 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBring the Noise: Introducing Noise Robustness to Pretrained Automatic Speech Recognition
Sep 05, 2023



In recent research, in the domain of speech processing, large End-to-End (E2E) systems for Automatic Speech Recognition (ASR) have reported state-of-the-art performance on various benchmarks. These systems intrinsically learn how to handle and remove noise conditions from speech. Previous research has shown, that it is possible to extract the denoising capabilities of these models into a preprocessor network, which can be used as a frontend for downstream ASR models. However, the proposed methods were limited to specific fully convolutional architectures. In this work, we propose a novel method to extract the denoising capabilities, that can be applied to any encoder-decoder architecture. We propose the Cleancoder preprocessor architecture that extracts hidden activations from the Conformer ASR model and feeds them to a decoder to predict denoised spectrograms. We train our pre-processor on the Noisy Speech Database (NSD) to reconstruct denoised spectrograms from noisy inputs. Then, we evaluate our model as a frontend to a pretrained Conformer ASR model as well as a frontend to train smaller Conformer ASR models from scratch. We show that the Cleancoder is able to filter noise from speech and that it improves the total Word Error Rate (WER) of the downstream model in noisy conditions for both applications.
Partially Adaptive Multichannel Joint Reduction of Ego-noise and Environmental Noise
Mar 27, 2023Human-robot interaction relies on a noise-robust audio processing module capable of estimating target speech from audio recordings impacted by environmental noise, as well as self-induced noise, so-called ego-noise. While external ambient noise sources vary from environment to environment, ego-noise is mainly caused by the internal motors and joints of a robot. Ego-noise and environmental noise reduction are often decoupled, i.e., ego-noise reduction is performed without considering environmental noise. Recently, a variational autoencoder (VAE)-based speech model has been combined with a fully adaptive non-negative matrix factorization (NMF) noise model to recover clean speech under different environmental noise disturbances. However, its enhancement performance is limited in adverse acoustic scenarios involving, e.g. ego-noise. In this paper, we propose a multichannel partially adaptive scheme to jointly model ego-noise and environmental noise utilizing the VAE-NMF framework, where we take advantage of spatially and spectrally structured characteristics of ego-noise by pre-training the ego-noise model, while retaining the ability to adapt to unknown environmental noise. Experimental results show that our proposed approach outperforms the methods based on a completely fixed scheme and a fully adaptive scheme when ego-noise and environmental noise are present simultaneously.
* Accepted to the 2023 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2023)
Semi-Supervised Phoneme Recognition with Recurrent Ladder Networks
Sep 18, 2017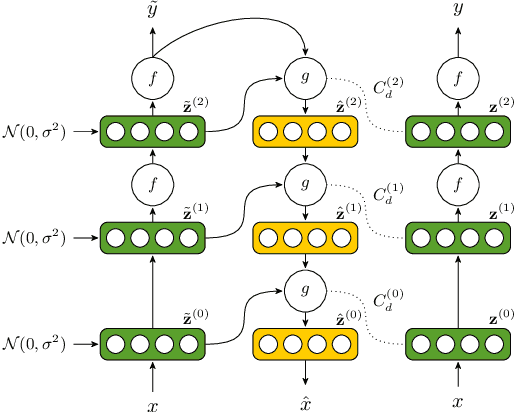
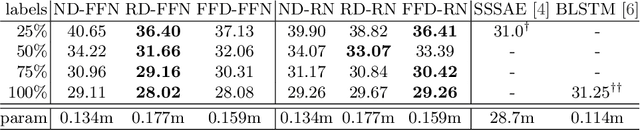
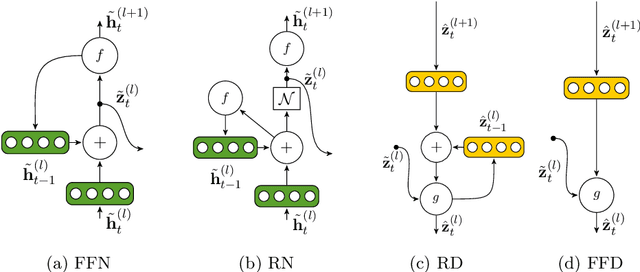
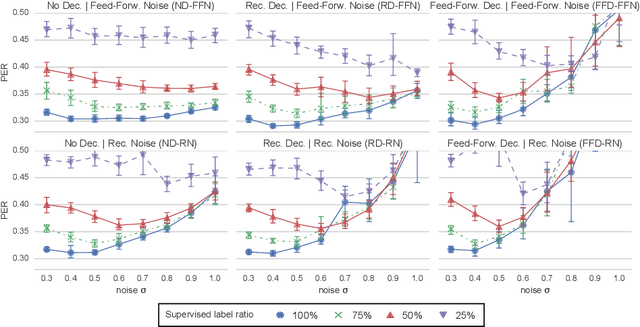
Ladder networks are a notable new concept in the field of semi-supervised learning by showing state-of-the-art results in image recognition tasks while being compatible with many existing neural architectures. We present the recurrent ladder network, a novel modification of the ladder network, for semi-supervised learning of recurrent neural networks which we evaluate with a phoneme recognition task on the TIMIT corpus. Our results show that the model is able to consistently outperform the baseline and achieve fully-supervised baseline performance with only 75% of all labels which demonstrates that the model is capable of using unsupervised data as an effective regulariser.