 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEvAct: Early Event-Based Action Recognition with High-Rate Two-Stream Spiking Neural Networks
Jul 10, 2025Recognizing human activities early is crucial for the safety and responsiveness of human-robot and human-machine interfaces. Due to their high temporal resolution and low latency, event-based vision sensors are a perfect match for this early recognition demand. However, most existing processing approaches accumulate events to low-rate frames or space-time voxels which limits the early prediction capabilities. In contrast, spiking neural networks (SNNs) can process the events at a high-rate for early predictions, but most works still fall short on final accuracy. In this work, we introduce a high-rate two-stream SNN which closes this gap by outperforming previous work by 2% in final accuracy on the large-scale THU EACT-50 dataset. We benchmark the SNNs within a novel early event-based recognition framework by reporting Top-1 and Top-5 recognition scores for growing observation time. Finally, we exemplify the impact of these methods on a real-world task of early action triggering for human motion capture in sports.
PoseGraphNet++: Enriching 3D Human Pose with Orientation Estimation
Aug 22, 2023Existing kinematic skeleton-based 3D human pose estimation methods only predict joint positions. Although this is sufficient to compute the yaw and pitch of the bone rotations, the roll around the axis of the bones remains unresolved by these methods. In this paper, we propose a novel 2D-to-3D lifting Graph Convolution Network named PoseGraphNet++ to predict the complete human pose including the joint positions and the bone orientations. We employ node and edge convolutions to utilize the joint and bone features. Our model is evaluated on multiple benchmark datasets, and its performance is either on par with or better than the state-of-the-art in terms of both position and rotation metrics. Through extensive ablation studies, we show that PoseGraphNet++ benefits from exploiting the mutual relationship between the joints and the bones.
Occlusion Robust 3D Human Pose Estimation with StridedPoseGraphFormer and Data Augmentation
Apr 24, 2023



Occlusion is an omnipresent challenge in 3D human pose estimation (HPE). In spite of the large amount of research dedicated to 3D HPE, only a limited number of studies address the problem of occlusion explicitly. To fill this gap, we propose to combine exploitation of spatio-temporal features with synthetic occlusion augmentation during training to deal with occlusion. To this end, we build a spatio-temporal 3D HPE model, StridedPoseGraphFormer based on graph convolution and transformers, and train it using occlusion augmentation. Unlike the existing occlusion-aware methods, that are only tested for limited occlusion, we extensively evaluate our method for varying degrees of occlusion. We show that our proposed method compares favorably with the state-of-the-art (SoA). Our experimental results also reveal that in the absence of any occlusion handling mechanism, the performance of SoA 3D HPE methods degrades significantly when they encounter occlusion.
Graph Neural Networks for Relational Inductive Bias in Vision-based Deep Reinforcement Learning of Robot Control
Mar 11, 2022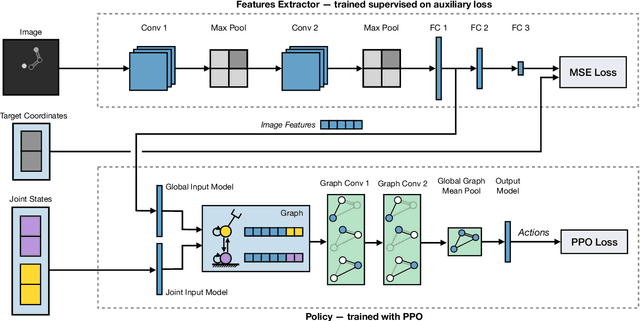
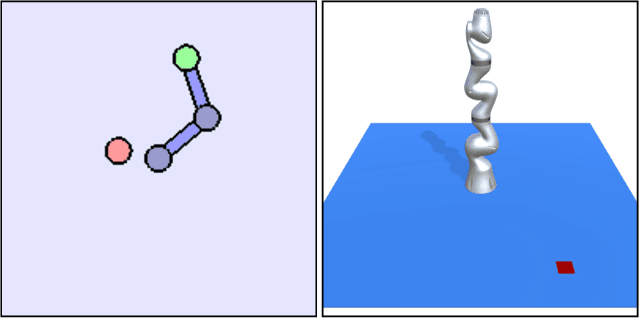
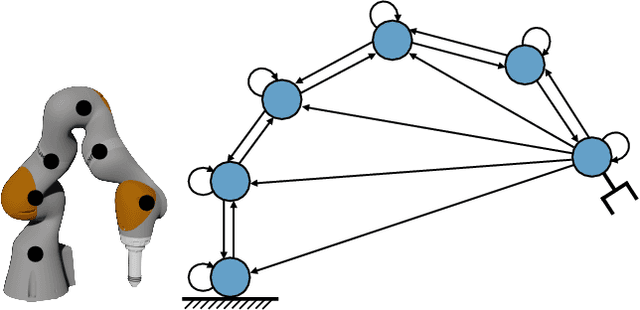
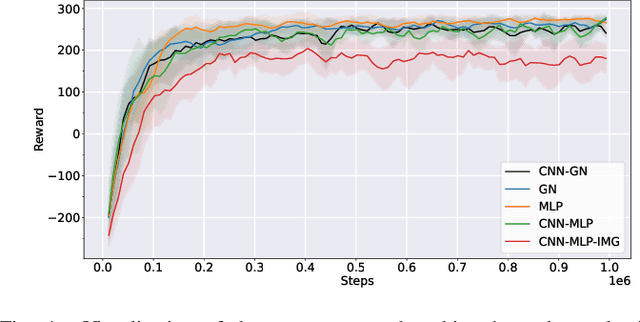
State-of-the-art reinforcement learning algorithms predominantly learn a policy from either a numerical state vector or images. Both approaches generally do not take structural knowledge of the task into account, which is especially prevalent in robotic applications and can benefit learning if exploited. This work introduces a neural network architecture that combines relational inductive bias and visual feedback to learn an efficient position control policy for robotic manipulation. We derive a graph representation that models the physical structure of the manipulator and combines the robot's internal state with a low-dimensional description of the visual scene generated by an image encoding network. On this basis, a graph neural network trained with reinforcement learning predicts joint velocities to control the robot. We further introduce an asymmetric approach of training the image encoder separately from the policy using supervised learning. Experimental results demonstrate that, for a 2-DoF planar robot in a geometrically simplistic 2D environment, a learned representation of the visual scene can replace access to the explicit coordinates of the reaching target without compromising on the quality and sample efficiency of the policy. We further show the ability of the model to improve sample efficiency for a 6-DoF robot arm in a visually realistic 3D environment.
Vogtareuth Rehab Depth Datasets: Benchmark for Marker-less Posture Estimation in Rehabilitation
Aug 23, 2021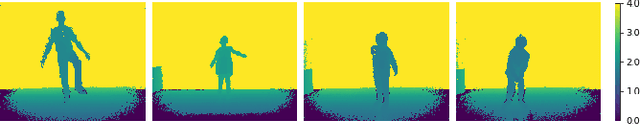
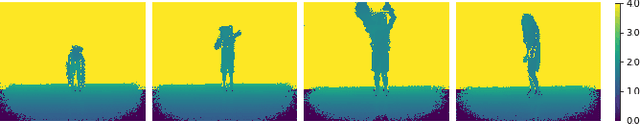
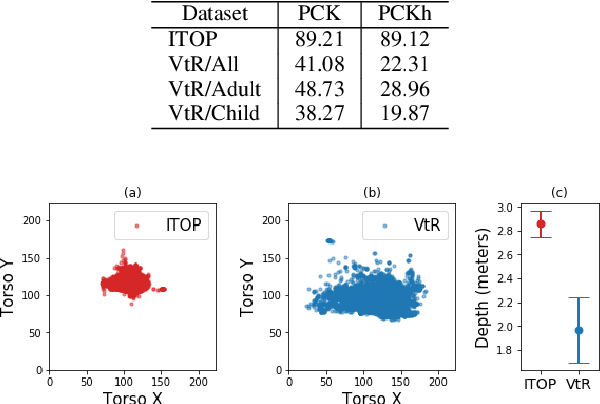
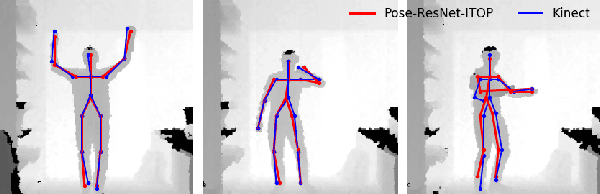
Posture estimation using a single depth camera has become a useful tool for analyzing movements in rehabilitation. Recent advances in posture estimation in computer vision research have been possible due to the availability of large-scale pose datasets. However, the complex postures involved in rehabilitation exercises are not represented in the existing benchmark depth datasets. To address this limitation, we propose two rehabilitation-specific pose datasets containing depth images and 2D pose information of patients, both adult and children, performing rehab exercises. We use a state-of-the-art marker-less posture estimation model which is trained on a non-rehab benchmark dataset. We evaluate it on our rehab datasets, and observe that the performance degrades significantly from non-rehab to rehab, highlighting the need for these datasets. We show that our dataset can be used to train pose models to detect rehab-specific complex postures. The datasets will be released for the benefit of the research community.
3D Human Pose Regression using Graph Convolutional Network
May 21, 2021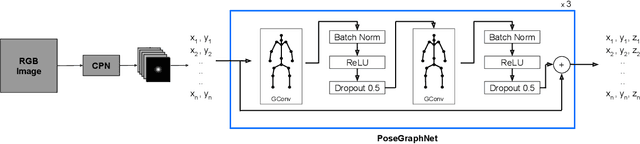

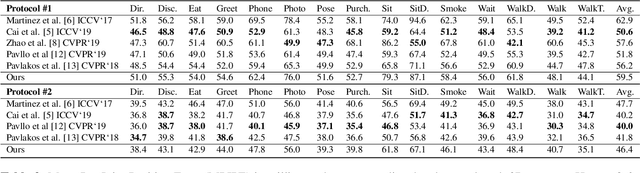
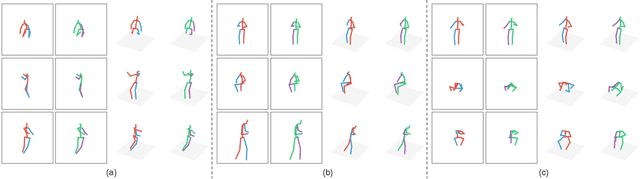
3D human pose estimation is a difficult task, due to challenges such as occluded body parts and ambiguous poses. Graph convolutional networks encode the structural information of the human skeleton in the form of an adjacency matrix, which is beneficial for better pose prediction. We propose one such graph convolutional network named PoseGraphNet for 3D human pose regression from 2D poses. Our network uses an adaptive adjacency matrix and kernels specific to neighbor groups. We evaluate our model on the Human3.6M dataset which is a standard dataset for 3D pose estimation. Our model's performance is close to the state-of-the-art, but with much fewer parameters. The model learns interesting adjacency relations between joints that have no physical connections, but are behaviorally similar.
Multi-label Object Attribute Classification using a Convolutional Neural Network
Nov 10, 2018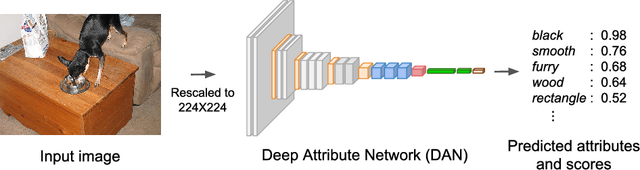
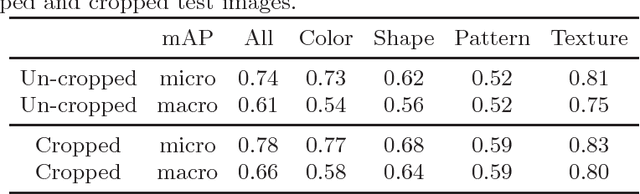
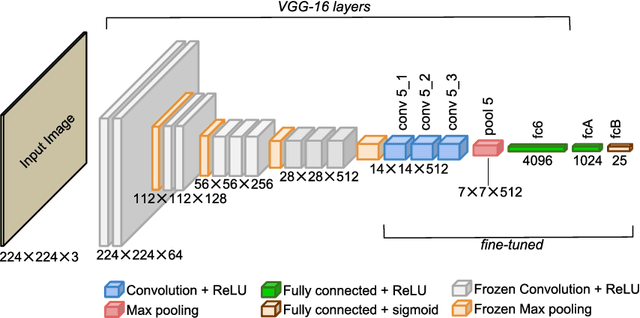
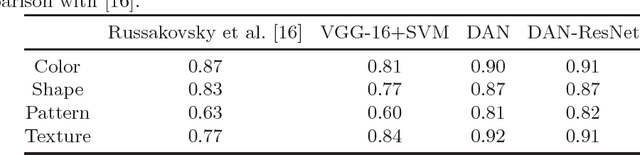
Objects of different classes can be described using a limited number of attributes such as color, shape, pattern, and texture. Learning to detect object attributes instead of only detecting objects can be helpful in dealing with a priori unknown objects. With this inspiration, a deep convolutional neural network for low-level object attribute classification, called the Deep Attribute Network (DAN), is proposed. Since object features are implicitly learned by object recognition networks, one such existing network is modified and fine-tuned for developing DAN. The performance of DAN is evaluated on the ImageNet Attribute and a-Pascal datasets. Experiments show that in comparison with state-of-the-art methods, the proposed model achieves better results.