 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgical tool classification and localization: results and methods from the MICCAI 2022 SurgToolLoc challenge
May 11, 2023



The ability to automatically detect and track surgical instruments in endoscopic videos can enable transformational interventions. Assessing surgical performance and efficiency, identifying skilled tool use and choreography, and planning operational and logistical aspects of OR resources are just a few of the applications that could benefit. Unfortunately, obtaining the annotations needed to train machine learning models to identify and localize surgical tools is a difficult task. Annotating bounding boxes frame-by-frame is tedious and time-consuming, yet large amounts of data with a wide variety of surgical tools and surgeries must be captured for robust training. Moreover, ongoing annotator training is needed to stay up to date with surgical instrument innovation. In robotic-assisted surgery, however, potentially informative data like timestamps of instrument installation and removal can be programmatically harvested. The ability to rely on tool installation data alone would significantly reduce the workload to train robust tool-tracking models. With this motivation in mind we invited the surgical data science community to participate in the challenge, SurgToolLoc 2022. The goal was to leverage tool presence data as weak labels for machine learning models trained to detect tools and localize them in video frames with bounding boxes. We present the results of this challenge along with many of the team's efforts. We conclude by discussing these results in the broader context of machine learning and surgical data science. The training data used for this challenge consisting of 24,695 video clips with tool presence labels is also being released publicly and can be accessed at https://console.cloud.google.com/storage/browser/isi-surgtoolloc-2022.
Segmenting Medical Instruments in Minimally Invasive Surgeries using AttentionMask
Mar 21, 2022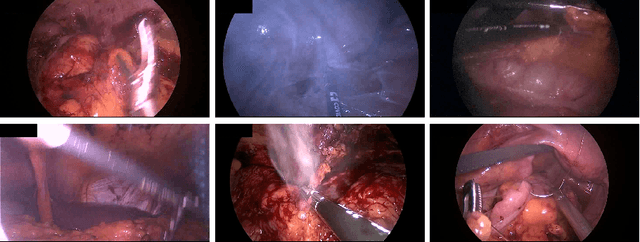
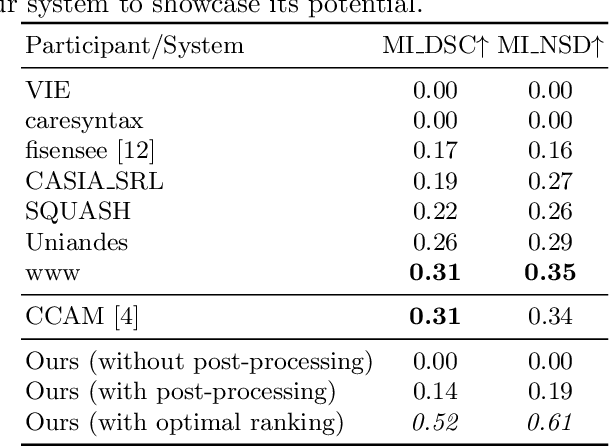
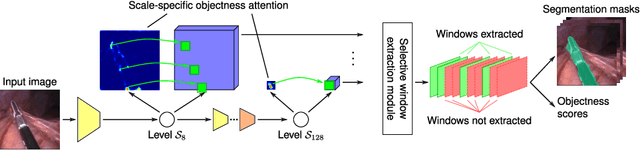
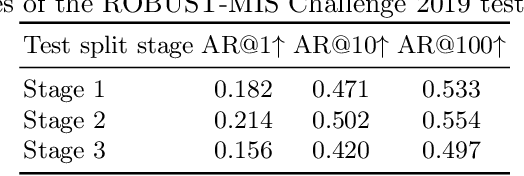
Precisely locating and segmenting medical instruments in images of minimally invasive surgeries, medical instrument segmentation, is an essential first step for several tasks in medical image processing. However, image degradations, small instruments, and the generalization between different surgery types make medical instrument segmentation challenging. To cope with these challenges, we adapt the object proposal generation system AttentionMask and propose a dedicated post-processing to select promising proposals. The results on the ROBUST-MIS Challenge 2019 show that our adapted AttentionMask system is a strong foundation for generating state-of-the-art performance. Our evaluation in an object proposal generation framework shows that our adapted AttentionMask system is robust to image degradations, generalizes well to unseen types of surgeries, and copes well with small instruments.
Multi-scale fully convolutional neural networks for histopathology image segmentation: from nuclear aberrations to the global tissue architecture
Sep 24, 2019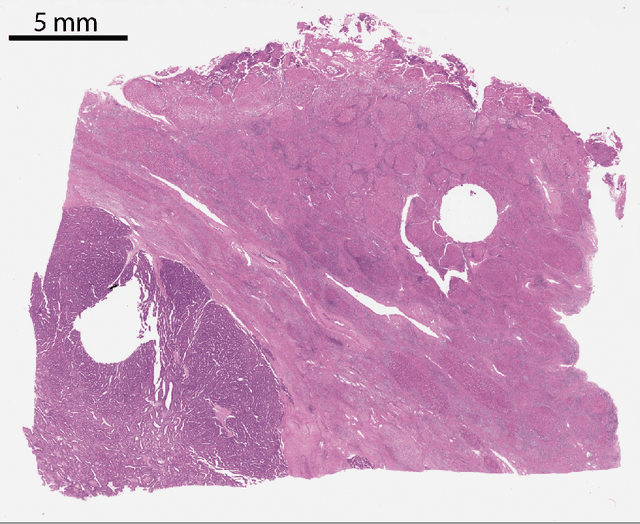
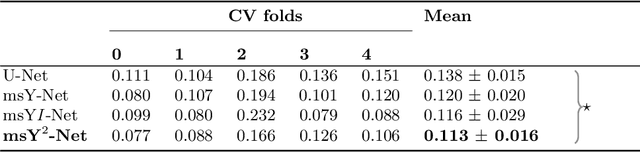
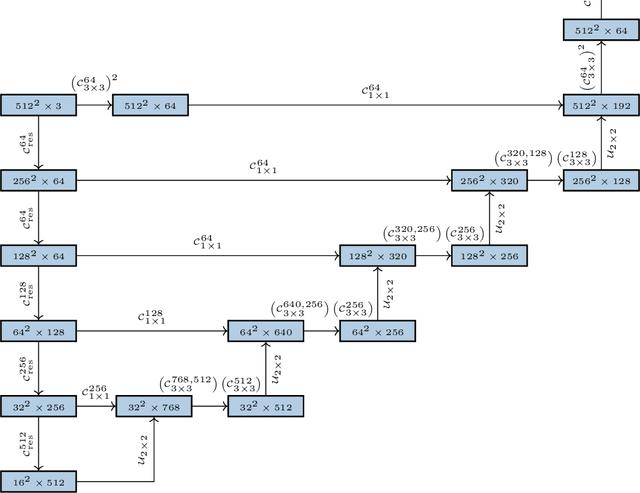
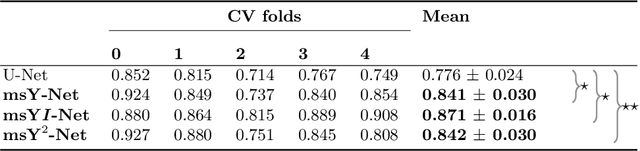
Histopathologic diagnosis is dependent on simultaneous information from a broad range of scales, ranging from nuclear aberrations ($\approx \mathcal{O}(0.1 \mu m)$) over cellular structures ($\approx \mathcal{O}(10\mu m)$) to the global tissue architecture ($\gtrapprox \mathcal{O}(1 mm)$). Bearing in mind which information is employed by human pathologists, we introduce and examine different strategies for the integration of multiple and widely separate spatial scales into common U-Net-based architectures. Based on this, we present a family of new, end-to-end trainable, multi-scale multi-encoder fully-convolutional neural networks for human modus operandi-inspired computer vision in histopathology.
Skin Lesion Classification Using CNNs with Patch-Based Attention and Diagnosis-Guided Loss Weighting
May 09, 2019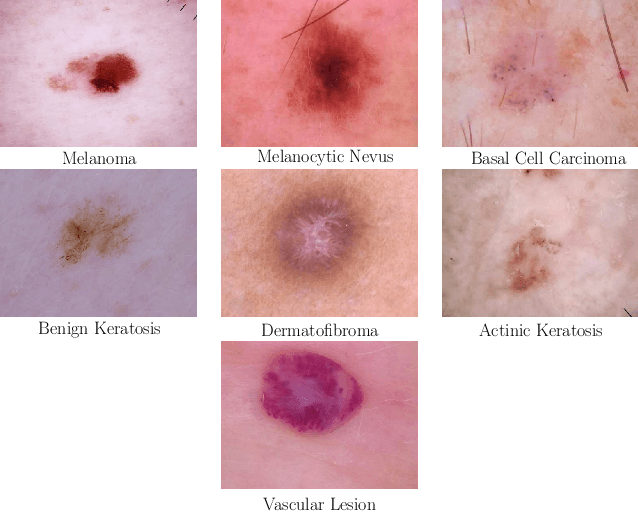
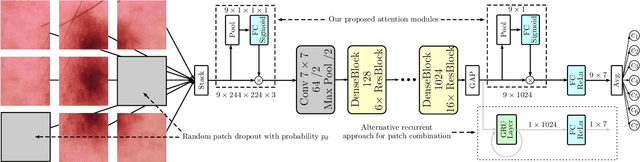
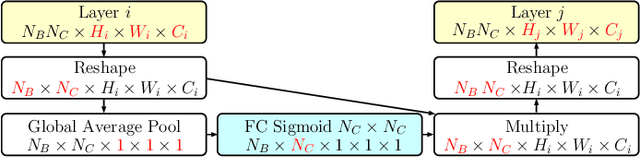
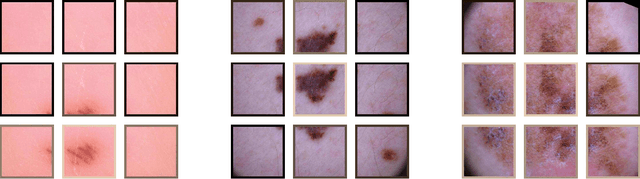
Objective: This work addresses two key problems of skin lesion classification. The first problem is the effective use of high-resolution images with pretrained standard architectures for image classification. The second problem is the high class imbalance encountered in real-world multi-class datasets. Methods: To use high-resolution images, we propose a novel patch-based attention architecture that provides global context between small, high-resolution patches. We modify three pretrained architectures and study the performance of patch-based attention. To counter class imbalance problems, we compare oversampling, balanced batch sampling, and class-specific loss weighting. Additionally, we propose a novel diagnosis-guided loss weighting method which takes the method used for ground-truth annotation into account. Results: Our patch-based attention mechanism outperforms previous methods and improves the mean sensitivity by 7%. Class balancing significantly improves the mean sensitivity and we show that our diagnosis-guided loss weighting method improves the mean sensitivity by 3% over normal loss balancing. Conclusion: The novel patch-based attention mechanism can be integrated into pretrained architectures and provides global context between local patches while outperforming other patch-based methods. Hence, pretrained architectures can be readily used with high-resolution images without downsampling. The new diagnosis-guided loss weighting method outperforms other methods and allows for effective training when facing class imbalance. Significance: The proposed methods improve automatic skin lesion classification. They can be extended to other clinical applications where high-resolution image data and class imbalance are relevant.
Skin Lesion Diagnosis using Ensembles, Unscaled Multi-Crop Evaluation and Loss Weighting
Aug 05, 2018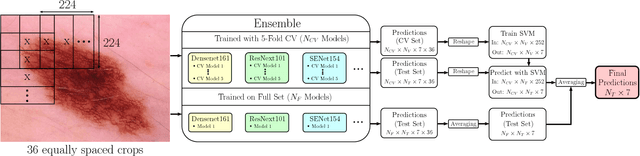
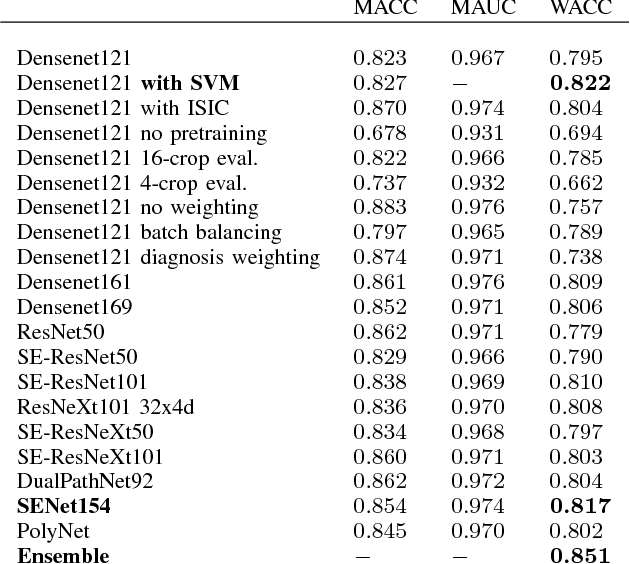
In this paper we present the methods of our submission to the ISIC 2018 challenge for skin lesion diagnosis (Task 3). The dataset consists of 10000 images with seven image-level classes to be distinguished by an automated algorithm. We employ an ensemble of convolutional neural networks for this task. In particular, we fine-tune pretrained state-of-the-art deep learning models such as Densenet, SENet and ResNeXt. We identify heavy class imbalance as a key problem for this challenge and consider multiple balancing approaches such as loss weighting and balanced batch sampling. Another important feature of our pipeline is the use of a vast amount of unscaled crops for evaluation. Last, we consider meta learning approaches for the final predictions. Our team placed second at the challenge while being the best approach using only publicly available data.