 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics of Collective Group Affect: Group-level Annotations and the Multimodal Modeling of Convergence and Divergence
Sep 13, 2024
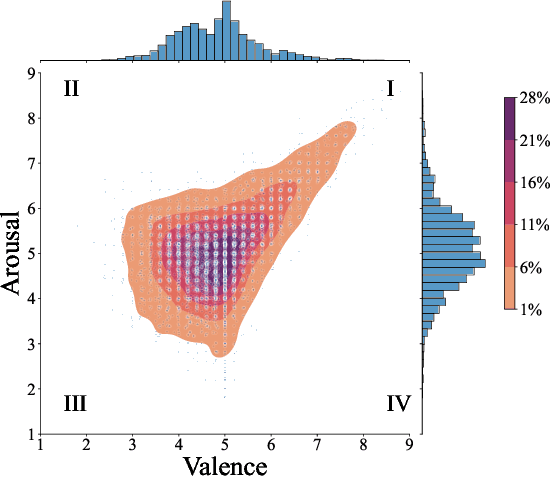

Collaborating in a group, whether face-to-face or virtually, involves continuously expressing emotions and interpreting those of other group members. Therefore, understanding group affect is essential to comprehending how groups interact and succeed in collaborative efforts. In this study, we move beyond individual-level affect and investigate group-level affect -- a collective phenomenon that reflects the shared mood or emotions among group members at a particular moment. As the first in literature, we gather annotations for group-level affective expressions using a fine-grained temporal approach (15 second windows) that also captures the inherent dynamics of the collective construct. To this end, we use trained annotators and an annotation procedure specifically tuned to capture the entire scope of the group interaction. In addition, we model group affect dynamics over time. One way to study the ebb and flow of group affect in group interactions is to model the underlying convergence (driven by emotional contagion) and divergence (resulting from emotional reactivity) of affective expressions amongst group members. To capture these interpersonal dynamics, we extract synchrony based features from both audio and visual social signal cues. An analysis of these features reveals that interacting groups tend to diverge in terms of their social signals along neutral levels of group affect, and converge along extreme levels of affect expression. We further present results on the predictive modeling of dynamic group affect which underscores the importance of using synchrony-based features in the modeling process, as well as the multimodal nature of group affect. We anticipate that the presented models will serve as the baselines of future research on the automatic recognition of dynamic group affect.
EMOCONV-DIFF: Diffusion-based Speech Emotion Conversion for Non-parallel and In-the-wild Data
Sep 14, 2023



Speech emotion conversion is the task of converting the expressed emotion of a spoken utterance to a target emotion while preserving the lexical content and speaker identity. While most existing works in speech emotion conversion rely on acted-out datasets and parallel data samples, in this work we specifically focus on more challenging in-the-wild scenarios and do not rely on parallel data. To this end, we propose a diffusion-based generative model for speech emotion conversion, the EmoConv-Diff, that is trained to reconstruct an input utterance while also conditioning on its emotion. Subsequently, at inference, a target emotion embedding is employed to convert the emotion of the input utterance to the given target emotion. As opposed to performing emotion conversion on categorical representations, we use a continuous arousal dimension to represent emotions while also achieving intensity control. We validate the proposed methodology on a large in-the-wild dataset, the MSP-Podcast v1.10. Our results show that the proposed diffusion model is indeed capable of synthesizing speech with a controllable target emotion. Crucially, the proposed approach shows improved performance along the extreme values of arousal and thereby addresses a common challenge in the speech emotion conversion literature.
In-the-wild Speech Emotion Conversion Using Disentangled Self-Supervised Representations and Neural Vocoder-based Resynthesis
Jun 02, 2023Speech emotion conversion aims to convert the expressed emotion of a spoken utterance to a target emotion while preserving the lexical information and the speaker's identity. In this work, we specifically focus on in-the-wild emotion conversion where parallel data does not exist, and the problem of disentangling lexical, speaker, and emotion information arises. In this paper, we introduce a methodology that uses self-supervised networks to disentangle the lexical, speaker, and emotional content of the utterance, and subsequently uses a HiFiGAN vocoder to resynthesise the disentangled representations to a speech signal of the targeted emotion. For better representation and to achieve emotion intensity control, we specifically focus on the aro\-usal dimension of continuous representations, as opposed to performing emotion conversion on categorical representations. We test our methodology on the large in-the-wild MSP-Podcast dataset. Results reveal that the proposed approach is aptly conditioned on the emotional content of input speech and is capable of synthesising natural-sounding speech for a target emotion. Results further reveal that the methodology better synthesises speech for mid-scale arousal (2 to 6) than for extreme arousal (1 and 7).
End-to-End Label Uncertainty Modeling in Speech Emotion Recognition using Bayesian Neural Networks and Label Distribution Learning
Sep 30, 2022



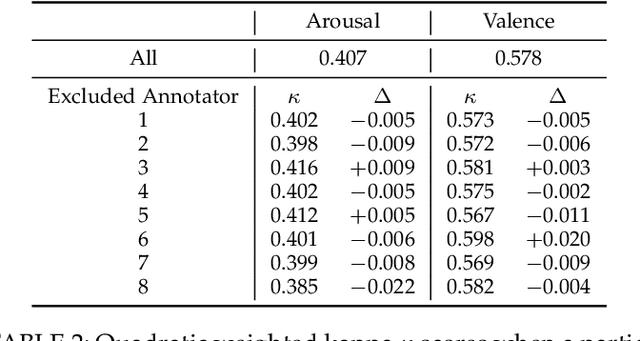
To train machine learning algorithms to predict emotional expressions in terms of arousal and valence, annotated datasets are needed. However, as different people perceive others' emotional expressions differently, their annotations are per se subjective. For this, annotations are typically collected from multiple annotators and averaged to obtain ground-truth labels. However, when exclusively trained on this averaged ground-truth, the trained network is agnostic to the inherent subjectivity in emotional expressions. In this work, we therefore propose an end-to-end Bayesian neural network capable of being trained on a distribution of labels to also capture the subjectivity-based label uncertainty. Instead of a Gaussian, we model the label distribution using Student's t-distribution, which also accounts for the number of annotations. We derive the corresponding Kullback-Leibler divergence loss and use it to train an estimator for the distribution of labels, from which the mean and uncertainty can be inferred. We validate the proposed method using two in-the-wild datasets. We show that the proposed t-distribution based approach achieves state-of-the-art uncertainty modeling results in speech emotion recognition, and also consistent results in cross-corpora evaluations. Furthermore, analyses reveal that the advantage of a t-distribution over a Gaussian grows with increasing inter-annotator correlation and a decreasing number of annotators.
Label Uncertainty Modeling and Prediction for Speech Emotion Recognition using t-Distributions
Jul 25, 2022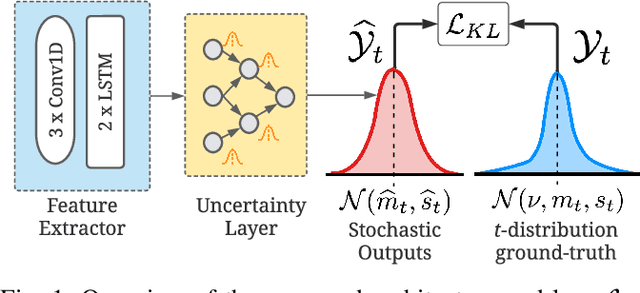
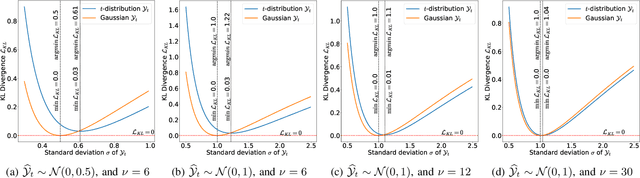


As different people perceive others' emotional expressions differently, their annotation in terms of arousal and valence are per se subjective. To address this, these emotion annotations are typically collected by multiple annotators and averaged across annotators in order to obtain labels for arousal and valence. However, besides the average, also the uncertainty of a label is of interest, and should also be modeled and predicted for automatic emotion recognition. In the literature, for simplicity, label uncertainty modeling is commonly approached with a Gaussian assumption on the collected annotations. However, as the number of annotators is typically rather small due to resource constraints, we argue that the Gaussian approach is a rather crude assumption. In contrast, in this work we propose to model the label distribution using a Student's t-distribution which allows us to account for the number of annotations available. With this model, we derive the corresponding Kullback-Leibler divergence based loss function and use it to train an estimator for the distribution of emotion labels, from which the mean and uncertainty can be inferred. Through qualitative and quantitative analysis, we show the benefits of the t-distribution over a Gaussian distribution. We validate our proposed method on the AVEC'16 dataset. Results reveal that our t-distribution based approach improves over the Gaussian approach with state-of-the-art uncertainty modeling results in speech-based emotion recognition, along with an optimal and even faster convergence.
End-to-end label uncertainty modeling for speech emotion recognition using Bayesian neural networks
Oct 07, 2021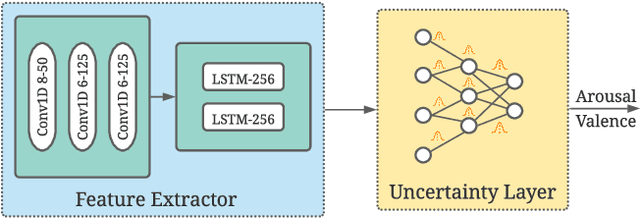
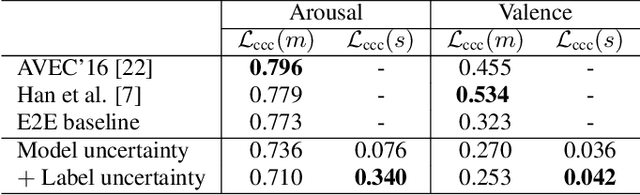

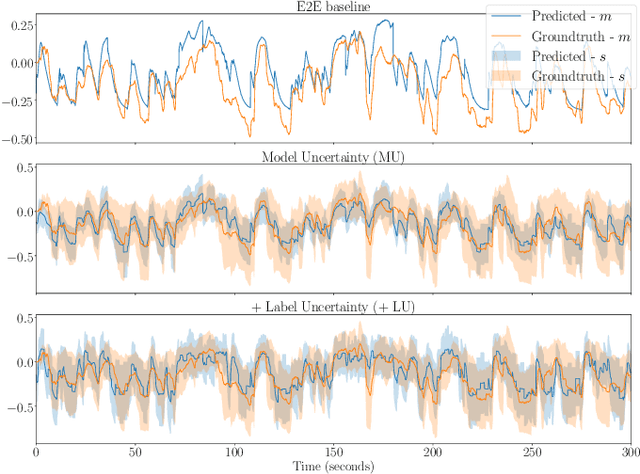
Emotions are subjective constructs. Recent end-to-end speech emotion recognition systems are typically agnostic to the subjective nature of emotions, despite their state-of-the-art performances. In this work, we introduce an end-to-end Bayesian neural network architecture to capture the inherent subjectivity in emotions. To the best of our knowledge, this work is the first to use Bayesian neural networks for speech emotion recognition. At training, the network learns a distribution of weights to capture the inherent uncertainty related to subjective emotion annotations. For this, we introduce a loss term which enables the model to be explicitly trained on a distribution of emotion annotations, rather than training them exclusively on mean or gold-standard labels. We evaluate the proposed approach on the AVEC'16 emotion recognition dataset. Qualitative and quantitative analysis of the results reveal that the proposed model can aptly capture the distribution of subjective emotion annotations with a compromise between mean and standard deviation estimations.