 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher Network Calibration Improves Cross-Quality Knowledge Distillation
Apr 15, 2023

We investigate cross-quality knowledge distillation (CQKD), a knowledge distillation method where knowledge from a teacher network trained with full-resolution images is transferred to a student network that takes as input low-resolution images. As image size is a deciding factor for the computational load of computer vision applications, CQKD notably reduces the requirements by only using the student network at inference time. Our experimental results show that CQKD outperforms supervised learning in large-scale image classification problems. We also highlight the importance of calibrating neural networks: we show that with higher temperature smoothing of the teacher's output distribution, the student distribution exhibits a higher entropy, which leads to both, a lower calibration error and a higher network accuracy.
Partially Observable Markov Decision Processes in Robotics: A Survey
Sep 21, 2022

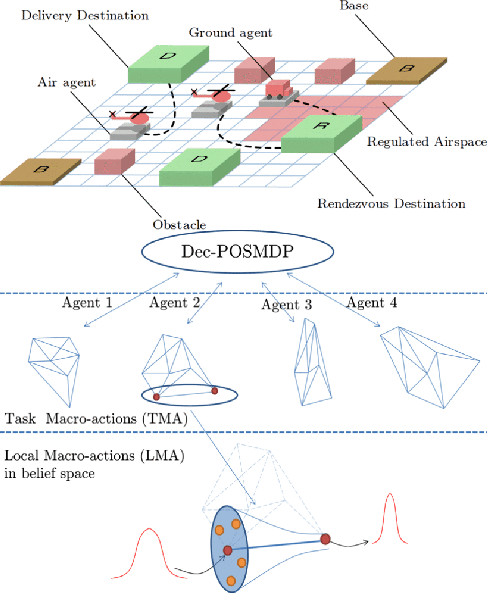
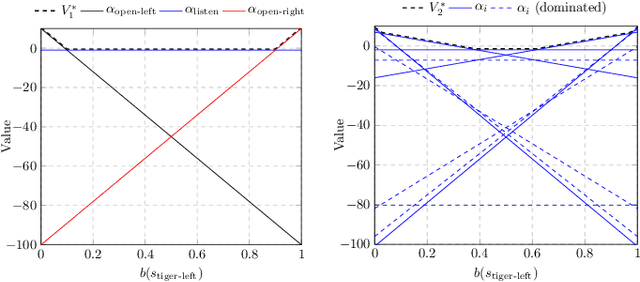
Noisy sensing, imperfect control, and environment changes are defining characteristics of many real-world robot tasks. The partially observable Markov decision process (POMDP) provides a principled mathematical framework for modeling and solving robot decision and control tasks under uncertainty. Over the last decade, it has seen many successful applications, spanning localization and navigation, search and tracking, autonomous driving, multi-robot systems, manipulation, and human-robot interaction. This survey aims to bridge the gap between the development of POMDP models and algorithms at one end and application to diverse robot decision tasks at the other. It analyzes the characteristics of these tasks and connects them with the mathematical and algorithmic properties of the POMDP framework for effective modeling and solution. For practitioners, the survey provides some of the key task characteristics in deciding when and how to apply POMDPs to robot tasks successfully. For POMDP algorithm designers, the survey provides new insights into the unique challenges of applying POMDPs to robot systems and points to promising new directions for further research.
CloudAAE: Learning 6D Object Pose Regression with On-line Data Synthesis on Point Clouds
Mar 02, 2021
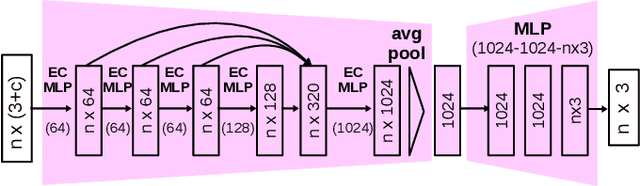
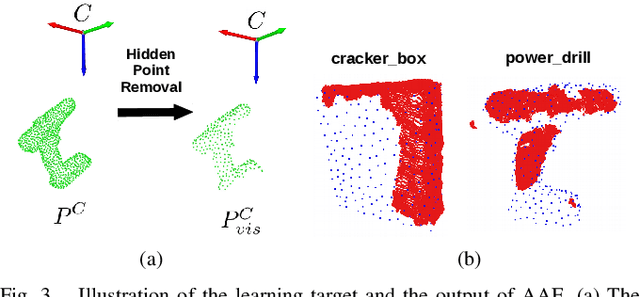
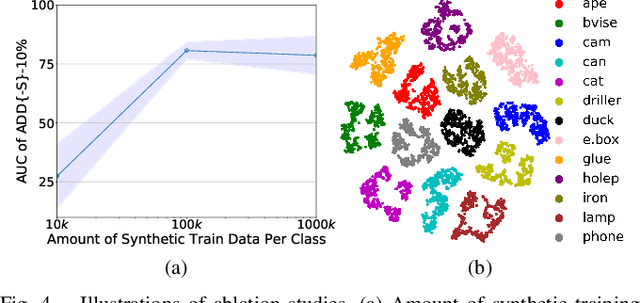
It is often desired to train 6D pose estimation systems on synthetic data because manual annotation is expensive. However, due to the large domain gap between the synthetic and real images, synthesizing color images is expensive. In contrast, this domain gap is considerably smaller and easier to fill for depth information. In this work, we present a system that regresses 6D object pose from depth information represented by point clouds, and a lightweight data synthesis pipeline that creates synthetic point cloud segments for training. We use an augmented autoencoder (AAE) for learning a latent code that encodes 6D object pose information for pose regression. The data synthesis pipeline only requires texture-less 3D object models and desired viewpoints, and it is cheap in terms of both time and hardware storage. Our data synthesis process is up to three orders of magnitude faster than commonly applied approaches that render RGB image data. We show the effectiveness of our system on the LineMOD, LineMOD Occlusion, and YCB Video datasets. The implementation of our system is available at: https://github.com/GeeeG/CloudAAE.
Multi-agent active perception with prediction rewards
Oct 22, 2020



Multi-agent active perception is a task where a team of agents cooperatively gathers observations to compute a joint estimate of a hidden variable. The task is decentralized and the joint estimate can only be computed after the task ends by fusing observations of all agents. The objective is to maximize the accuracy of the estimate. The accuracy is quantified by a centralized prediction reward determined by a centralized decision-maker who perceives the observations gathered by all agents after the task ends. In this paper, we model multi-agent active perception as a decentralized partially observable Markov decision process (Dec-POMDP) with a convex centralized prediction reward. We prove that by introducing individual prediction actions for each agent, the problem is converted into a standard Dec-POMDP with a decentralized prediction reward. The loss due to decentralization is bounded, and we give a sufficient condition for when it is zero. Our results allow application of any Dec-POMDP solution algorithm to multi-agent active perception problems, and enable planning to reduce uncertainty without explicit computation of joint estimates. We demonstrate the empirical usefulness of our results by applying a standard Dec-POMDP algorithm to multi-agent active perception problems, showing increased scalability in the planning horizon.
Multi-Sensor Next-Best-View Planning as Matroid-Constrained Submodular Maximization
Jul 04, 2020
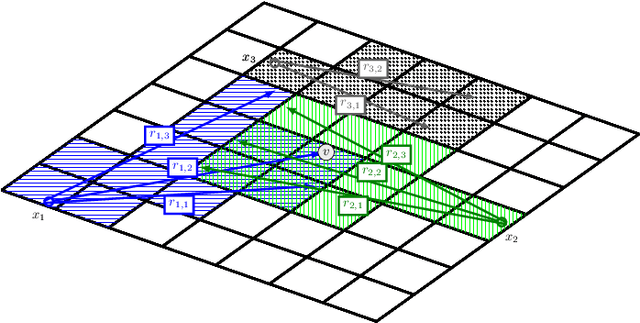


3D scene models are useful in robotics for tasks such as path planning, object manipulation, and structural inspection. We consider the problem of creating a 3D model using depth images captured by a team of multiple robots. Each robot selects a viewpoint and captures a depth image from it, and the images are fused to update the scene model. The process is repeated until a scene model of desired quality is obtained. Next-best-view planning uses the current scene model to select the next viewpoints. The objective is to select viewpoints so that the images captured using them improve the quality of the scene model the most. In this paper, we address next-best-view planning for multiple depth cameras. We propose a utility function that scores sets of viewpoints and avoids overlap between multiple sensors. We show that multi-sensor next-best-view planning with this utility function is an instance of submodular maximization under a matroid constraint. This allows the planning problem to be solved by a polynomial-time greedy algorithm that yields a solution within a constant factor from the optimal. We evaluate the performance of our planning algorithm in simulated experiments with up to 8 sensors, and in real-world experiments using two robot arms equipped with depth cameras.
6D Object Pose Regression via Supervised Learning on Point Clouds
Jan 24, 2020
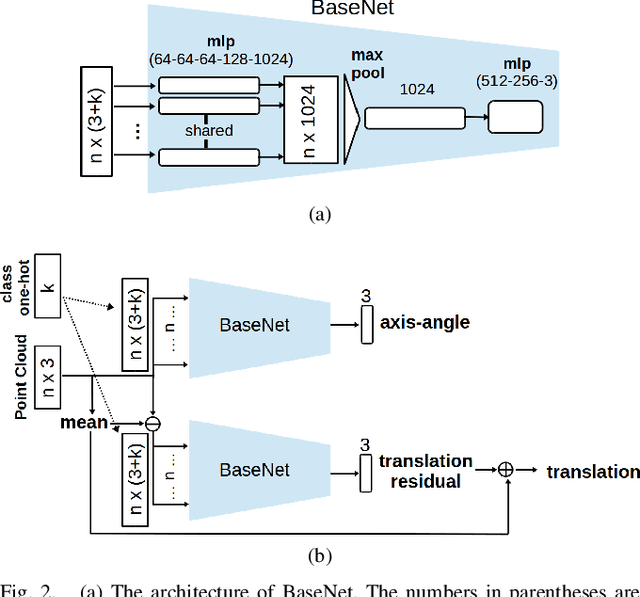

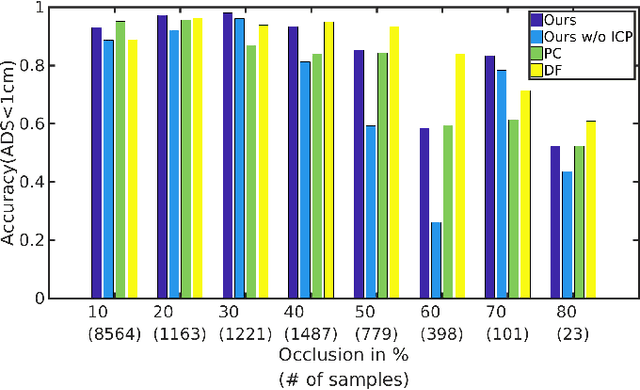
This paper addresses the task of estimating the 6 degrees of freedom pose of a known 3D object from depth information represented by a point cloud. Deep features learned by convolutional neural networks from color information have been the dominant features to be used for inferring object poses, while depth information receives much less attention. However, depth information contains rich geometric information of the object shape, which is important for inferring the object pose. We use depth information represented by point clouds as the input to both deep networks and geometry-based pose refinement and use separate networks for rotation and translation regression. We argue that the axis-angle representation is a suitable rotation representation for deep learning, and use a geodesic loss function for rotation regression. Ablation studies show that these design choices outperform alternatives such as the quaternion representation and L2 loss, or regressing translation and rotation with the same network. Our simple yet effective approach clearly outperforms state-of-the-art methods on the YCB-video dataset. The implementation and trained model are avaliable at: https://github.com/GeeeG/CloudPose.
Information Gathering in Decentralized POMDPs by Policy Graph Improvement
Feb 26, 2019



Decentralized policies for information gathering are required when multiple autonomous agents are deployed to collect data about a phenomenon of interest without the ability to communicate. Decentralized partially observable Markov decision processes (Dec-POMDPs) are a general, principled model well-suited for such decentralized multiagent decision-making problems. In this paper, we investigate Dec-POMDPs for decentralized information gathering problems. An optimal solution of a Dec-POMDP maximizes the expected sum of rewards over time. To encourage information gathering, we set the reward as a function of the agents' state information, for example the negative Shannon entropy. We prove that if the reward is convex, then the finite-horizon value function of the corresponding Dec-POMDP is also convex. We propose the first heuristic algorithm for information gathering Dec-POMDPs, and empirically prove its effectiveness by solving problems an order of magnitude larger than previous state-of-the-art.
Multi-label Object Attribute Classification using a Convolutional Neural Network
Nov 10, 2018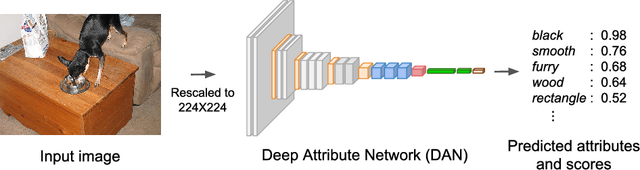
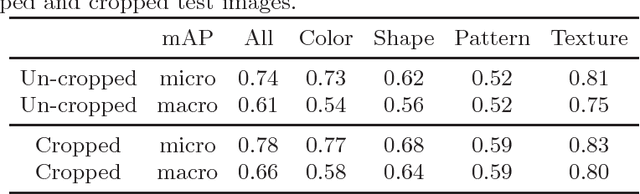
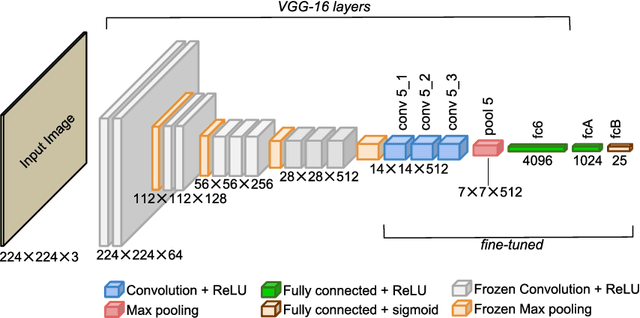
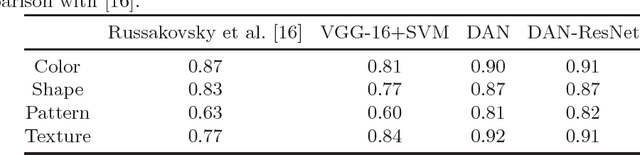
Objects of different classes can be described using a limited number of attributes such as color, shape, pattern, and texture. Learning to detect object attributes instead of only detecting objects can be helpful in dealing with a priori unknown objects. With this inspiration, a deep convolutional neural network for low-level object attribute classification, called the Deep Attribute Network (DAN), is proposed. Since object features are implicitly learned by object recognition networks, one such existing network is modified and fine-tuned for developing DAN. The performance of DAN is evaluated on the ImageNet Attribute and a-Pascal datasets. Experiments show that in comparison with state-of-the-art methods, the proposed model achieves better results.
Occlusion Resistant Object Rotation Regression from Point Cloud Segments
Aug 16, 2018



Rotation estimation of known rigid objects is important for robotic applications such as dexterous manipulation. Most existing methods for rotation estimation use intermediate representations such as templates, global or local feature descriptors, or object coordinates, which require multiple steps in order to infer the object pose. We propose to directly regress a pose vector from raw point cloud segments using a convolutional neural network. Experimental results show that our method achieves competitive performance compared to a state-of-the-art method, while also showing more robustness against occlusion. Our method does not require any post processing such as refinement with the iterative closest point algorithm.
Saliency-guided Adaptive Seeding for Supervoxel Segmentation
Oct 19, 2017
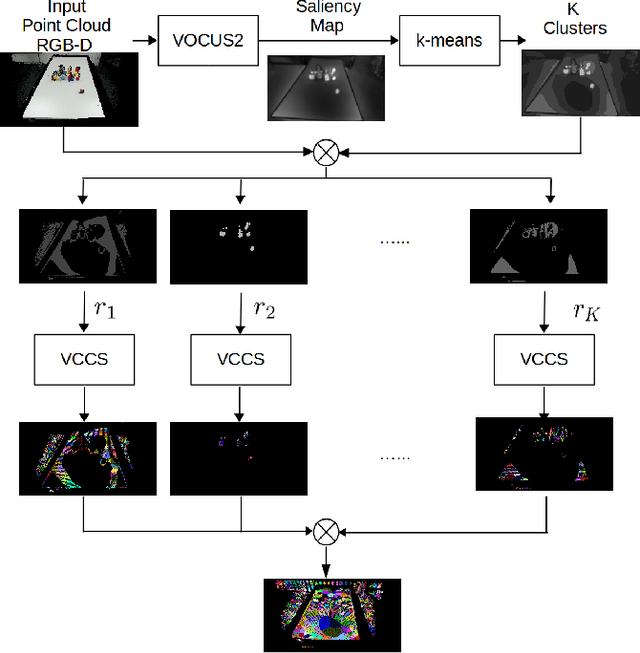
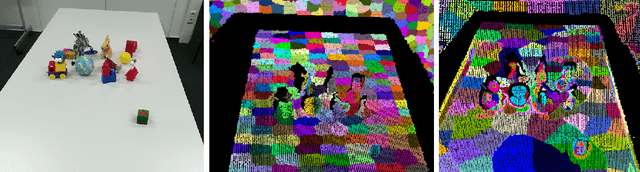
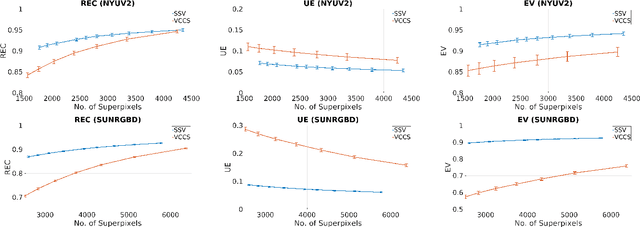
We propose a new saliency-guided method for generating supervoxels in 3D space. Rather than using an evenly distributed spatial seeding procedure, our method uses visual saliency to guide the process of supervoxel generation. This results in densely distributed, small, and precise supervoxels in salient regions which often contain objects, and larger supervoxels in less salient regions that often correspond to background. Our approach largely improves the quality of the resulting supervoxel segmentation in terms of boundary recall and under-segmentation error on publicly available benchmarks.