 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalking to Robots: A Practical Examination of Speech Foundation Models for HRI Applications
Aug 25, 2025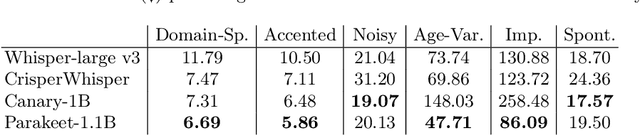
Automatic Speech Recognition (ASR) systems in real-world settings need to handle imperfect audio, often degraded by hardware limitations or environmental noise, while accommodating diverse user groups. In human-robot interaction (HRI), these challenges intersect to create a uniquely challenging recognition environment. We evaluate four state-of-the-art ASR systems on eight publicly available datasets that capture six dimensions of difficulty: domain-specific, accented, noisy, age-variant, impaired, and spontaneous speech. Our analysis demonstrates significant variations in performance, hallucination tendencies, and inherent biases, despite similar scores on standard benchmarks. These limitations have serious implications for HRI, where recognition errors can interfere with task performance, user trust, and safety.
Large Language Model Data Generation for Enhanced Intent Recognition in German Speech
Aug 08, 2025Intent recognition (IR) for speech commands is essential for artificial intelligence (AI) assistant systems; however, most existing approaches are limited to short commands and are predominantly developed for English. This paper addresses these limitations by focusing on IR from speech by elderly German speakers. We propose a novel approach that combines an adapted Whisper ASR model, fine-tuned on elderly German speech (SVC-de), with Transformer-based language models trained on synthetic text datasets generated by three well-known large language models (LLMs): LeoLM, Llama3, and ChatGPT. To evaluate the robustness of our approach, we generate synthetic speech with a text-to-speech model and conduct extensive cross-dataset testing. Our results show that synthetic LLM-generated data significantly boosts classification performance and robustness to different speaking styles and unseen vocabulary. Notably, we find that LeoLM, a smaller, domain-specific 13B LLM, surpasses the much larger ChatGPT (175B) in dataset quality for German intent recognition. Our approach demonstrates that generative AI can effectively bridge data gaps in low-resource domains. We provide detailed documentation of our data generation and training process to ensure transparency and reproducibility.
A Framework for Adapting Human-Robot Interaction to Diverse User Groups
Oct 15, 2024



To facilitate natural and intuitive interactions with diverse user groups in real-world settings, social robots must be capable of addressing the varying requirements and expectations of these groups while adapting their behavior based on user feedback. While previous research often focuses on specific demographics, we present a novel framework for adaptive Human-Robot Interaction (HRI) that tailors interactions to different user groups and enables individual users to modulate interactions through both minor and major interruptions. Our primary contributions include the development of an adaptive, ROS-based HRI framework with an open-source code base. This framework supports natural interactions through advanced speech recognition and voice activity detection, and leverages a large language model (LLM) as a dialogue bridge. We validate the efficiency of our framework through module tests and system trials, demonstrating its high accuracy in age recognition and its robustness to repeated user inputs and plan changes.
Bring the Noise: Introducing Noise Robustness to Pretrained Automatic Speech Recognition
Sep 05, 2023



In recent research, in the domain of speech processing, large End-to-End (E2E) systems for Automatic Speech Recognition (ASR) have reported state-of-the-art performance on various benchmarks. These systems intrinsically learn how to handle and remove noise conditions from speech. Previous research has shown, that it is possible to extract the denoising capabilities of these models into a preprocessor network, which can be used as a frontend for downstream ASR models. However, the proposed methods were limited to specific fully convolutional architectures. In this work, we propose a novel method to extract the denoising capabilities, that can be applied to any encoder-decoder architecture. We propose the Cleancoder preprocessor architecture that extracts hidden activations from the Conformer ASR model and feeds them to a decoder to predict denoised spectrograms. We train our pre-processor on the Noisy Speech Database (NSD) to reconstruct denoised spectrograms from noisy inputs. Then, we evaluate our model as a frontend to a pretrained Conformer ASR model as well as a frontend to train smaller Conformer ASR models from scratch. We show that the Cleancoder is able to filter noise from speech and that it improves the total Word Error Rate (WER) of the downstream model in noisy conditions for both applications.
Replay to Remember: Continual Layer-Specific Fine-tuning for German Speech Recognition
Jul 14, 2023While Automatic Speech Recognition (ASR) models have shown significant advances with the introduction of unsupervised or self-supervised training techniques, these improvements are still only limited to a subsection of languages and speakers. Transfer learning enables the adaptation of large-scale multilingual models to not only low-resource languages but also to more specific speaker groups. However, fine-tuning on data from new domains is usually accompanied by a decrease in performance on the original domain. Therefore, in our experiments, we examine how well the performance of large-scale ASR models can be approximated for smaller domains, with our own dataset of German Senior Voice Commands (SVC-de), and how much of the general speech recognition performance can be preserved by selectively freezing parts of the model during training. To further increase the robustness of the ASR model to vocabulary and speakers outside of the fine-tuned domain, we apply Experience Replay for continual learning. By adding only a fraction of data from the original domain, we are able to reach Word-Error-Rates (WERs) below 5\% on the new domain, while stabilizing performance for general speech recognition at acceptable WERs.