 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Enhancement and Dereverberation with Diffusion-based Generative Models
Paper and Code
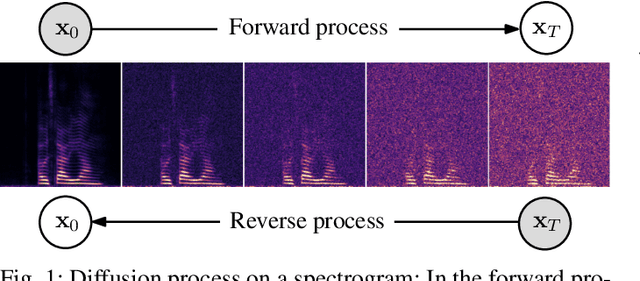
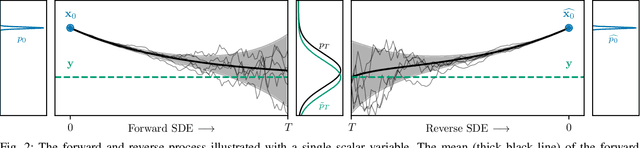
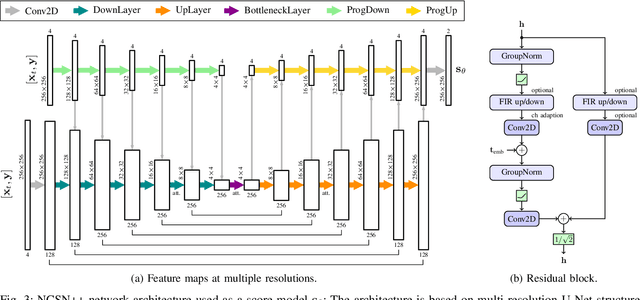
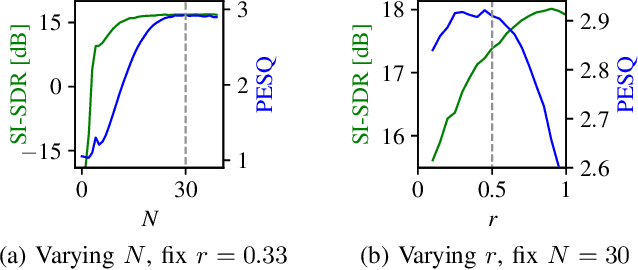
Recently, diffusion-based generative models have been introduced to the task of speech enhancement. The corruption of clean speech is modeled as a fixed forward process in which increasing amounts of noise are gradually added. By learning to reverse this process in an iterative fashion conditioned on the noisy input, clean speech is generated. We build upon our previous work and derive the training task within the formalism of stochastic differential equations. We present a detailed theoretical review of the underlying score matching objective and explore different sampler configurations for solving the reverse process at test time. By using a sophisticated network architecture from natural image generation literature, we significantly improve performance compared to our previous publication. We also show that we can compete with recent discriminative models and achieve better generalization when evaluating on a different corpus than used for training. We complement the evaluation results with a subjective listening test, in which our proposed method is rated best. Furthermore, we show that the proposed method achieves remarkable state-of-the-art performance in single-channel speech dereverberation. Our code and audio examples are available online, see https://uhh.de/inf-sp-sgmse