 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Multi-Person Audio/Visual Automatic Speech Recognition
Paper and Code
May 11, 2022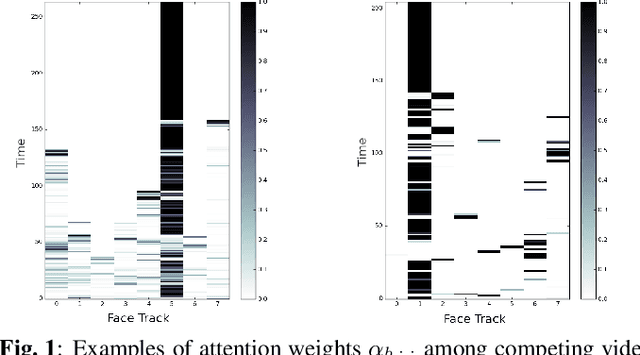

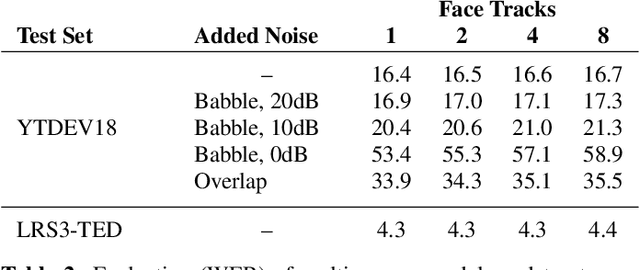
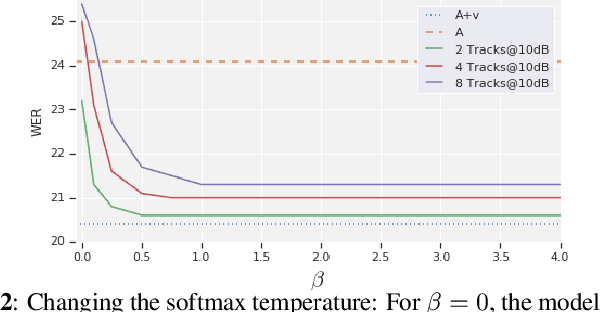
Traditionally, audio-visual automatic speech recognition has been studied under the assumption that the speaking face on the visual signal is the face matching the audio. However, in a more realistic setting, when multiple faces are potentially on screen one needs to decide which face to feed to the A/V ASR system. The present work takes the recent progress of A/V ASR one step further and considers the scenario where multiple people are simultaneously on screen (multi-person A/V ASR). We propose a fully differentiable A/V ASR model that is able to handle multiple face tracks in a video. Instead of relying on two separate models for speaker face selection and audio-visual ASR on a single face track, we introduce an attention layer to the ASR encoder that is able to soft-select the appropriate face video track. Experiments carried out on an A/V system trained on over 30k hours of YouTube videos illustrate that the proposed approach can automatically select the proper face tracks with minor WER degradation compared to an oracle selection of the speaking face while still showing benefits of employing the visual signal instead of the audio alone.