 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavebender GAN: An architecture for phonetically meaningful speech manipulation
Feb 22, 2022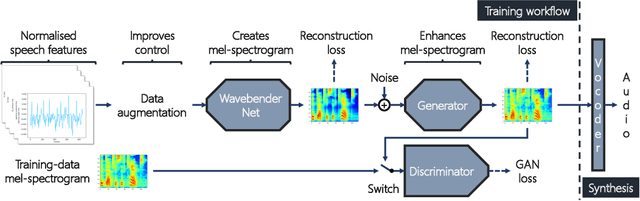
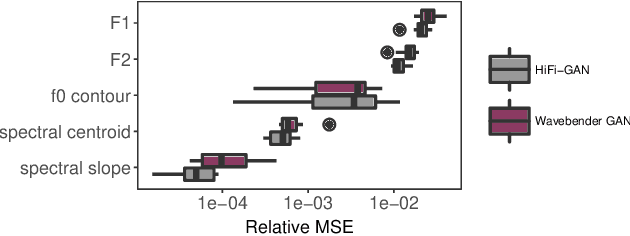
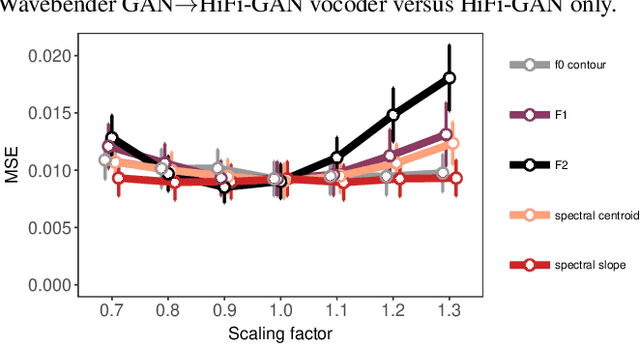
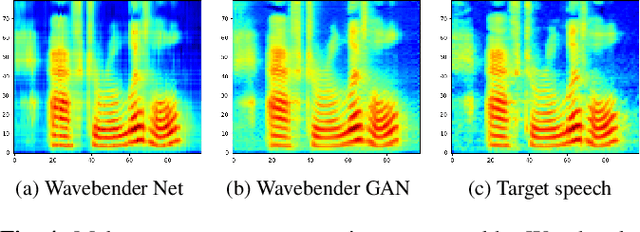
Deep learning has revolutionised synthetic speech quality. However, it has thus far delivered little value to the speech science community. The new methods do not meet the controllability demands that practitioners in this area require e.g.: in listening tests with manipulated speech stimuli. Instead, control of different speech properties in such stimuli is achieved by using legacy signal-processing methods. This limits the range, accuracy, and speech quality of the manipulations. Also, audible artefacts have a negative impact on the methodological validity of results in speech perception studies. This work introduces a system capable of manipulating speech properties through learning rather than design. The architecture learns to control arbitrary speech properties and leverages progress in neural vocoders to obtain realistic output. Experiments with copy synthesis and manipulation of a small set of core speech features (pitch, formants, and voice quality measures) illustrate the promise of the approach for producing speech stimuli that have accurate control and high perceptual quality.