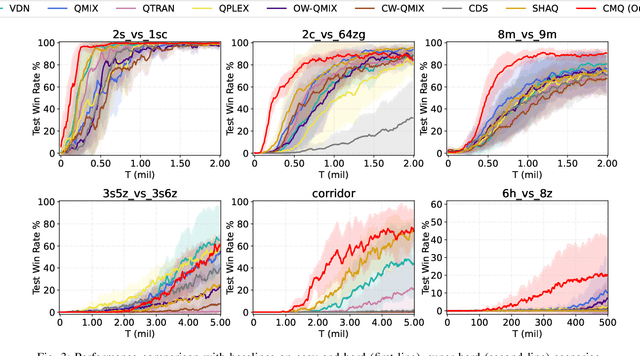

Despite substantial progress in applying neural networks (NN) to multi-agent reinforcement learning (MARL) areas, they still largely suffer from a lack of transparency and interoperability. However, its implicit cooperative mechanism is not yet fully understood due to black-box networks. In this work, we study an interpretable value decomposition framework via concept bottleneck models, which promote trustworthiness by conditioning credit assignment on an intermediate level of human-like cooperation concepts. To address this problem, we propose a novel value-based method, named Concepts learning for Multi-agent Q-learning (CMQ), that goes beyond the current performance-vs-interpretability trade-off by learning interpretable cooperation concepts. CMQ represents each cooperation concept as a supervised vector, as opposed to existing models where the information flowing through their end-to-end mechanism is concept-agnostic. Intuitively, using individual action value conditioning on global state embeddings to represent each concept allows for extra cooperation representation capacity. Empirical evaluations on the StarCraft II micromanagement challenge and level-based foraging (LBF) show that CMQ achieves superior performance compared with the state-of-the-art counterparts. The results also demonstrate that CMQ provides more cooperation concept representation capturing meaningful cooperation modes, and supports test-time concept interventions for detecting potential biases of cooperation mode and identifying spurious artifacts that impact cooperation.
Discretizing Continuous Action Space with Unimodal Probability Distributions for On-Policy Reinforcement Learning
Aug 01, 2024For on-policy reinforcement learning, discretizing action space for continuous control can easily express multiple modes and is straightforward to optimize. However, without considering the inherent ordering between the discrete atomic actions, the explosion in the number of discrete actions can possess undesired properties and induce a higher variance for the policy gradient estimator. In this paper, we introduce a straightforward architecture that addresses this issue by constraining the discrete policy to be unimodal using Poisson probability distributions. This unimodal architecture can better leverage the continuity in the underlying continuous action space using explicit unimodal probability distributions. We conduct extensive experiments to show that the discrete policy with the unimodal probability distribution provides significantly faster convergence and higher performance for on-policy reinforcement learning algorithms in challenging control tasks, especially in highly complex tasks such as Humanoid. We provide theoretical analysis on the variance of the policy gradient estimator, which suggests that our attentively designed unimodal discrete policy can retain a lower variance and yield a stable learning process.
BiERL: A Meta Evolutionary Reinforcement Learning Framework via Bilevel Optimization
Aug 01, 2023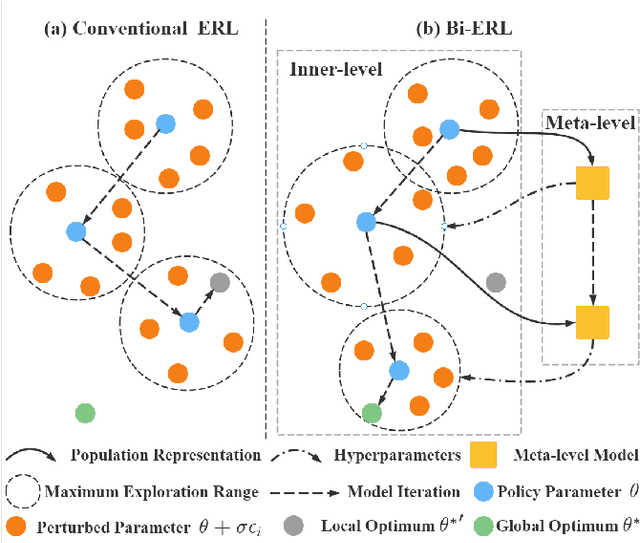
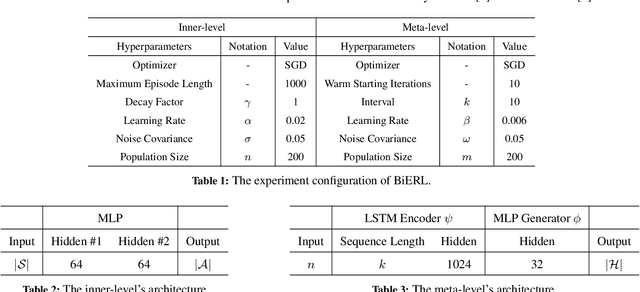
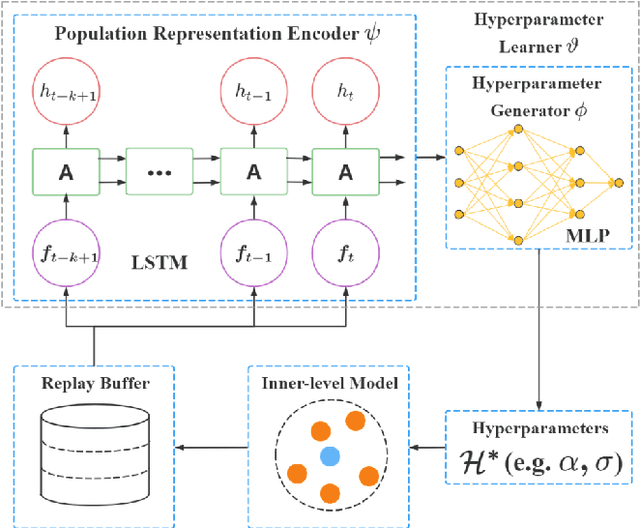
Evolutionary reinforcement learning (ERL) algorithms recently raise attention in tackling complex reinforcement learning (RL) problems due to high parallelism, while they are prone to insufficient exploration or model collapse without carefully tuning hyperparameters (aka meta-parameters). In the paper, we propose a general meta ERL framework via bilevel optimization (BiERL) to jointly update hyperparameters in parallel to training the ERL model within a single agent, which relieves the need for prior domain knowledge or costly optimization procedure before model deployment. We design an elegant meta-level architecture that embeds the inner-level's evolving experience into an informative population representation and introduce a simple and feasible evaluation of the meta-level fitness function to facilitate learning efficiency. We perform extensive experiments in MuJoCo and Box2D tasks to verify that as a general framework, BiERL outperforms various baselines and consistently improves the learning performance for a diversity of ERL algorithms.
Boosting Value Decomposition via Unit-Wise Attentive State Representation for Cooperative Multi-Agent Reinforcement Learning
May 12, 2023


In cooperative multi-agent reinforcement learning (MARL), the environmental stochasticity and uncertainties will increase exponentially when the number of agents increases, which puts hard pressure on how to come up with a compact latent representation from partial observation for boosting value decomposition. To tackle these issues, we propose a simple yet powerful method that alleviates partial observability and efficiently promotes coordination by introducing the UNit-wise attentive State Representation (UNSR). In UNSR, each agent learns a compact and disentangled unit-wise state representation outputted from transformer blocks, and produces its local action-value function. The proposed UNSR is used to boost the value decomposition with a multi-head attention mechanism for producing efficient credit assignment in the mixing network, providing an efficient reasoning path between the individual value function and joint value function. Experimental results demonstrate that our method achieves superior performance and data efficiency compared to solid baselines on the StarCraft II micromanagement challenge. Additional ablation experiments also help identify the key factors contributing to the performance of UNSR.
MIXRTs: Toward Interpretable Multi-Agent Reinforcement Learning via Mixing Recurrent Soft Decision Trees
Sep 15, 2022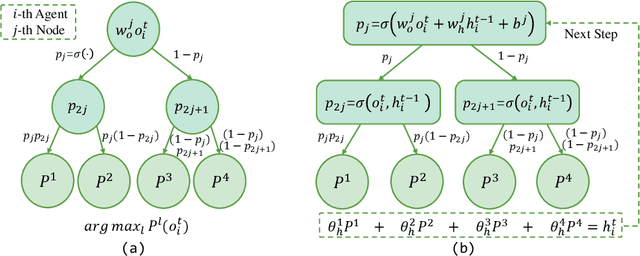

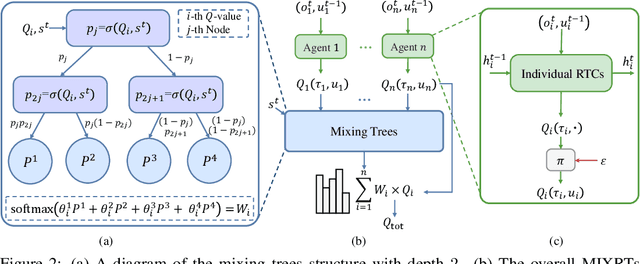
Multi-agent reinforcement learning (MARL) recently has achieved tremendous success in a wide range of fields. However, with a black-box neural network architecture, existing MARL methods make decisions in an opaque fashion that hinders humans from understanding the learned knowledge and how input observations influence decisions. Our solution is MIXing Recurrent soft decision Trees (MIXRTs), a novel interpretable architecture that can represent explicit decision processes via the root-to-leaf path of decision trees. We introduce a novel recurrent structure in soft decision trees to address partial observability, and estimate joint action values via linearly mixing outputs of recurrent trees based on local observations only. Theoretical analysis shows that MIXRTs guarantees the structural constraint with additivity and monotonicity in factorization. We evaluate MIXRTs on a range of challenging StarCraft II tasks. Experimental results show that our interpretable learning framework obtains competitive performance compared to widely investigated baselines, and delivers more straightforward explanations and domain knowledge of the decision processes.
Rule-Based Reinforcement Learning for Efficient Robot Navigation with Space Reduction
Apr 15, 2021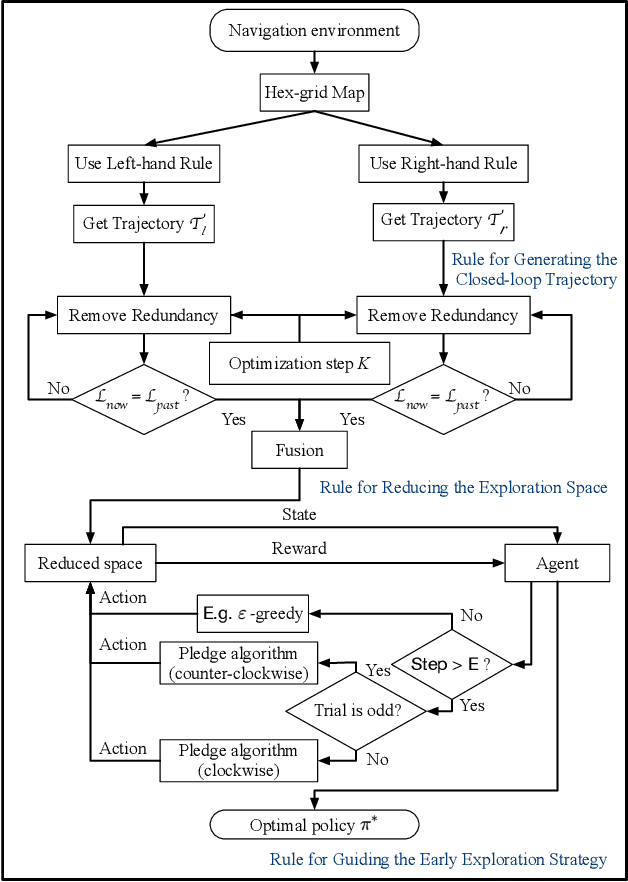
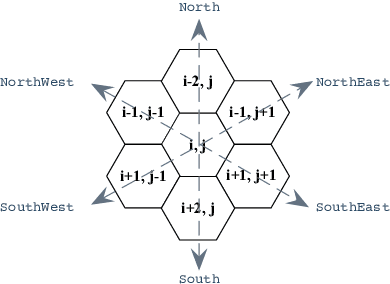

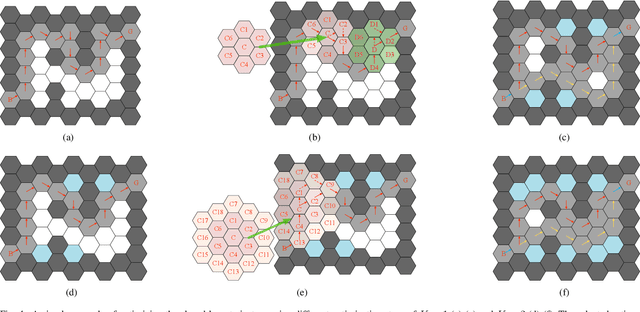
For real-world deployments, it is critical to allow robots to navigate in complex environments autonomously. Traditional methods usually maintain an internal map of the environment, and then design several simple rules, in conjunction with a localization and planning approach, to navigate through the internal map. These approaches often involve a variety of assumptions and prior knowledge. In contrast, recent reinforcement learning (RL) methods can provide a model-free, self-learning mechanism as the robot interacts with an initially unknown environment, but are expensive to deploy in real-world scenarios due to inefficient exploration. In this paper, we focus on efficient navigation with the RL technique and combine the advantages of these two kinds of methods into a rule-based RL (RuRL) algorithm for reducing the sample complexity and cost of time. First, we use the rule of wall-following to generate a closed-loop trajectory. Second, we employ a reduction rule to shrink the trajectory, which in turn effectively reduces the redundant exploration space. Besides, we give the detailed theoretical guarantee that the optimal navigation path is still in the reduced space. Third, in the reduced space, we utilize the Pledge rule to guide the exploration strategy for accelerating the RL process at the early stage. Experiments conducted on real robot navigation problems in hex-grid environments demonstrate that RuRL can achieve improved navigation performance.
* Accepted by IEEE/ASME Transactions on Mechatronics, 2021, DOI: 10.1109/TMECH.2021.3072675