 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloudAAE: Learning 6D Object Pose Regression with On-line Data Synthesis on Point Clouds
Paper and Code

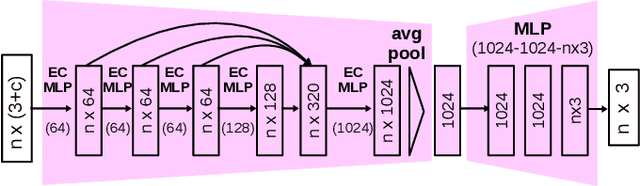
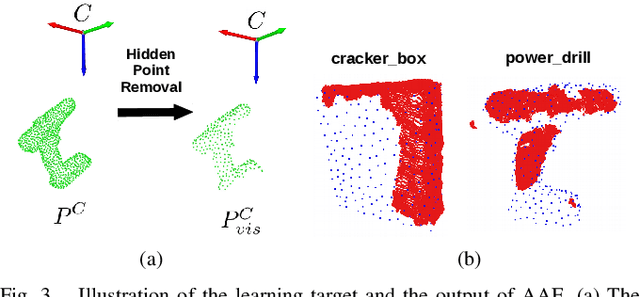
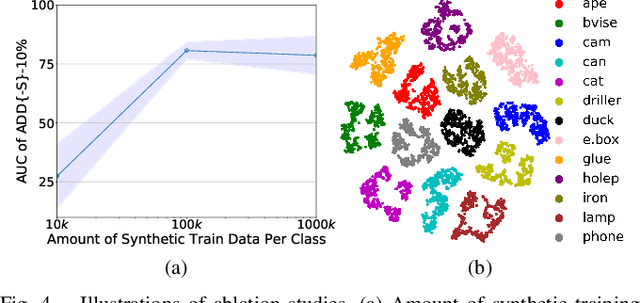
It is often desired to train 6D pose estimation systems on synthetic data because manual annotation is expensive. However, due to the large domain gap between the synthetic and real images, synthesizing color images is expensive. In contrast, this domain gap is considerably smaller and easier to fill for depth information. In this work, we present a system that regresses 6D object pose from depth information represented by point clouds, and a lightweight data synthesis pipeline that creates synthetic point cloud segments for training. We use an augmented autoencoder (AAE) for learning a latent code that encodes 6D object pose information for pose regression. The data synthesis pipeline only requires texture-less 3D object models and desired viewpoints, and it is cheap in terms of both time and hardware storage. Our data synthesis process is up to three orders of magnitude faster than commonly applied approaches that render RGB image data. We show the effectiveness of our system on the LineMOD, LineMOD Occlusion, and YCB Video datasets. The implementation of our system is available at: https://github.com/GeeeG/CloudAAE.