 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of Speech Separation Models for Similar-pitch Speakers
Jul 22, 2024Single-channel speech separation is a crucial task for enhancing speech recognition systems in multi-speaker environments. This paper investigates the robustness of state-of-the-art Neural Network models in scenarios where the pitch differences between speakers are minimal. Building on earlier findings by Ditter and Gerkmann, which identified a significant performance drop for the 2018 Chimera++ under similar-pitch conditions, our study extends the analysis to more recent and sophisticated Neural Network models. Our experiments reveal that modern models have substantially reduced the performance gap for matched training and testing conditions. However, a substantial performance gap persists under mismatched conditions, with models performing well for large pitch differences but showing worse performance if the speakers' pitches are similar. These findings motivate further research into the generalizability of speech separation models to similar-pitch speakers and unseen data.
Multi-channel Speech Separation Using Spatially Selective Deep Non-linear Filters
Apr 24, 2023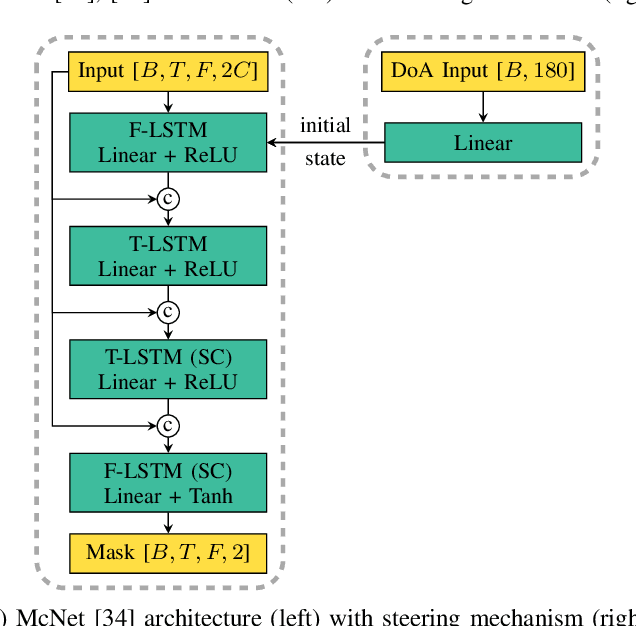
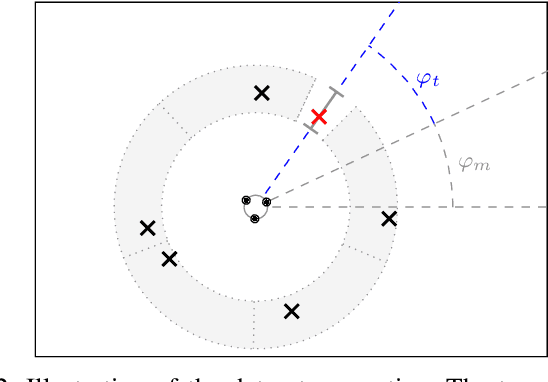
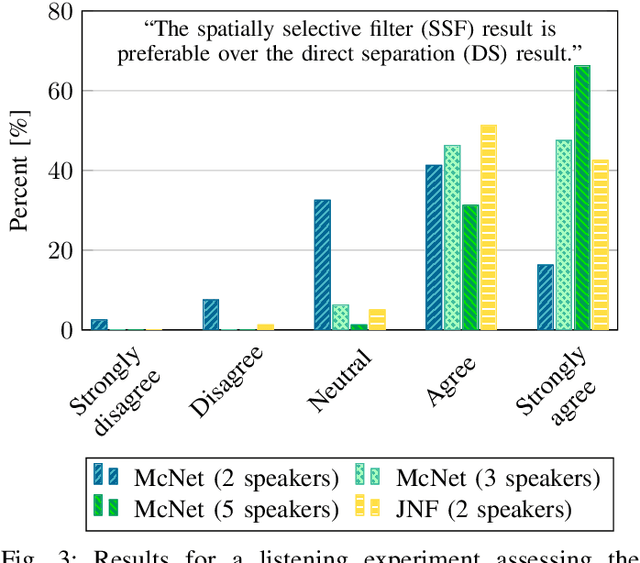
In a multi-channel separation task with multiple speakers, we aim to recover all individual speech signals from the mixture. In contrast to single-channel approaches, which rely on the different spectro-temporal characteristics of the speech signals, multi-channel approaches should additionally utilize the different spatial locations of the sources for a more powerful separation especially when the number of sources increases. To enhance the spatial processing in a multi-channel source separation scenario, in this work, we propose a deep neural network (DNN) based spatially selective filter (SSF) that can be spatially steered to extract the speaker of interest by initializing a recurrent neural network layer with the target direction. We compare the proposed SSF with a common end-to-end direct separation (DS) approach trained using utterance-wise permutation invariant training (PIT), which only implicitly learns to perform spatial filtering. We show that the SSF has a clear advantage over a DS approach with the same underlying network architecture when there are more than two speakers in the mixture, which can be attributed to a better use of the spatial information. Furthermore, we find that the SSF generalizes much better to additional noise sources that were not seen during training.
Spatially Selective Deep Non-linear Filters for Speaker Extraction
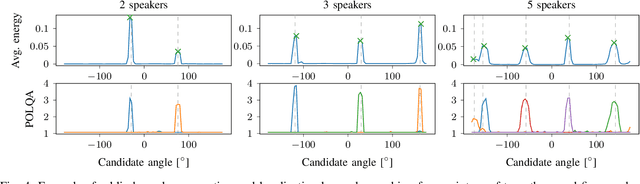
Nov 04, 2022In a scenario with multiple persons talking simultaneously, the spatial characteristics of the signals are the most distinct feature for extracting the target signal. In this work, we develop a deep joint spatial-spectral non-linear filter that can be steered in an arbitrary target direction. For this we propose a simple and effective conditioning mechanism, which sets the initial state of the filter's recurrent layers based on the target direction. We show that this scheme is more effective than the baseline approach and increases the flexibility of the filter at no performance cost. The resulting spatially selective non-linear filters can also be used for speech separation of an arbitrary number of speakers and enable very accurate multi-speaker localization as we demonstrate in this paper.
Insights into Deep Non-linear Filters for Improved Multi-channel Speech Enhancement
Jun 27, 2022
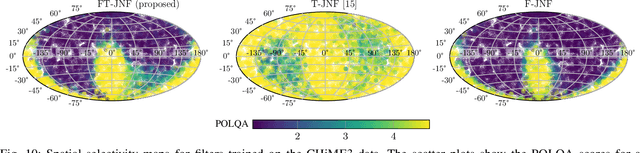
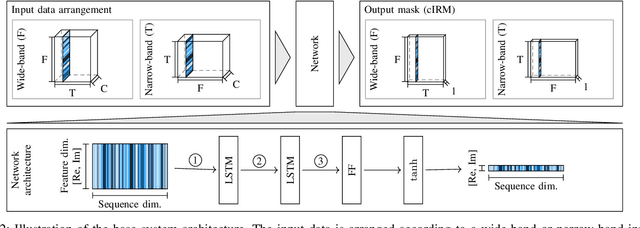

The key advantage of using multiple microphones for speech enhancement is that spatial filtering can be used to complement the tempo-spectral processing. In a traditional setting, linear spatial filtering (beamforming) and single-channel post-filtering are commonly performed separately. In contrast, there is a trend towards employing deep neural networks (DNNs) to learn a joint spatial and tempo-spectral non-linear filter, which means that the restriction of a linear processing model and that of a separate processing of spatial and tempo-spectral information can potentially be overcome. However, the internal mechanisms that lead to good performance of such data-driven filters for multi-channel speech enhancement are not well understood. Therefore, in this work, we analyse the properties of a non-linear spatial filter realized by a DNN as well as its interdependency with temporal and spectral processing by carefully controlling the information sources (spatial, spectral, and temporal) available to the network. We confirm the superiority of a non-linear spatial processing model, which outperforms an oracle linear spatial filter in a challenging speaker extraction scenario for a low number of microphones by 0.24 POLQA score. Our analyses reveal that in particular spectral information should be processed jointly with spatial information as this increases the spatial selectivity of the filter. Our systematic evaluation then leads to a simple network architecture, that outperforms state-of-the-art network architectures on a speaker extraction task by 0.22 POLQA score and by 0.32 POLQA score on the CHiME3 data.
On the Role of Spatial, Spectral, and Temporal Processing for DNN-based Non-linear Multi-channel Speech Enhancement
Jun 22, 2022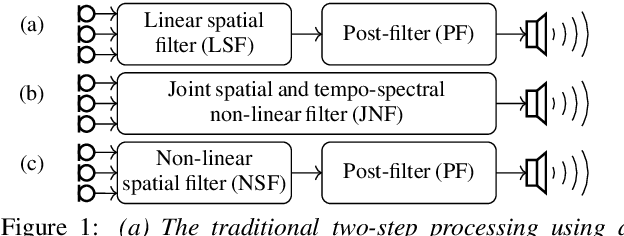
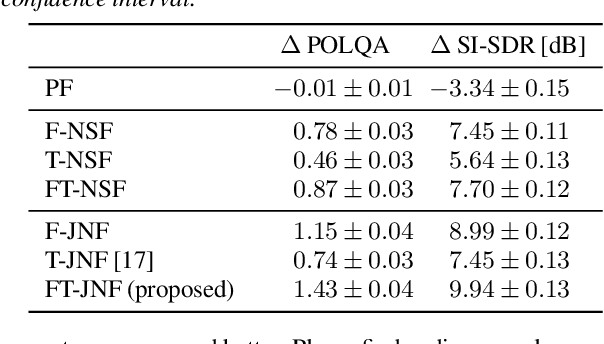
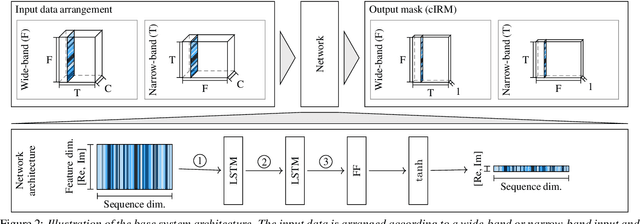

Employing deep neural networks (DNNs) to directly learn filters for multi-channel speech enhancement has potentially two key advantages over a traditional approach combining a linear spatial filter with an independent tempo-spectral post-filter: 1) non-linear spatial filtering allows to overcome potential restrictions originating from a linear processing model and 2) joint processing of spatial and tempo-spectral information allows to exploit interdependencies between different sources of information. A variety of DNN-based non-linear filters have been proposed recently, for which good enhancement performance is reported. However, little is known about the internal mechanisms which turns network architecture design into a game of chance. Therefore, in this paper, we perform experiments to better understand the internal processing of spatial, spectral and temporal information by DNN-based non-linear filters. On the one hand, our experiments in a difficult speech extraction scenario confirm the importance of non-linear spatial filtering, which outperforms an oracle linear spatial filter by 0.24 POLQA score. On the other hand, we demonstrate that joint processing results in a large performance gap of 0.4 POLQA score between network architectures exploiting spectral versus temporal information besides spatial information.
Nonlinear Spatial Filtering in Multichannel Speech Enhancement
Apr 22, 2021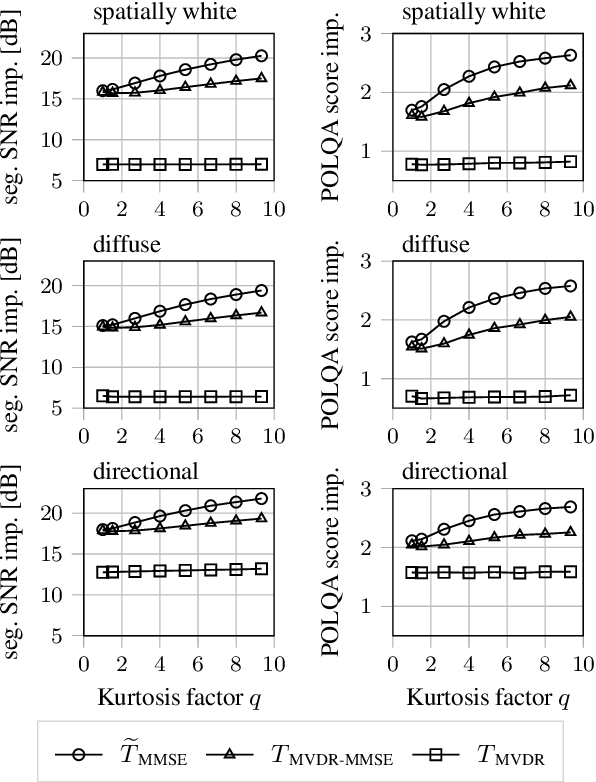
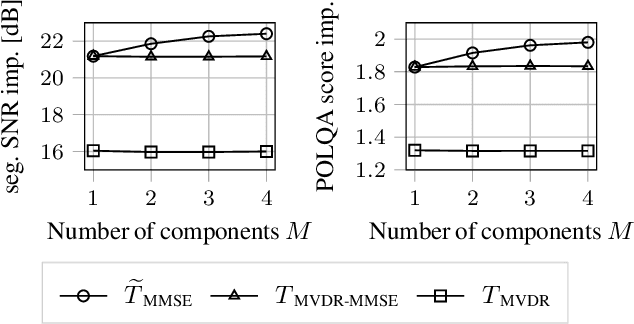
The majority of multichannel speech enhancement algorithms are two-step procedures that first apply a linear spatial filter, a so-called beamformer, and combine it with a single-channel approach for postprocessing. However, the serial concatenation of a linear spatial filter and a postfilter is not generally optimal in the minimum mean square error (MMSE) sense for noise distributions other than a Gaussian distribution. Rather, the MMSE optimal filter is a joint spatial and spectral nonlinear function. While estimating the parameters of such a filter with traditional methods is challenging, modern neural networks may provide an efficient way to learn the nonlinear function directly from data. To see if further research in this direction is worthwhile, in this work we examine the potential performance benefit of replacing the common two-step procedure with a joint spatial and spectral nonlinear filter. We analyze three different forms of non-Gaussianity: First, we evaluate on super-Gaussian noise with a high kurtosis. Second, we evaluate on inhomogeneous noise fields created by five interfering sources using two microphones, and third, we evaluate on real-world recordings from the CHiME3 database. In all scenarios, considerable improvements may be obtained. Most prominently, our analyses show that a nonlinear spatial filter uses the available spatial information more effectively than a linear spatial filter as it is capable of suppressing more than $D-1$ directional interfering sources with a $D$-dimensional microphone array without spatial adaptation.
* Accepted version, 11 pages, 6 figures