 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhase-Aware Deep Speech Enhancement: It's All About The Frame Length
Paper and Code
Mar 30, 2022


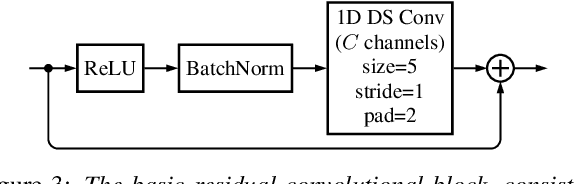
While phase-aware speech processing has been receiving increasing attention in recent years, most narrowband STFT approaches with frame lengths of about 32ms show a rather modest impact of phase on overall performance. At the same time, modern deep neural network (DNN)-based approaches, like Conv-TasNet, that implicitly modify both magnitude and phase yield great performance on very short frames (2ms). Motivated by this observation, in this paper we systematically investigate the role of phase and magnitude in DNN-based speech enhancement for different frame lengths. The results show that a phase-aware DNN can take advantage of what previous studies concerning reconstruction of clean speech have shown: When using short frames, the phase spectrum becomes more important while the importance of the magnitude spectrum decreases. Furthermore, our experiments show that when both magnitude and phase are estimated, shorter frames result in a considerably improved performance in a DNN with explicit phase estimation. Contrarily, in the phase-blind case, where only magnitudes are processed, 32ms frames lead to the best performance. We conclude that DNN-based phase estimation benefits from the use of shorter frames and recommend a frame length of about 4ms for future phase-aware deep speech enhancement methods.