Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Signal Improvement Using Causal Generative Diffusion Models
Paper and Code
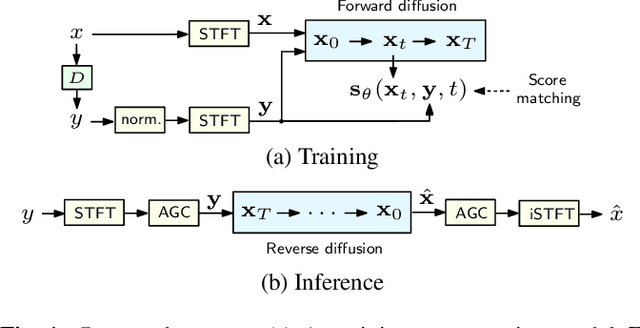
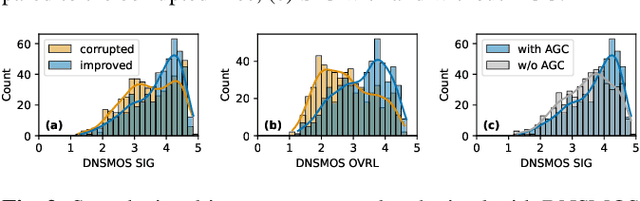
In this paper, we present a causal speech signal improvement system that is designed to handle different types of distortions. The method is based on a generative diffusion model which has been shown to work well in scenarios with missing data and non-linear corruptions. To guarantee causal processing, we modify the network architecture of our previous work and replace global normalization with causal adaptive gain control. We generate diverse training data containing a broad range of distortions. This work was performed in the context of an "ICASSP Signal Processing Grand Challenge" and submitted to the non-real-time track of the "Speech Signal Improvement Challenge 2023", where it was ranked fifth.
* Accepted by ICASSP 2023
View paper on