 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Variational Autoencoder for Speech Enhancement With a Supervised Classifier
Paper and Code
Feb 12, 2021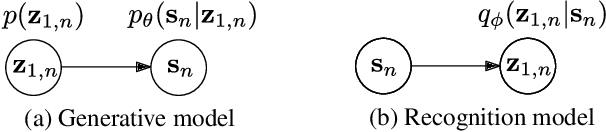
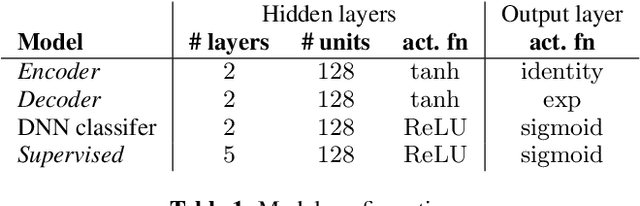
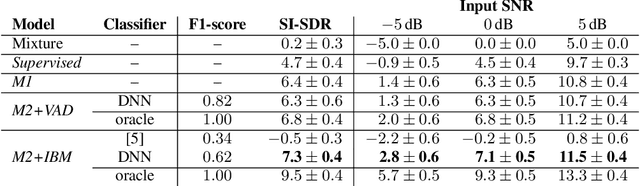
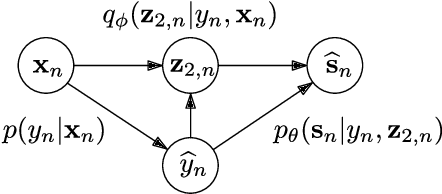
Recently, variational autoencoders have been successfully used to learn a probabilistic prior over speech signals, which is then used to perform speech enhancement. However, variational autoencoders are trained on clean speech only, which results in a limited ability of extracting the speech signal from noisy speech compared to supervised approaches. In this paper, we propose to guide the variational autoencoder with a supervised classifier separately trained on noisy speech. The estimated label is a high-level categorical variable describing the speech signal (e.g. speech activity) allowing for a more informed latent distribution compared to the standard variational autoencoder. We evaluate our method with different types of labels on real recordings of different noisy environments. Provided that the label better informs the latent distribution and that the classifier achieves good performance, the proposed approach outperforms the standard variational autoencoder and a conventional neural network-based supervised approach.