 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Costs of Reproducibility in Music Separation Research: a Replication of Band-Split RNN
Mar 10, 2026Music source separation is the task of isolating the instrumental tracks from a music song. Despite its spectacular recent progress, the trend towards more complex architectures and training protocols exacerbates reproducibility issues. The band-split recurrent neural networks (BSRNN) model is promising in this regard, since it yields close to state-of-the-art results on public datasets, and requires reasonable resources for training. Unfortunately, it is not straightforward to reproduce since its full code is not available. In this paper, we attempt to replicate BSRNN as closely as possible to the original paper through extensive experiments, which allows us to conduct a critical reflection on this reproducibility issue. Our contributions are three-fold. First, this study yields several insights on the model design and training pipeline, which sheds light on potential future improvements. In particular, since we were unsuccessful in reproducing the original results, we explore additional variants that ultimately yield an optimized BSRNN model, whose performance largely improves that of the original. Second, we discuss reproducibility issues from both methodological and practical perspectives. We notably underline how substantial time and energy costs could have been saved upon availability of the full pipeline. Third, our code and pre-trained models are released publicly to foster reproducible research. We hope that this study will contribute to spread awareness on the importance of reproducible research in the music separation community, and help promoting more transparent and sustainable practices.
A Phoneme-Scale Assessment of Multichannel Speech Enhancement Algorithms
Jan 24, 2024


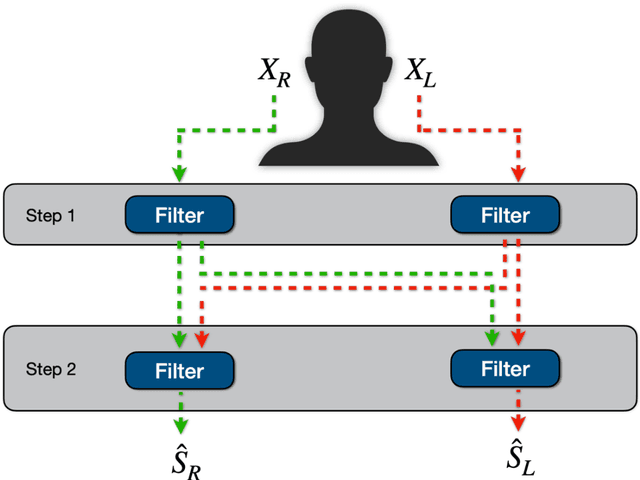
In the intricate acoustic landscapes where speech intelligibility is challenged by noise and reverberation, multichannel speech enhancement emerges as a promising solution for individuals with hearing loss. Such algorithms are commonly evaluated at the utterance level. However, this approach overlooks the granular acoustic nuances revealed by phoneme-specific analysis, potentially obscuring key insights into their performance. This paper presents an in-depth phoneme-scale evaluation of 3 state-of-the-art multichannel speech enhancement algorithms. These algorithms -- FasNet, MVDR, and Tango -- are extensively evaluated across different noise conditions and spatial setups, employing realistic acoustic simulations with measured room impulse responses, and leveraging diversity offered by multiple microphones in a binaural hearing setup. The study emphasizes the fine-grained phoneme-level analysis, revealing that while some phonemes like plosives are heavily impacted by environmental acoustics and challenging to deal with by the algorithms, others like nasals and sibilants see substantial improvements after enhancement. These investigations demonstrate important improvements in phoneme clarity in noisy conditions, with insights that could drive the development of more personalized and phoneme-aware hearing aid technologies.
Spectrogram Inversion for Audio Source Separation via Consistency, Mixing, and Magnitude Constraints
Mar 03, 2023Audio source separation is often achieved by estimating the magnitude spectrogram of each source, and then applying a phase recovery (or spectrogram inversion) algorithm to retrieve time-domain signals. Typically, spectrogram inversion is treated as an optimization problem involving one or several terms in order to promote estimates that comply with a consistency property, a mixing constraint, and/or a target magnitude objective. Nonetheless, it is still unclear which set of constraints and problem formulation is the most appropriate in practice. In this paper, we design a general framework for deriving spectrogram inversion algorithm, which is based on formulating optimization problems by combining these objectives either as soft penalties or hard constraints. We solve these by means of algorithms that perform alternating projections on the subsets corresponding to each objective/constraint. Our framework encompasses existing techniques from the literature as well as novel algorithms. We investigate the potential of these approaches for a speech enhancement task. In particular, one of our novel algorithms outperforms other approaches in a realistic setting where the magnitudes are estimated beforehand using a neural network.
Signal inpainting from Fourier magnitudes
Oct 28, 2022Signal inpainting is the task of restoring degraded or missing samples in a signal. In this paper we address signal inpainting when Fourier magnitudes are observed. We propose a mathematical formulation of the problem that highlights its connection with phase retrieval, and we introduce two methods for solving it. First, we derive an alternating minimization scheme, which shares similarities with the Gerchberg-Saxton algorithm, a classical phase retrieval method. Second, we propose a convex relaxation of the problem, which is inspired by recent approaches that reformulate phase retrieval into a semidefinite program. We assess the potential of these methods for the task of inpainting gaps in speech signals. Our methods exhibit both a high probability of recovering the original signals and robustness to magnitude noise.
Algorithms for audio inpainting based on probabilistic nonnegative matrix factorization
Jun 28, 2022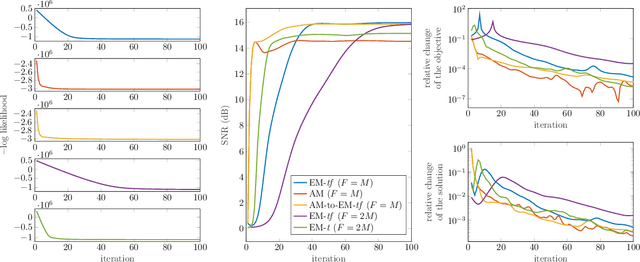

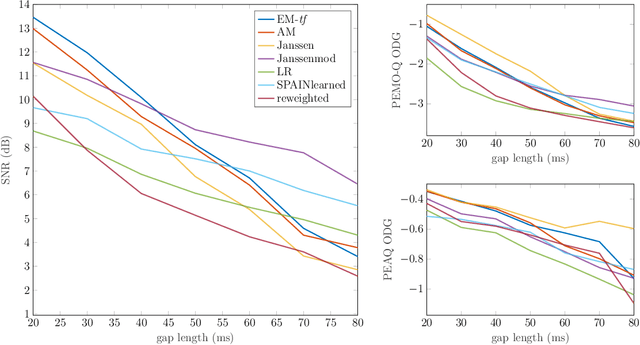
Audio inpainting, i.e., the task of restoring missing or occluded audio signal samples, usually relies on sparse representations or autoregressive modeling. In this paper, we propose to structure the spectrogram with nonnegative matrix factorization (NMF) in a probabilistic framework. First, we treat the missing samples as latent variables, and derive two expectation-maximization algorithms for estimating the parameters of the model, depending on whether we formulate the problem in the time- or time-frequency domain. Then, we treat the missing samples as parameters, and we address this novel problem by deriving an alternating minimization scheme. We assess the potential of these algorithms for the task of restoring short- to middle-length gaps in music signals. Experiments reveal great convergence properties of the proposed methods, as well as competitive performance when compared to state-of-the-art audio inpainting techniques.
A majorization-minimization algorithm for nonnegative binary matrix factorization
Apr 20, 2022
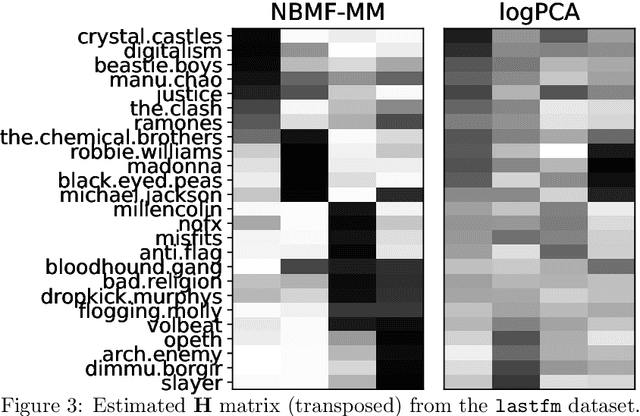
This paper tackles the problem of decomposing binary data using matrix factorization. We consider the family of mean-parametrized Bernoulli models, a class of generative models that are well suited for modeling binary data and enables interpretability of the factors. We factorize the Bernoulli parameter and consider an additional Beta prior on one of the factors to further improve the model's expressive power. While similar models have been proposed in the literature, they only exploit the Beta prior as a proxy to ensure a valid Bernoulli parameter in a Bayesian setting; in practice it reduces to a uniform or uninformative prior. Besides, estimation in these models has focused on costly Bayesian inference. In this paper, we propose a simple yet very efficient majorization-minimization algorithm for maximum a posteriori estimation. Our approach leverages the Beta prior whose parameters can be tuned to improve performance in matrix completion tasks. Experiments conducted on three public binary datasets show that our approach offers an excellent trade-off between prediction performance, computational complexity, and interpretability.
Learning the Proximity Operator in Unfolded ADMM for Phase Retrieval
Apr 04, 2022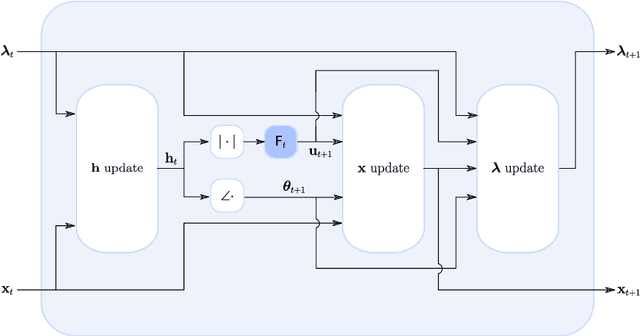
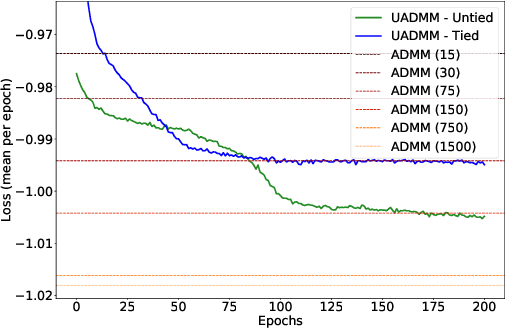
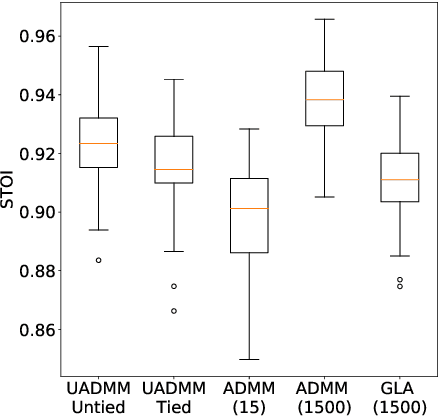
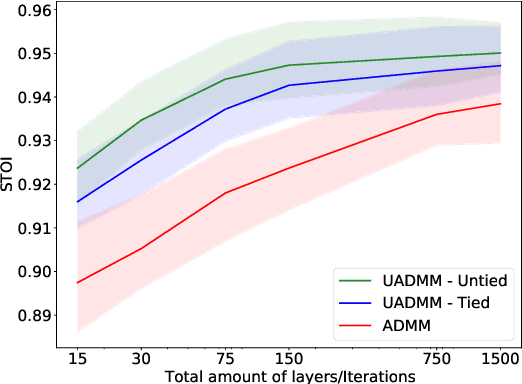
This paper considers the phase retrieval (PR) problem, which aims to reconstruct a signal from phaseless measurements such as magnitude or power spectrograms. PR is generally handled as a minimization problem involving a quadratic loss. Recent works have considered alternative discrepancy measures, such as the Bregman divergences, but it is still challenging to tailor the optimal loss for a given setting. In this paper we propose a novel strategy to automatically learn the optimal metric for PR. We unfold a recently introduced ADMM algorithm into a neural network, and we emphasize that the information about the loss used to formulate the PR problem is conveyed by the proximity operator involved in the ADMM updates. Therefore, we replace this proximity operator with trainable activation functions: learning these in a supervised setting is then equivalent to learning an optimal metric for PR. Experiments conducted with speech signals show that our approach outperforms the baseline ADMM, using a light and interpretable neural architecture.
A Sparsity-promoting Dictionary Model for Variational Autoencoders
Mar 29, 2022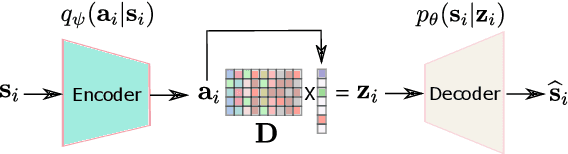

Structuring the latent space in probabilistic deep generative models, e.g., variational autoencoders (VAEs), is important to yield more expressive models and interpretable representations, and to avoid overfitting. One way to achieve this objective is to impose a sparsity constraint on the latent variables, e.g., via a Laplace prior. However, such approaches usually complicate the training phase, and they sacrifice the reconstruction quality to promote sparsity. In this paper, we propose a simple yet effective methodology to structure the latent space via a sparsity-promoting dictionary model, which assumes that each latent code can be written as a sparse linear combination of a dictionary's columns. In particular, we leverage a computationally efficient and tuning-free method, which relies on a zero-mean Gaussian latent prior with learnable variances. We derive a variational inference scheme to train the model. Experiments on speech generative modeling demonstrate the advantage of the proposed approach over competing techniques, since it promotes sparsity while not deteriorating the output speech quality.
Neural content-aware collaborative filtering for cold-start music recommendation
Feb 24, 2021

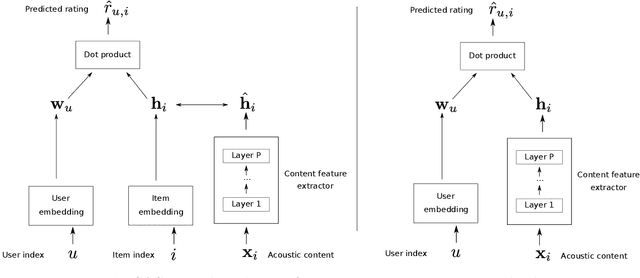
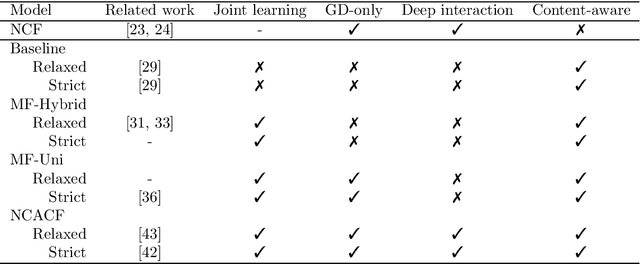
State-of-the-art music recommender systems are based on collaborative filtering, which builds upon learning similarities between users and songs from the available listening data. These approaches inherently face the cold-start problem, as they cannot recommend novel songs with no listening history. Content-aware recommendation addresses this issue by incorporating content information about the songs on top of collaborative filtering. However, methods falling in this category rely on a shallow user/item interaction that originates from a matrix factorization framework. In this work, we introduce neural content-aware collaborative filtering, a unified framework which alleviates these limits, and extends the recently introduced neural collaborative filtering to its content-aware counterpart. We propose a generative model which leverages deep learning for both extracting content information from low-level acoustic features and for modeling the interaction between users and songs embeddings. The deep content feature extractor can either directly predict the item embedding, or serve as a regularization prior, yielding two variants (strict and relaxed) of our model. Experimental results show that the proposed method reaches state-of-the-art results for a cold-start music recommendation task. We notably observe that exploiting deep neural networks for learning refined user/item interactions outperforms approaches using a more simple interaction model in a content-aware framework.
Language Modelling for Sound Event Detection with Teacher Forcing and Scheduled Sampling
Jul 22, 2019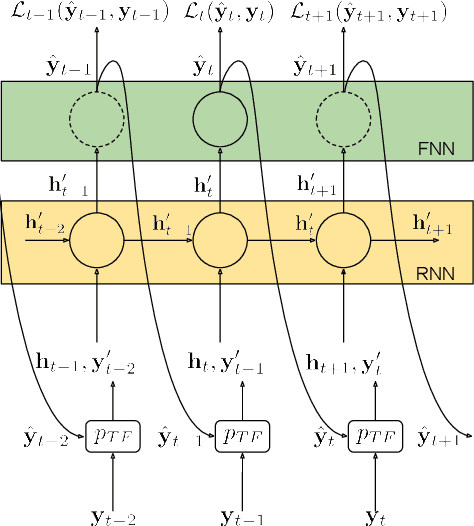
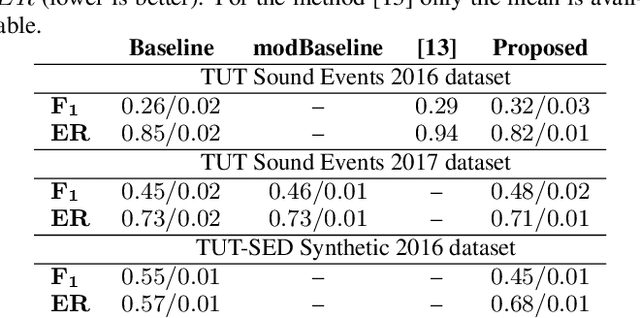
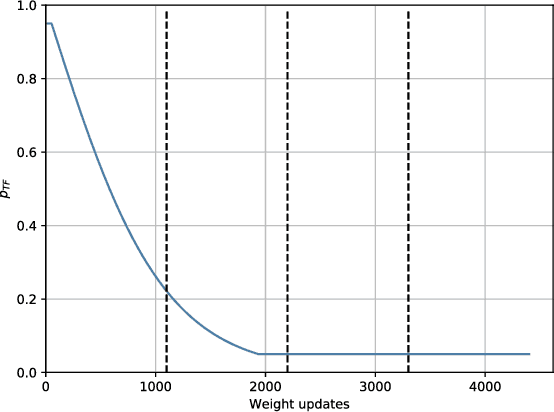
A sound event detection (SED) method typically takes as an input a sequence of audio frames and predicts the activities of sound events in each frame. In real-life recordings, the sound events exhibit some temporal structure: for instance, a "car horn" will likely be followed by a "car passing by". While this temporal structure is widely exploited in sequence prediction tasks (e.g., in machine translation), where language models (LM) are exploited, it is not satisfactorily modeled in SED. In this work we propose a method which allows a recurrent neural network (RNN) to learn an LM for the SED task. The method conditions the input of the RNN with the activities of classes at the previous time step. We evaluate our method using F1 score and error rate (ER) over three different and publicly available datasets; the TUT-SED Synthetic 2016 and the TUT Sound Events 2016 and 2017 datasets. The obtained results show an increase of 6% and 3% at the F1 (higher is better) and a decrease of 3% and 2% at ER (lower is better) for the TUT Sound Events 2016 and 2017 datasets, respectively, when using our method. On the contrary, with our method there is a decrease of 10% at F1 score and an increase of 11% at ER for the TUT-SED Synthetic 2016 dataset.