 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher Network Calibration Improves Cross-Quality Knowledge Distillation
Apr 15, 2023

We investigate cross-quality knowledge distillation (CQKD), a knowledge distillation method where knowledge from a teacher network trained with full-resolution images is transferred to a student network that takes as input low-resolution images. As image size is a deciding factor for the computational load of computer vision applications, CQKD notably reduces the requirements by only using the student network at inference time. Our experimental results show that CQKD outperforms supervised learning in large-scale image classification problems. We also highlight the importance of calibrating neural networks: we show that with higher temperature smoothing of the teacher's output distribution, the student distribution exhibits a higher entropy, which leads to both, a lower calibration error and a higher network accuracy.
Demand Forecasting using Long Short-Term Memory Neural Networks
Aug 19, 2020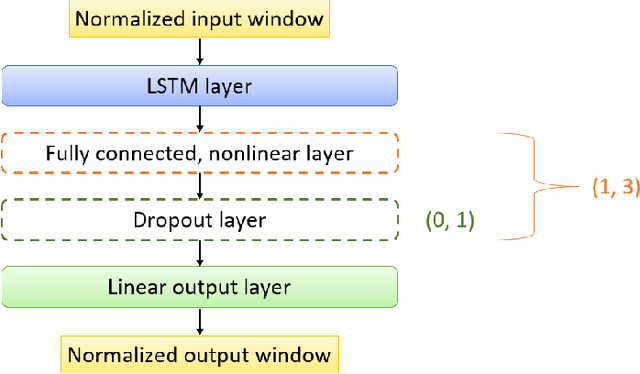
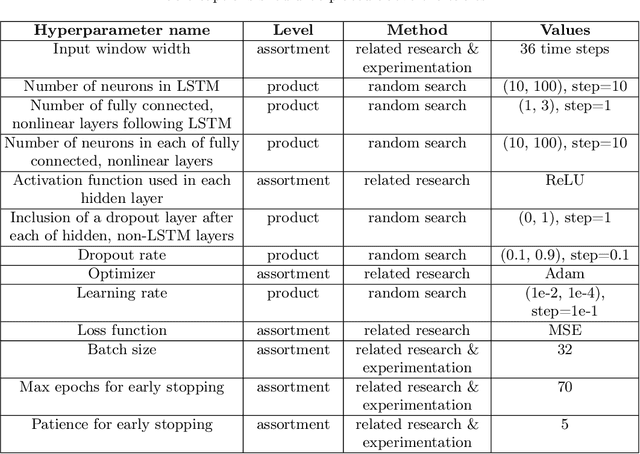
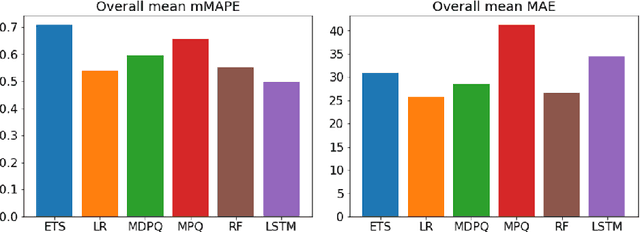
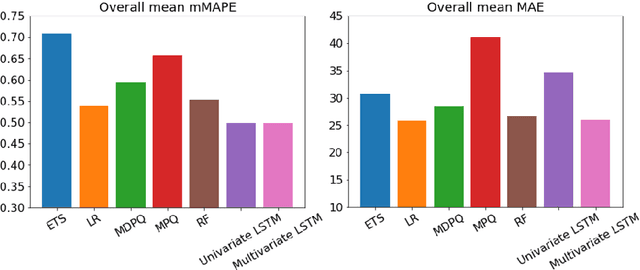
In this paper we investigate to what extent long short-term memory neural networks (LSTMs) are suitable for demand forecasting in the e-grocery retail sector. For this purpose, univariate as well as multivariate LSTM-based models were developed and tested for 100 fast-moving consumer goods in the context of a master's thesis. On average, the developed models showed better results for food products than the comparative models from both statistical and machine learning families. Solely in the area of beverages random forest and linear regression achieved slightly better results. This outcome suggests that LSTMs can be used for demand forecasting at product level. The performance of the models presented here goes beyond the current state of research, as can be seen from the evaluations based on a data set that unfortunately has not been publicly available to date.
Rectifying Classifier Chains for Multi-Label Classification
Jun 07, 2019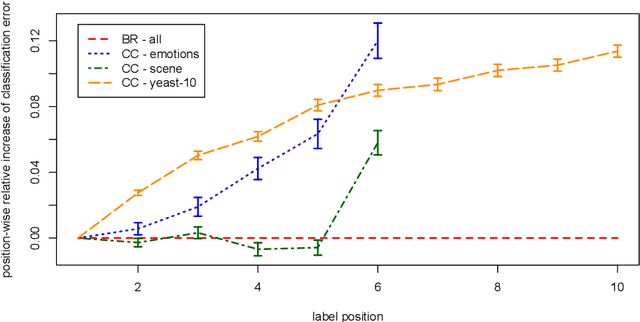

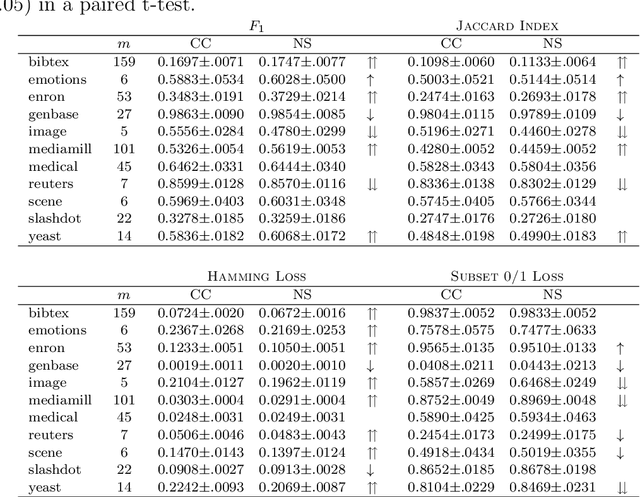
Classifier chains have recently been proposed as an appealing method for tackling the multi-label classification task. In addition to several empirical studies showing its state-of-the-art performance, especially when being used in its ensemble variant, there are also some first results on theoretical properties of classifier chains. Continuing along this line, we analyze the influence of a potential pitfall of the learning process, namely the discrepancy between the feature spaces used in training and testing: While true class labels are used as supplementary attributes for training the binary models along the chain, the same models need to rely on estimations of these labels at prediction time. We elucidate under which circumstances the attribute noise thus created can affect the overall prediction performance. As a result of our findings, we propose two modifications of classifier chains that are meant to overcome this problem. Experimentally, we show that our variants are indeed able to produce better results in cases where the original chaining process is likely to fail.