 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Uncertainty Modeling and Prediction for Speech Emotion Recognition using t-Distributions
Paper and Code
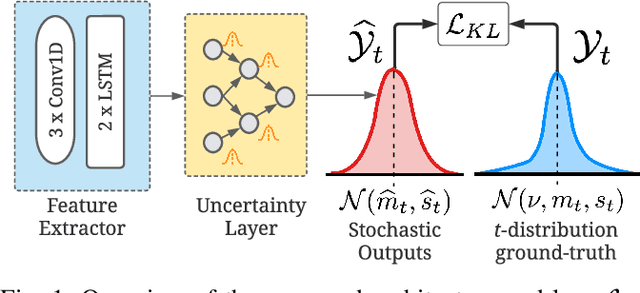
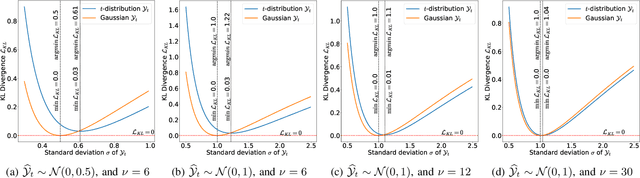


As different people perceive others' emotional expressions differently, their annotation in terms of arousal and valence are per se subjective. To address this, these emotion annotations are typically collected by multiple annotators and averaged across annotators in order to obtain labels for arousal and valence. However, besides the average, also the uncertainty of a label is of interest, and should also be modeled and predicted for automatic emotion recognition. In the literature, for simplicity, label uncertainty modeling is commonly approached with a Gaussian assumption on the collected annotations. However, as the number of annotators is typically rather small due to resource constraints, we argue that the Gaussian approach is a rather crude assumption. In contrast, in this work we propose to model the label distribution using a Student's t-distribution which allows us to account for the number of annotations available. With this model, we derive the corresponding Kullback-Leibler divergence based loss function and use it to train an estimator for the distribution of emotion labels, from which the mean and uncertainty can be inferred. Through qualitative and quantitative analysis, we show the benefits of the t-distribution over a Gaussian distribution. We validate our proposed method on the AVEC'16 dataset. Results reveal that our t-distribution based approach improves over the Gaussian approach with state-of-the-art uncertainty modeling results in speech-based emotion recognition, along with an optimal and even faster convergence.