 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Speech Recognition is Worth 32$\times$32$\times$8 Voxels
Paper and Code
Sep 20, 2021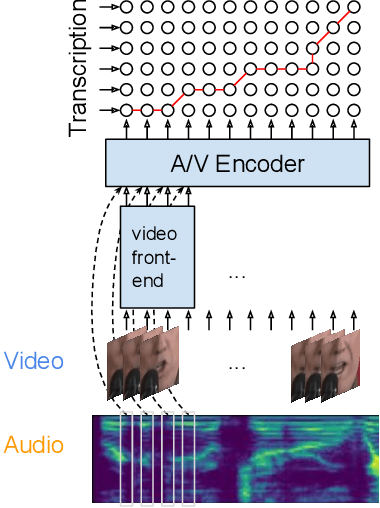


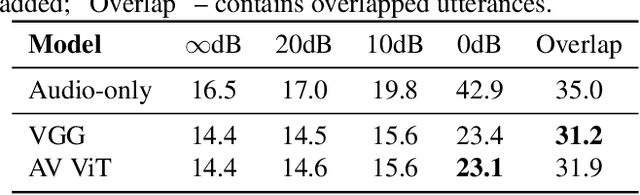
Audio-visual automatic speech recognition (AV-ASR) introduces the video modality into the speech recognition process, often by relying on information conveyed by the motion of the speaker's mouth. The use of the video signal requires extracting visual features, which are then combined with the acoustic features to build an AV-ASR system [1]. This is traditionally done with some form of 3D convolutional network (e.g. VGG) as widely used in the computer vision community. Recently, image transformers [2] have been introduced to extract visual features useful for image classification tasks. In this work, we propose to replace the 3D convolutional visual front-end with a video transformer front-end. We train our systems on a large-scale dataset composed of YouTube videos and evaluate performance on the publicly available LRS3-TED set, as well as on a large set of YouTube videos. On a lip-reading task, the transformer-based front-end shows superior performance compared to a strong convolutional baseline. On an AV-ASR task, the transformer front-end performs as well as (or better than) the convolutional baseline. Fine-tuning our model on the LRS3-TED training set matches previous state of the art. Thus, we experimentally show the viability of the convolution-free model for AV-ASR.