 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Robustness to Missing Video for Audiovisual Speech Recognition
Dec 19, 2023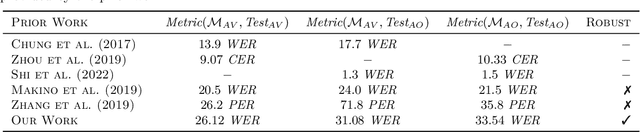
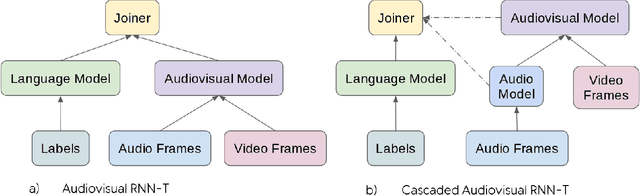
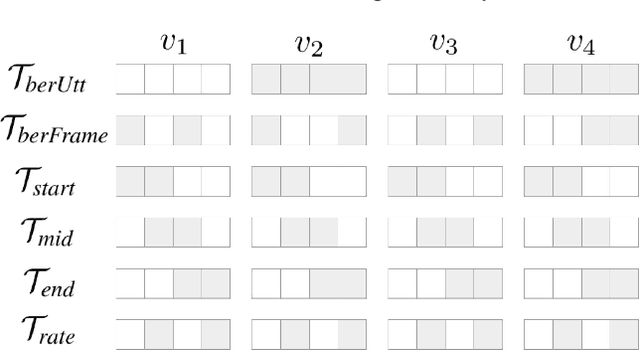
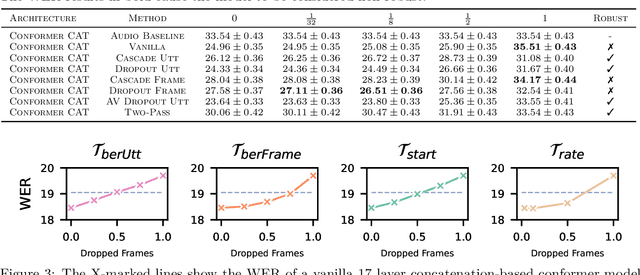
It has been shown that learning audiovisual features can lead to improved speech recognition performance over audio-only features, especially for noisy speech. However, in many common applications, the visual features are partially or entirely missing, e.g.~the speaker might move off screen. Multi-modal models need to be robust: missing video frames should not degrade the performance of an audiovisual model to be worse than that of a single-modality audio-only model. While there have been many attempts at building robust models, there is little consensus on how robustness should be evaluated. To address this, we introduce a framework that allows claims about robustness to be evaluated in a precise and testable way. We also conduct a systematic empirical study of the robustness of common audiovisual speech recognition architectures on a range of acoustic noise conditions and test suites. Finally, we show that an architecture-agnostic solution based on cascades can consistently achieve robustness to missing video, even in settings where existing techniques for robustness like dropout fall short.
Audio-visual fine-tuning of audio-only ASR models
Dec 14, 2023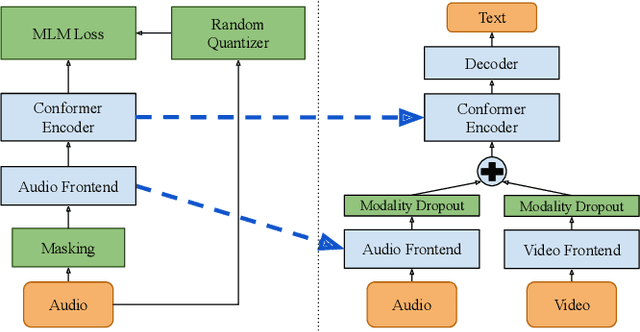
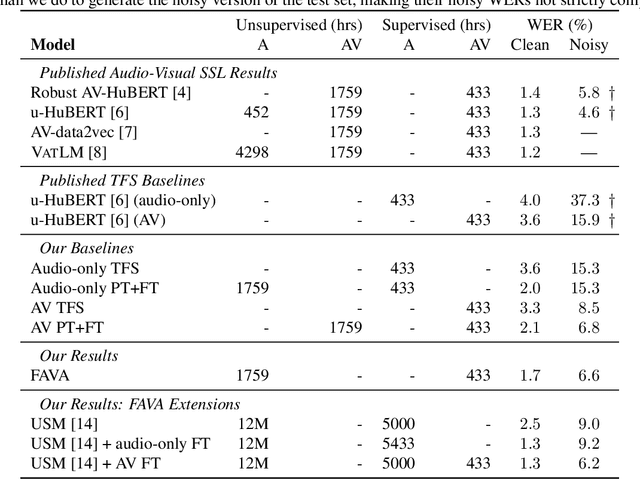

Audio-visual automatic speech recognition (AV-ASR) models are very effective at reducing word error rates on noisy speech, but require large amounts of transcribed AV training data. Recently, audio-visual self-supervised learning (SSL) approaches have been developed to reduce this dependence on transcribed AV data, but these methods are quite complex and computationally expensive. In this work, we propose replacing these expensive AV-SSL methods with a simple and fast \textit{audio-only} SSL method, and then performing AV supervised fine-tuning. We show that this approach is competitive with state-of-the-art (SOTA) AV-SSL methods on the LRS3-TED benchmark task (within 0.5% absolute WER), while being dramatically simpler and more efficient (12-30x faster to pre-train). Furthermore, we show we can extend this approach to convert a SOTA audio-only ASR model into an AV model. By doing so, we match SOTA AV-SSL results, even though no AV data was used during pre-training.
End-to-End Multi-Person Audio/Visual Automatic Speech Recognition
May 11, 2022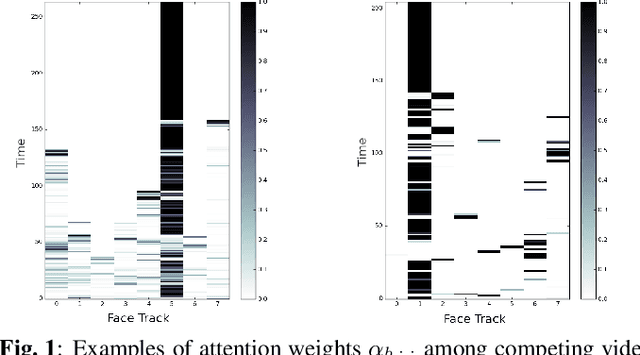

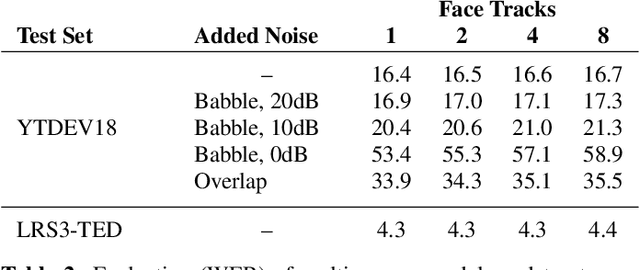
Traditionally, audio-visual automatic speech recognition has been studied under the assumption that the speaking face on the visual signal is the face matching the audio. However, in a more realistic setting, when multiple faces are potentially on screen one needs to decide which face to feed to the A/V ASR system. The present work takes the recent progress of A/V ASR one step further and considers the scenario where multiple people are simultaneously on screen (multi-person A/V ASR). We propose a fully differentiable A/V ASR model that is able to handle multiple face tracks in a video. Instead of relying on two separate models for speaker face selection and audio-visual ASR on a single face track, we introduce an attention layer to the ASR encoder that is able to soft-select the appropriate face video track. Experiments carried out on an A/V system trained on over 30k hours of YouTube videos illustrate that the proposed approach can automatically select the proper face tracks with minor WER degradation compared to an oracle selection of the speaking face while still showing benefits of employing the visual signal instead of the audio alone.
A Closer Look at Audio-Visual Multi-Person Speech Recognition and Active Speaker Selection
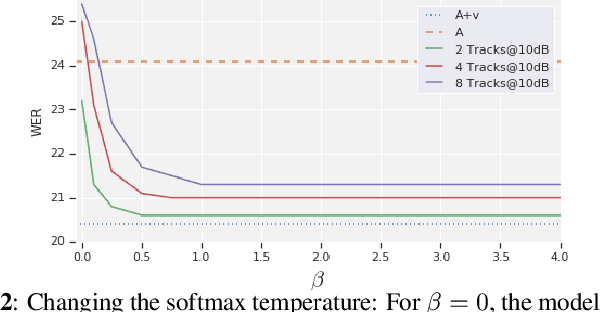
May 11, 2022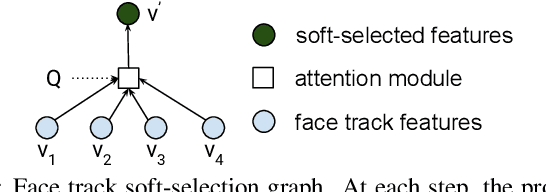
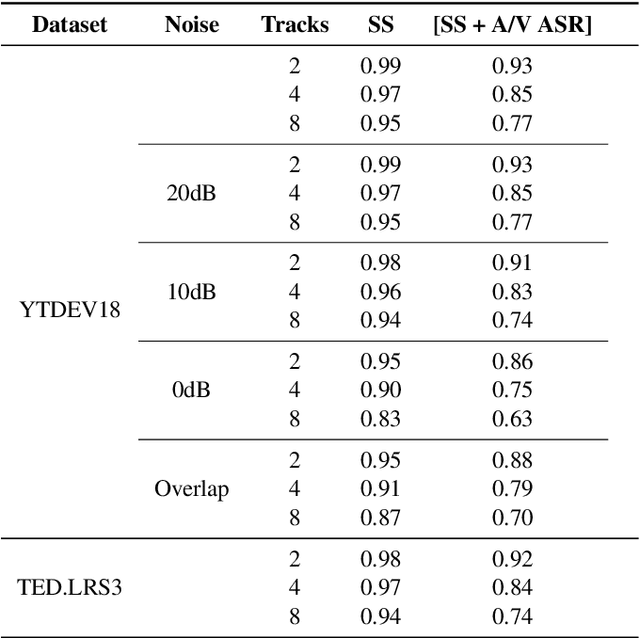
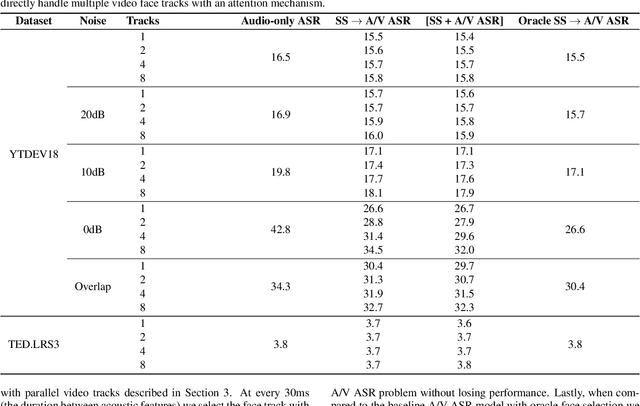
Audio-visual automatic speech recognition is a promising approach to robust ASR under noisy conditions. However, up until recently it had been traditionally studied in isolation assuming the video of a single speaking face matches the audio, and selecting the active speaker at inference time when multiple people are on screen was put aside as a separate problem. As an alternative, recent work has proposed to address the two problems simultaneously with an attention mechanism, baking the speaker selection problem directly into a fully differentiable model. One interesting finding was that the attention indirectly learns the association between the audio and the speaking face even though this correspondence is never explicitly provided at training time. In the present work we further investigate this connection and examine the interplay between the two problems. With experiments involving over 50 thousand hours of public YouTube videos as training data, we first evaluate the accuracy of the attention layer on an active speaker selection task. Secondly, we show under closer scrutiny that an end-to-end model performs at least as well as a considerably larger two-step system that utilizes a hard decision boundary under various noise conditions and number of parallel face tracks.
Best of Both Worlds: Multi-task Audio-Visual Automatic Speech Recognition and Active Speaker Detection
May 10, 2022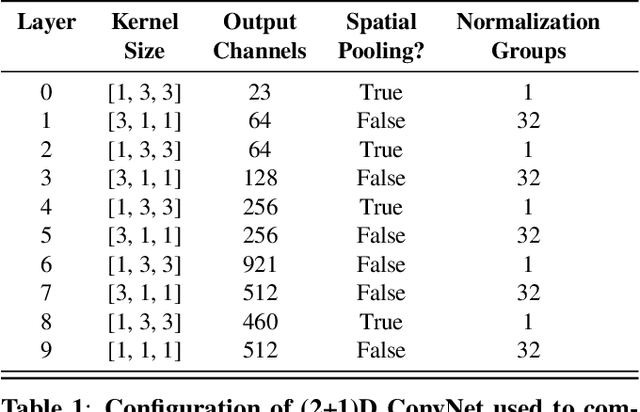
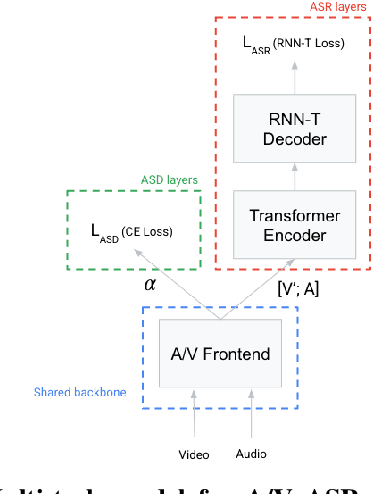
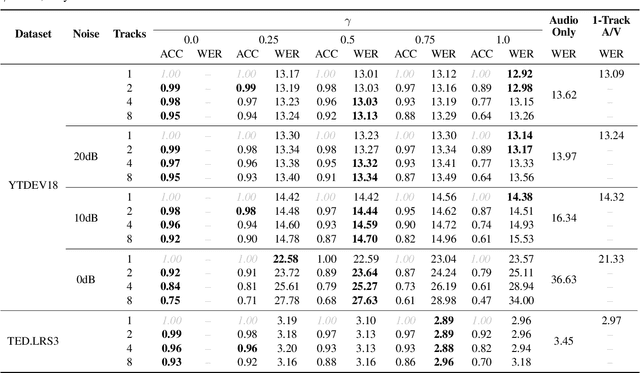
Under noisy conditions, automatic speech recognition (ASR) can greatly benefit from the addition of visual signals coming from a video of the speaker's face. However, when multiple candidate speakers are visible this traditionally requires solving a separate problem, namely active speaker detection (ASD), which entails selecting at each moment in time which of the visible faces corresponds to the audio. Recent work has shown that we can solve both problems simultaneously by employing an attention mechanism over the competing video tracks of the speakers' faces, at the cost of sacrificing some accuracy on active speaker detection. This work closes this gap in active speaker detection accuracy by presenting a single model that can be jointly trained with a multi-task loss. By combining the two tasks during training we reduce the ASD classification accuracy by approximately 25%, while simultaneously improving the ASR performance when compared to the multi-person baseline trained exclusively for ASR.
Transformer-Based Video Front-Ends for Audio-Visual Speech Recognition
Jan 25, 2022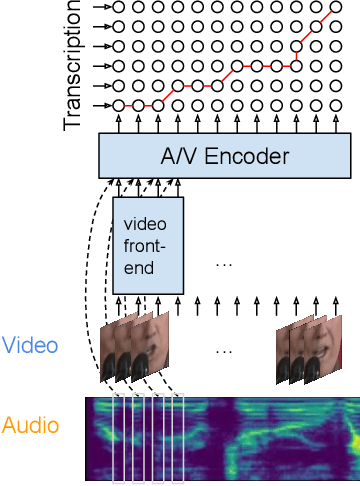
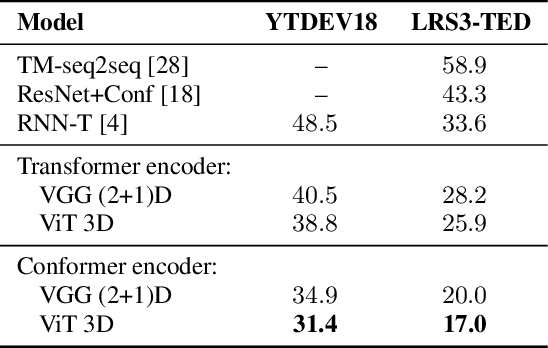
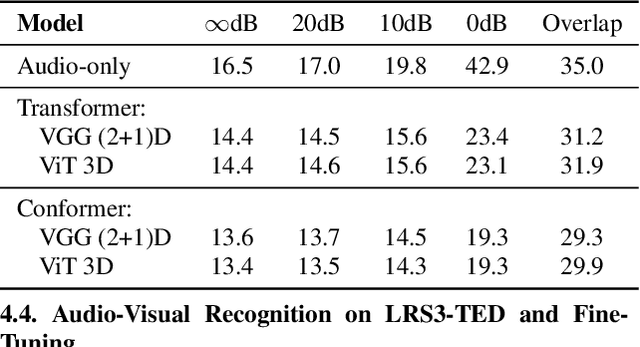
Audio-visual automatic speech recognition (AV-ASR) extends the speech recognition by introducing the video modality. In particular, the information contained in the motion of the speaker's mouth is used to augment the audio features. The video modality is traditionally processed with a 3D convolutional neural network (e.g. 3D version of VGG). Recently, image transformer networks arXiv:2010.11929 demonstrated the ability to extract rich visual features for the image classification task. In this work, we propose to replace the 3D convolution with a video transformer video feature extractor. We train our baselines and the proposed model on a large scale corpus of the YouTube videos. Then we evaluate the performance on a labeled subset of YouTube as well as on the public corpus LRS3-TED. Our best model video-only model achieves the performance of 34.9% WER on YTDEV18 and 19.3% on LRS3-TED which is a 10% and 9% relative improvements over the convolutional baseline. We achieve the state of the art performance of the audio-visual recognition on the LRS3-TED after fine-tuning our model (1.6% WER).
Audio-Visual Speech Recognition is Worth 32$\times$32$\times$8 Voxels
Sep 20, 2021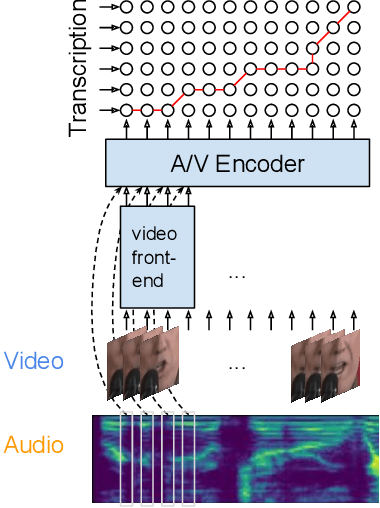


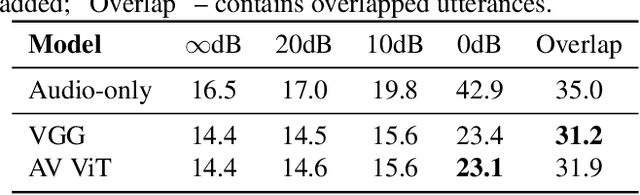
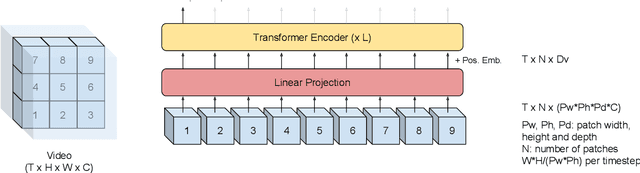
Audio-visual automatic speech recognition (AV-ASR) introduces the video modality into the speech recognition process, often by relying on information conveyed by the motion of the speaker's mouth. The use of the video signal requires extracting visual features, which are then combined with the acoustic features to build an AV-ASR system [1]. This is traditionally done with some form of 3D convolutional network (e.g. VGG) as widely used in the computer vision community. Recently, image transformers [2] have been introduced to extract visual features useful for image classification tasks. In this work, we propose to replace the 3D convolutional visual front-end with a video transformer front-end. We train our systems on a large-scale dataset composed of YouTube videos and evaluate performance on the publicly available LRS3-TED set, as well as on a large set of YouTube videos. On a lip-reading task, the transformer-based front-end shows superior performance compared to a strong convolutional baseline. On an AV-ASR task, the transformer front-end performs as well as (or better than) the convolutional baseline. Fine-tuning our model on the LRS3-TED training set matches previous state of the art. Thus, we experimentally show the viability of the convolution-free model for AV-ASR.
Recurrent Neural Network Transducer for Audio-Visual Speech Recognition
Nov 08, 2019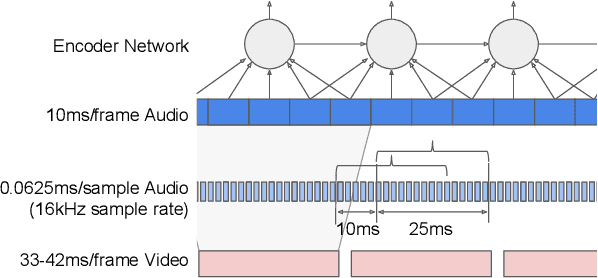
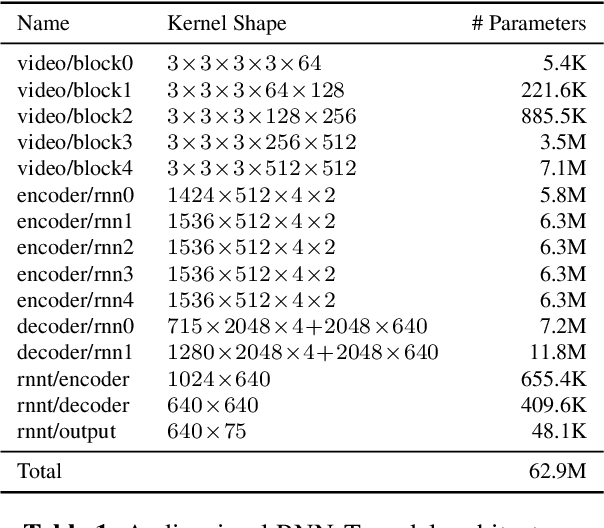
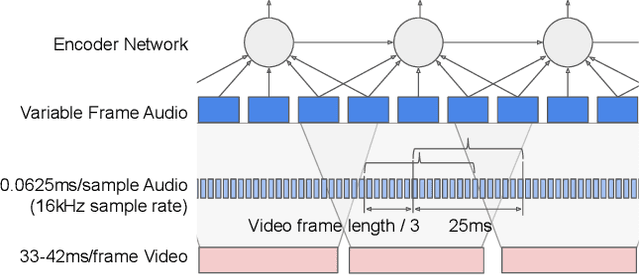

This work presents a large-scale audio-visual speech recognition system based on a recurrent neural network transducer (RNN-T) architecture. To support the development of such a system, we built a large audio-visual (A/V) dataset of segmented utterances extracted from YouTube public videos, leading to 31k hours of audio-visual training content. The performance of an audio-only, visual-only, and audio-visual system are compared on two large-vocabulary test sets: a set of utterance segments from public YouTube videos called YTDEV18 and the publicly available LRS3-TED set. To highlight the contribution of the visual modality, we also evaluated the performance of our system on the YTDEV18 set artificially corrupted with background noise and overlapping speech. To the best of our knowledge, our system significantly improves the state-of-the-art on the LRS3-TED set.