 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end label uncertainty modeling for speech emotion recognition using Bayesian neural networks
Oct 07, 2021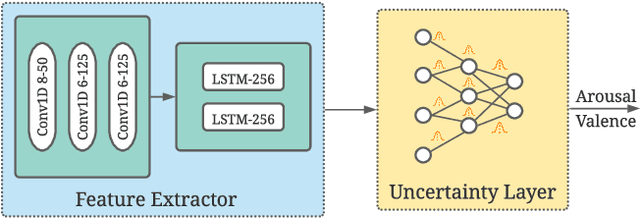
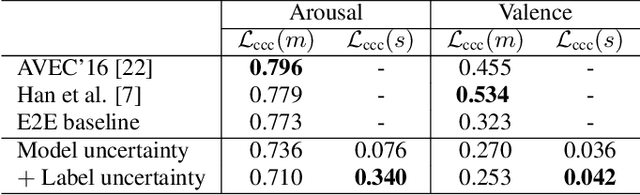

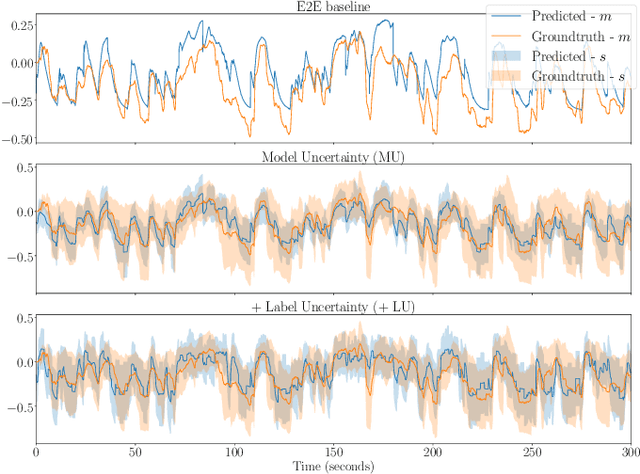
Emotions are subjective constructs. Recent end-to-end speech emotion recognition systems are typically agnostic to the subjective nature of emotions, despite their state-of-the-art performances. In this work, we introduce an end-to-end Bayesian neural network architecture to capture the inherent subjectivity in emotions. To the best of our knowledge, this work is the first to use Bayesian neural networks for speech emotion recognition. At training, the network learns a distribution of weights to capture the inherent uncertainty related to subjective emotion annotations. For this, we introduce a loss term which enables the model to be explicitly trained on a distribution of emotion annotations, rather than training them exclusively on mean or gold-standard labels. We evaluate the proposed approach on the AVEC'16 emotion recognition dataset. Qualitative and quantitative analysis of the results reveal that the proposed model can aptly capture the distribution of subjective emotion annotations with a compromise between mean and standard deviation estimations.
Disentanglement Learning for Variational Autoencoders Applied to Audio-Visual Speech Enhancement
May 19, 2021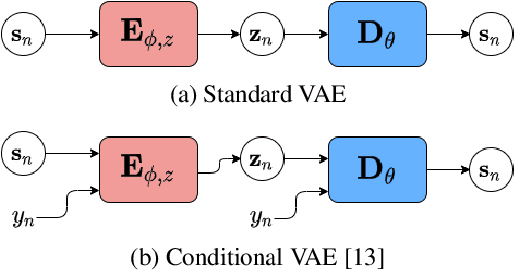

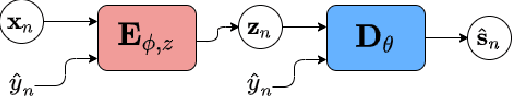
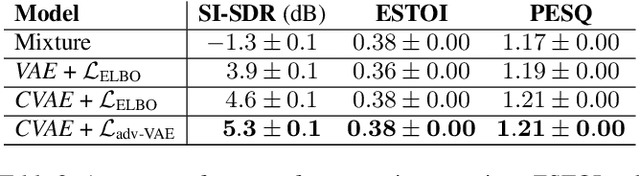
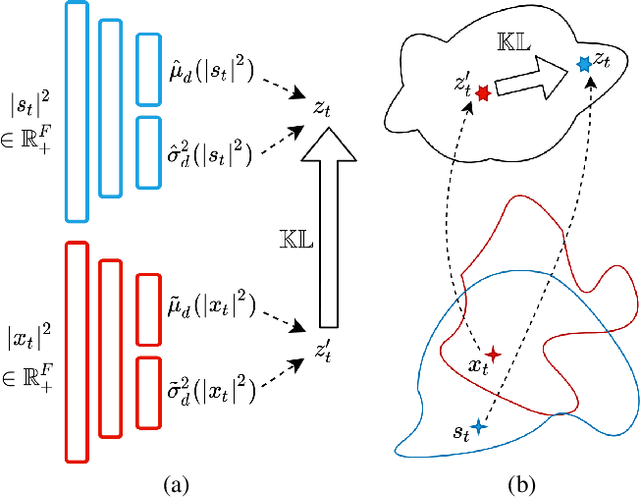
Recently, the standard variational autoencoder has been successfully used to learn a probabilistic prior over speech signals, which is then used to perform speech enhancement. Variational autoencoders have then been conditioned on a label describing a high-level speech attribute (e.g. speech activity) that allows for a more explicit control of speech generation. However, the label is not guaranteed to be disentangled from the other latent variables, which results in limited performance improvements compared to the standard variational autoencoder. In this work, we propose to use an adversarial training scheme for variational autoencoders to disentangle the label from the other latent variables. At training, we use a discriminator that competes with the encoder of the variational autoencoder. Simultaneously, we also use an additional encoder that estimates the label for the decoder of the variational autoencoder, which proves to be crucial to learn disentanglement. We show the benefit of the proposed disentanglement learning when a voice activity label, estimated from visual data, is used for speech enhancement.
Variational Autoencoder for Speech Enhancement with a Noise-Aware Encoder
Feb 17, 2021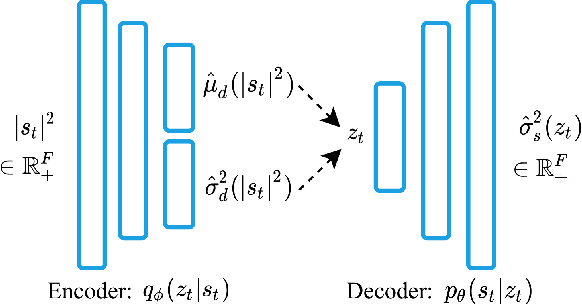


Recently, a generative variational autoencoder (VAE) has been proposed for speech enhancement to model speech statistics. However, this approach only uses clean speech in the training phase, making the estimation particularly sensitive to noise presence, especially in low signal-to-noise ratios (SNRs). To increase the robustness of the VAE, we propose to include noise information in the training phase by using a noise-aware encoder trained on noisy-clean speech pairs. We evaluate our approach on real recordings of different noisy environments and acoustic conditions using two different noise datasets. We show that our proposed noise-aware VAE outperforms the standard VAE in terms of overall distortion without increasing the number of model parameters. At the same time, we demonstrate that our model is capable of generalizing to unseen noise conditions better than a supervised feedforward deep neural network (DNN). Furthermore, we demonstrate the robustness of the model performance to a reduction of the noisy-clean speech training data size.
Guided Variational Autoencoder for Speech Enhancement With a Supervised Classifier
Feb 12, 2021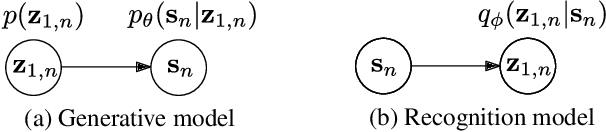
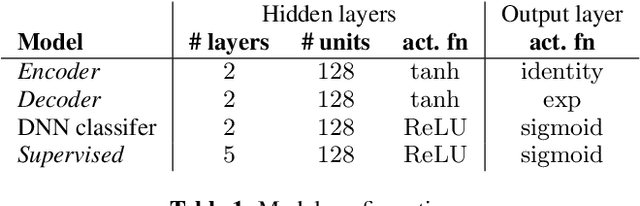
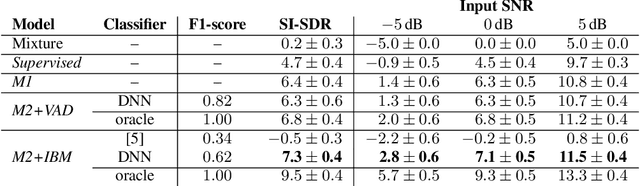
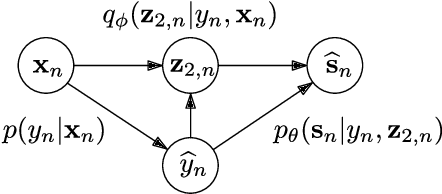
Recently, variational autoencoders have been successfully used to learn a probabilistic prior over speech signals, which is then used to perform speech enhancement. However, variational autoencoders are trained on clean speech only, which results in a limited ability of extracting the speech signal from noisy speech compared to supervised approaches. In this paper, we propose to guide the variational autoencoder with a supervised classifier separately trained on noisy speech. The estimated label is a high-level categorical variable describing the speech signal (e.g. speech activity) allowing for a more informed latent distribution compared to the standard variational autoencoder. We evaluate our method with different types of labels on real recordings of different noisy environments. Provided that the label better informs the latent distribution and that the classifier achieves good performance, the proposed approach outperforms the standard variational autoencoder and a conventional neural network-based supervised approach.
Joint DNN-Based Multichannel Reduction of Acoustic Echo, Reverberation and Noise
Dec 20, 2019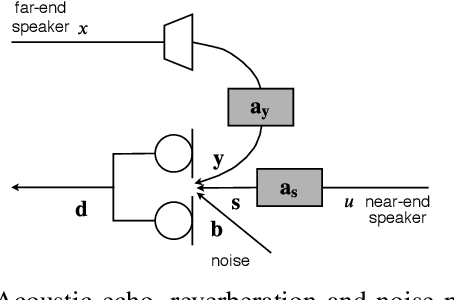
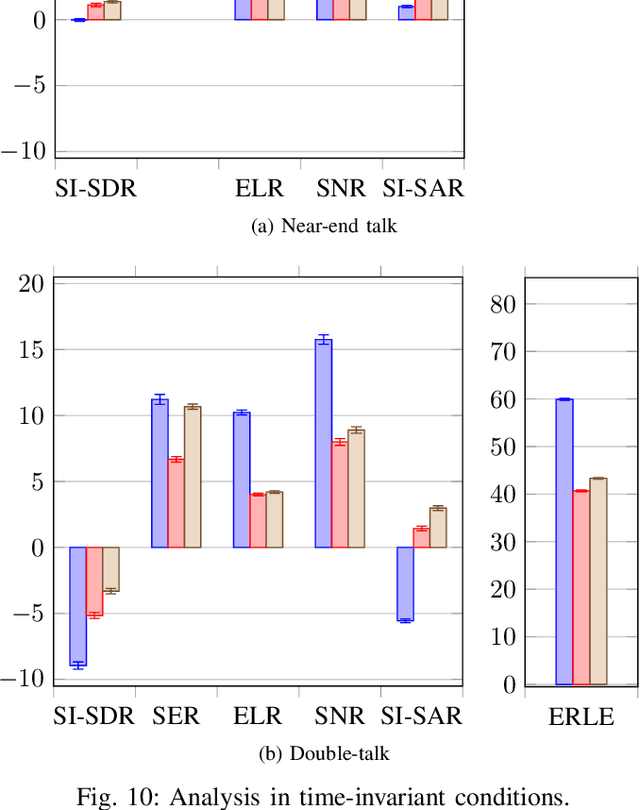
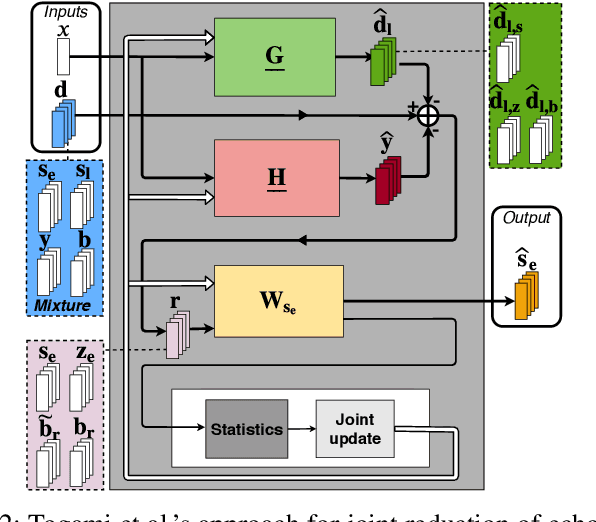
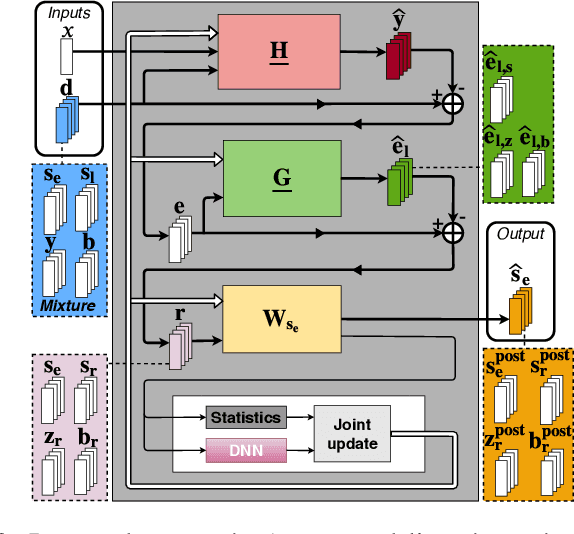
We consider the problem of simultaneous reduction of acoustic echo, reverberation and noise. In real scenarios, these distortion sources may occur simultaneously and reducing them implies combining the corresponding distortion-specific filters. As these filters interact with each other, they must be jointly optimized. We propose to model the target and residual signals after linear echo cancellation and dereverberation using a multichannel Gaussian modeling framework and to jointly represent their spectra by means of a neural network. We develop an iterative block-coordinate ascent algorithm to update all the filters. We evaluate our system on real recordings of acoustic echo, reverberation and noise acquired with a smart speaker in various situations. The proposed approach outperforms in terms of overall distortion a cascade of the individual approaches and a joint reduction approach which does not rely on a spectral model of the target and residual signals.