Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency-guided Adaptive Seeding for Supervoxel Segmentation
Paper and Code

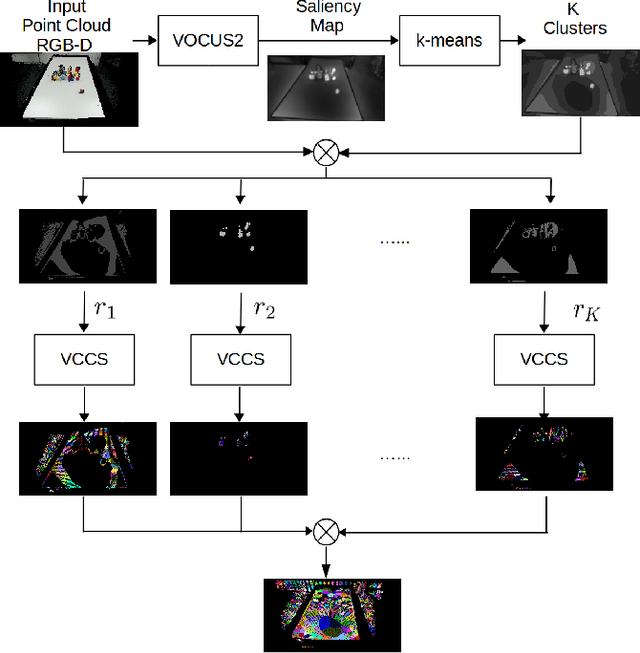
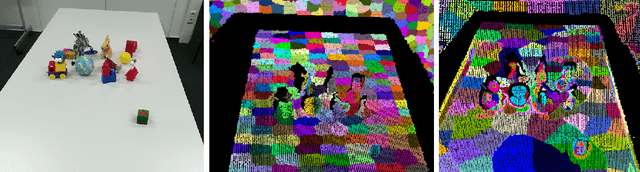
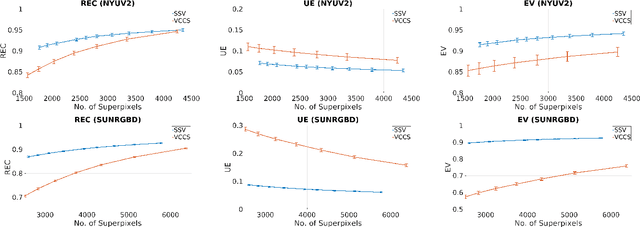
We propose a new saliency-guided method for generating supervoxels in 3D space. Rather than using an evenly distributed spatial seeding procedure, our method uses visual saliency to guide the process of supervoxel generation. This results in densely distributed, small, and precise supervoxels in salient regions which often contain objects, and larger supervoxels in less salient regions that often correspond to background. Our approach largely improves the quality of the resulting supervoxel segmentation in terms of boundary recall and under-segmentation error on publicly available benchmarks.
* 6 pages, accepted to IROS2017
View paper on