 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRODIS -- a speech database and a phoneme-based language model for the study of predictability effects in Polish
Apr 15, 2024We present a speech database and a phoneme-level language model of Polish. The database and model are designed for the analysis of prosodic and discourse factors and their impact on acoustic parameters in interaction with predictability effects. The database is also the first large, publicly available Polish speech corpus of excellent acoustic quality that can be used for phonetic analysis and training of multi-speaker speech technology systems. The speech in the database is processed in a pipeline that achieves a 90% degree of automation. It incorporates state-of-the-art, freely available tools enabling database expansion or adaptation to additional languages.
Recovering implicit pitch contours from formants in whispered speech
Jul 06, 2023Whispered speech is characterised by a noise-like excitation that results in the lack of fundamental frequency. Considering that prosodic phenomena such as intonation are perceived through f0 variation, the perception of whispered prosody is relatively difficult. At the same time, studies have shown that speakers do attempt to produce intonation when whispering and that prosodic variability is being transmitted, suggesting that intonation "survives" in whispered formant structure. In this paper, we aim to estimate the way in which formant contours correlate with an "implicit" pitch contour in whisper, using a machine learning model. We propose a two-step method: using a parallel corpus, we first transform the whispered formants into their phonated equivalents using a denoising autoencoder. We then analyse the formant contours to predict phonated pitch contour variation. We observe that our method is effective in establishing a relationship between whispered and phonated formants and in uncovering implicit pitch contours in whisper.
Speaker-independent neural formant synthesis
Jun 02, 2023We describe speaker-independent speech synthesis driven by a small set of phonetically meaningful speech parameters such as formant frequencies. The intention is to leverage deep-learning advances to provide a highly realistic signal generator that includes control affordances required for stimulus creation in the speech sciences. Our approach turns input speech parameters into predicted mel-spectrograms, which are rendered into waveforms by a pre-trained neural vocoder. Experiments with WaveNet and HiFi-GAN confirm that the method achieves our goals of accurate control over speech parameters combined with high perceptual audio quality. We also find that the small set of phonetically relevant speech parameters we use is sufficient to allow for speaker-independent synthesis (a.k.a. universal vocoding).
A processing framework to access large quantities of whispered speech found in ASMR
Mar 13, 2023Whispering is a ubiquitous mode of communication that humans use daily. Despite this, whispered speech has been poorly served by existing speech technology due to a shortage of resources and processing methodology. To remedy this, this paper provides a processing framework that enables access to large and unique data of high-quality whispered speech. We obtain the data from recordings submitted to online platforms as part of the ASMR media-cultural phenomenon. We describe our processing pipeline and a method for improved whispered activity detection (WAD) in the ASMR data. To efficiently obtain labelled, clean whispered speech, we complement the automatic WAD by using Edyson, a bulk audio-annotation tool with human-in-the-loop. We also tackle a problem particular to ASMR: separation of whisper from other acoustic triggers present in the genre. We show that the proposed WAD and the efficient labelling allows to build extensively augmented data and train a classifier that extracts clean whisper segments from ASMR audio. Our large and growing dataset enables whisper-capable, data-driven speech technology and linguistic analysis. It also opens opportunities in e.g. HCI as a resource that may elicit emotional, psychological and neuro-physiological responses in the listener.
Wavebender GAN: An architecture for phonetically meaningful speech manipulation
Feb 22, 2022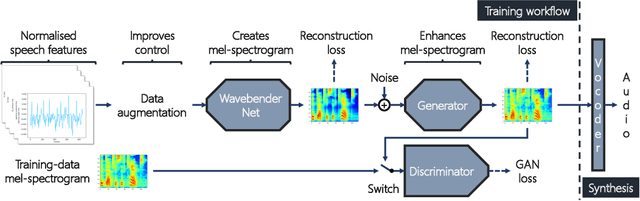
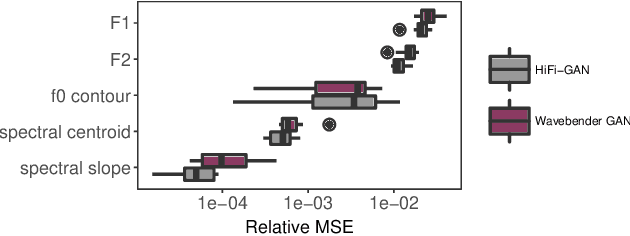
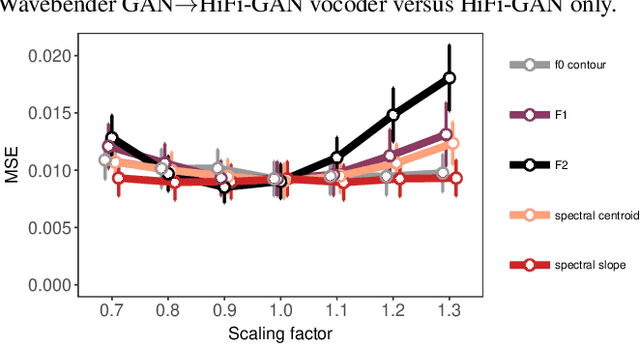
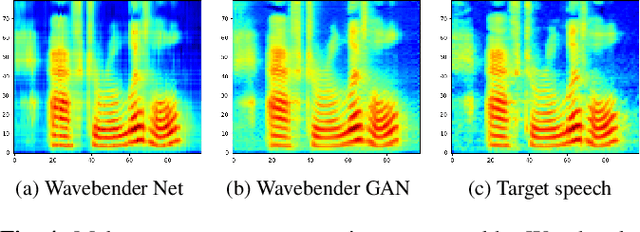
Deep learning has revolutionised synthetic speech quality. However, it has thus far delivered little value to the speech science community. The new methods do not meet the controllability demands that practitioners in this area require e.g.: in listening tests with manipulated speech stimuli. Instead, control of different speech properties in such stimuli is achieved by using legacy signal-processing methods. This limits the range, accuracy, and speech quality of the manipulations. Also, audible artefacts have a negative impact on the methodological validity of results in speech perception studies. This work introduces a system capable of manipulating speech properties through learning rather than design. The architecture learns to control arbitrary speech properties and leverages progress in neural vocoders to obtain realistic output. Experiments with copy synthesis and manipulation of a small set of core speech features (pitch, formants, and voice quality measures) illustrate the promise of the approach for producing speech stimuli that have accurate control and high perceptual quality.