 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Steering Deep Non-Linear Spatially Selective Filters for Efficient Extraction of Moving Speakers under Weak Guidance
Jul 03, 2025Recent works on deep non-linear spatially selective filters demonstrate exceptional enhancement performance with computationally lightweight architectures for stationary speakers of known directions. However, to maintain this performance in dynamic scenarios, resource-intensive data-driven tracking algorithms become necessary to provide precise spatial guidance conditioned on the initial direction of a target speaker. As this additional computational overhead hinders application in resource-constrained scenarios such as real-time speech enhancement, we present a novel strategy utilizing a low-complexity tracking algorithm in the form of a particle filter instead. Assuming a causal, sequential processing style, we introduce temporal feedback to leverage the enhanced speech signal of the spatially selective filter to compensate for the limited modeling capabilities of the particle filter. Evaluation on a synthetic dataset illustrates how the autoregressive interplay between both algorithms drastically improves tracking accuracy and leads to strong enhancement performance. A listening test with real-world recordings complements these findings by indicating a clear trend towards our proposed self-steering pipeline as preferred choice over comparable methods.
Integrating Uncertainty into Neural Network-based Speech Enhancement
May 15, 2023Supervised masking approaches in the time-frequency domain aim to employ deep neural networks to estimate a multiplicative mask to extract clean speech. This leads to a single estimate for each input without any guarantees or measures of reliability. In this paper, we study the benefits of modeling uncertainty in clean speech estimation. Prediction uncertainty is typically categorized into aleatoric uncertainty and epistemic uncertainty. The former refers to inherent randomness in data, while the latter describes uncertainty in the model parameters. In this work, we propose a framework to jointly model aleatoric and epistemic uncertainties in neural network-based speech enhancement. The proposed approach captures aleatoric uncertainty by estimating the statistical moments of the speech posterior distribution and explicitly incorporates the uncertainty estimate to further improve clean speech estimation. For epistemic uncertainty, we investigate two Bayesian deep learning approaches: Monte Carlo dropout and Deep ensembles to quantify the uncertainty of the neural network parameters. Our analyses show that the proposed framework promotes capturing practical and reliable uncertainty, while combining different sources of uncertainties yields more reliable predictive uncertainty estimates. Furthermore, we demonstrate the benefits of modeling uncertainty on speech enhancement performance by evaluating the framework on different datasets, exhibiting notable improvement over comparable models that fail to account for uncertainty.
* Accepted version
Partially Adaptive Multichannel Joint Reduction of Ego-noise and Environmental Noise
Mar 27, 2023Human-robot interaction relies on a noise-robust audio processing module capable of estimating target speech from audio recordings impacted by environmental noise, as well as self-induced noise, so-called ego-noise. While external ambient noise sources vary from environment to environment, ego-noise is mainly caused by the internal motors and joints of a robot. Ego-noise and environmental noise reduction are often decoupled, i.e., ego-noise reduction is performed without considering environmental noise. Recently, a variational autoencoder (VAE)-based speech model has been combined with a fully adaptive non-negative matrix factorization (NMF) noise model to recover clean speech under different environmental noise disturbances. However, its enhancement performance is limited in adverse acoustic scenarios involving, e.g. ego-noise. In this paper, we propose a multichannel partially adaptive scheme to jointly model ego-noise and environmental noise utilizing the VAE-NMF framework, where we take advantage of spatially and spectrally structured characteristics of ego-noise by pre-training the ego-noise model, while retaining the ability to adapt to unknown environmental noise. Experimental results show that our proposed approach outperforms the methods based on a completely fixed scheme and a fully adaptive scheme when ego-noise and environmental noise are present simultaneously.
* Accepted to the 2023 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2023)
Uncertainty Estimation in Deep Speech Enhancement Using Complex Gaussian Mixture Models
Dec 09, 2022Single-channel deep speech enhancement approaches often estimate a single multiplicative mask to extract clean speech without a measure of its accuracy. Instead, in this work, we propose to quantify the uncertainty associated with clean speech estimates in neural network-based speech enhancement. Predictive uncertainty is typically categorized into aleatoric uncertainty and epistemic uncertainty. The former accounts for the inherent uncertainty in data and the latter corresponds to the model uncertainty. Aiming for robust clean speech estimation and efficient predictive uncertainty quantification, we propose to integrate statistical complex Gaussian mixture models (CGMMs) into a deep speech enhancement framework. More specifically, we model the dependency between input and output stochastically by means of a conditional probability density and train a neural network to map the noisy input to the full posterior distribution of clean speech, modeled as a mixture of multiple complex Gaussian components. Experimental results on different datasets show that the proposed algorithm effectively captures predictive uncertainty and that combining powerful statistical models and deep learning also delivers a superior speech enhancement performance.
Integrating Statistical Uncertainty into Neural Network-Based Speech Enhancement
Mar 04, 2022



Speech enhancement in the time-frequency domain is often performed by estimating a multiplicative mask to extract clean speech. However, most neural network-based methods perform point estimation, i.e., their output consists of a single mask. In this paper, we study the benefits of modeling uncertainty in neural network-based speech enhancement. For this, our neural network is trained to map a noisy spectrogram to the Wiener filter and its associated variance, which quantifies uncertainty, based on the maximum a posteriori (MAP) inference of spectral coefficients. By estimating the distribution instead of the point estimate, one can model the uncertainty associated with each estimate. We further propose to use the estimated Wiener filter and its uncertainty to build an approximate MAP (A-MAP) estimator of spectral magnitudes, which in turn is combined with the MAP inference of spectral coefficients to form a hybrid loss function to jointly reinforce the estimation. Experimental results on different datasets show that the proposed method can not only capture the uncertainty associated with the estimated filters, but also yield a higher enhancement performance over comparable models that do not take uncertainty into account.
* \copyright 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Variational Autoencoder for Speech Enhancement with a Noise-Aware Encoder
Feb 17, 2021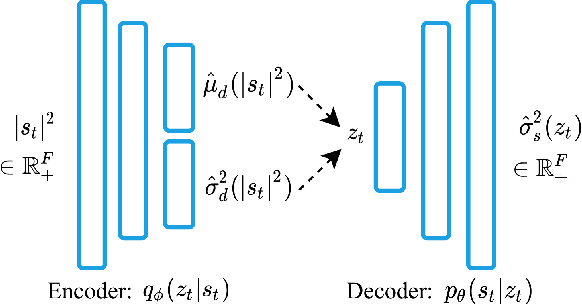

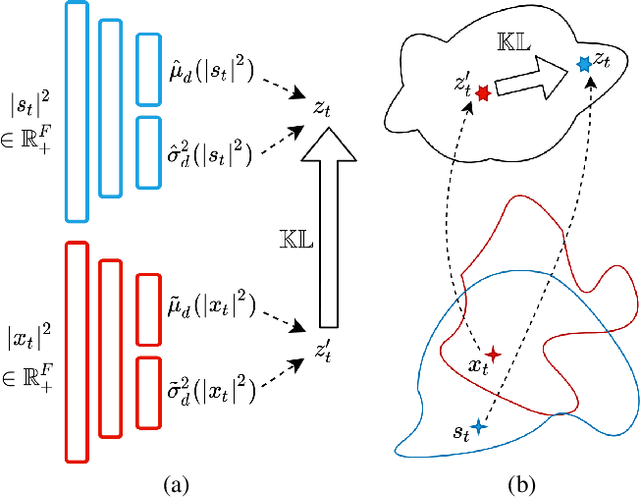

Recently, a generative variational autoencoder (VAE) has been proposed for speech enhancement to model speech statistics. However, this approach only uses clean speech in the training phase, making the estimation particularly sensitive to noise presence, especially in low signal-to-noise ratios (SNRs). To increase the robustness of the VAE, we propose to include noise information in the training phase by using a noise-aware encoder trained on noisy-clean speech pairs. We evaluate our approach on real recordings of different noisy environments and acoustic conditions using two different noise datasets. We show that our proposed noise-aware VAE outperforms the standard VAE in terms of overall distortion without increasing the number of model parameters. At the same time, we demonstrate that our model is capable of generalizing to unseen noise conditions better than a supervised feedforward deep neural network (DNN). Furthermore, we demonstrate the robustness of the model performance to a reduction of the noisy-clean speech training data size.