 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-ReS: Self-Reflection in Large Vision-Language Models for Long Video Understanding
Mar 26, 2025Large Vision-Language Models (LVLMs) demonstrate remarkable performance in short-video tasks such as video question answering, but struggle in long-video understanding. The linear frame sampling strategy, conventionally used by LVLMs, fails to account for the non-linear distribution of key events in video data, often introducing redundant or irrelevant information in longer contexts while risking the omission of critical events in shorter ones. To address this, we propose SelfReS, a non-linear spatiotemporal self-reflective sampling method that dynamically selects key video fragments based on user prompts. Unlike prior approaches, SelfReS leverages the inherently sparse attention maps of LVLMs to define reflection tokens, enabling relevance-aware token selection without requiring additional training or external modules. Experiments demonstrate that SelfReS can be seamlessly integrated into strong base LVLMs, improving long-video task accuracy and achieving up to 46% faster inference speed within the same GPU memory budget.
Zero-Shot Action Recognition in Surveillance Videos
Oct 28, 2024



The growing demand for surveillance in public spaces presents significant challenges due to the shortage of human resources. Current AI-based video surveillance systems heavily rely on core computer vision models that require extensive finetuning, which is particularly difficult in surveillance settings due to limited datasets and difficult setting (viewpoint, low quality, etc.). In this work, we propose leveraging Large Vision-Language Models (LVLMs), known for their strong zero and few-shot generalization, to tackle video understanding tasks in surveillance. Specifically, we explore VideoLLaMA2, a state-of-the-art LVLM, and an improved token-level sampling method, Self-Reflective Sampling (Self-ReS). Our experiments on the UCF-Crime dataset show that VideoLLaMA2 represents a significant leap in zero-shot performance, with 20% boost over the baseline. Self-ReS additionally increases zero-shot action recognition performance to 44.6%. These results highlight the potential of LVLMs, paired with improved sampling techniques, for advancing surveillance video analysis in diverse scenarios.
Spatial Adaptation Layer: Interpretable Domain Adaptation For Biosignal Sensor Array Applications
Sep 12, 2024



Biosignal acquisition is key for healthcare applications and wearable devices, with machine learning offering promising methods for processing signals like surface electromyography (sEMG) and electroencephalography (EEG). Despite high within-session performance, intersession performance is hindered by electrode shift, a known issue across modalities. Existing solutions often require large and expensive datasets and/or lack robustness and interpretability. Thus, we propose the Spatial Adaptation Layer (SAL), which can be prepended to any biosignal array model and learns a parametrized affine transformation at the input between two recording sessions. We also introduce learnable baseline normalization (LBN) to reduce baseline fluctuations. Tested on two HD-sEMG gesture recognition datasets, SAL and LBN outperform standard fine-tuning on regular arrays, achieving competitive performance even with a logistic regressor, with orders of magnitude less, physically interpretable parameters. Our ablation study shows that forearm circumferential translations account for the majority of performance improvements, in line with sEMG physiological expectations.
Tackling Electrode Shift In Gesture Recognition with HD-EMG Electrode Subsets
Jan 05, 2024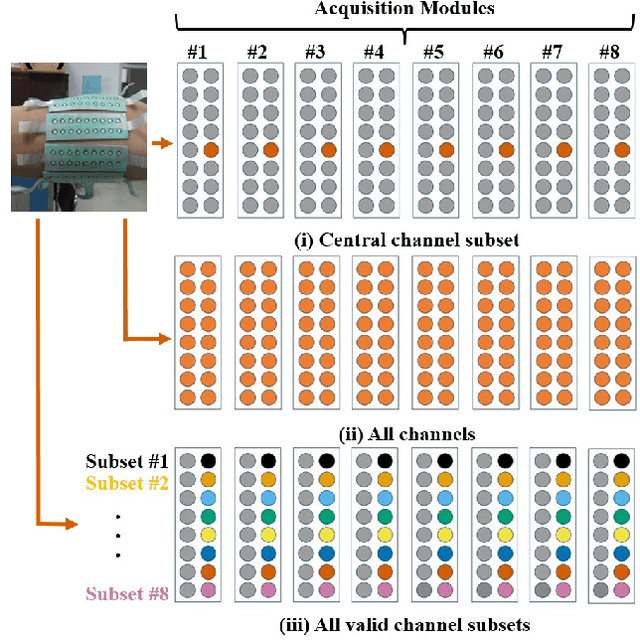

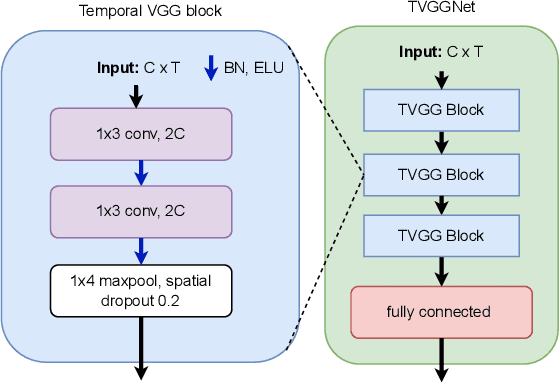
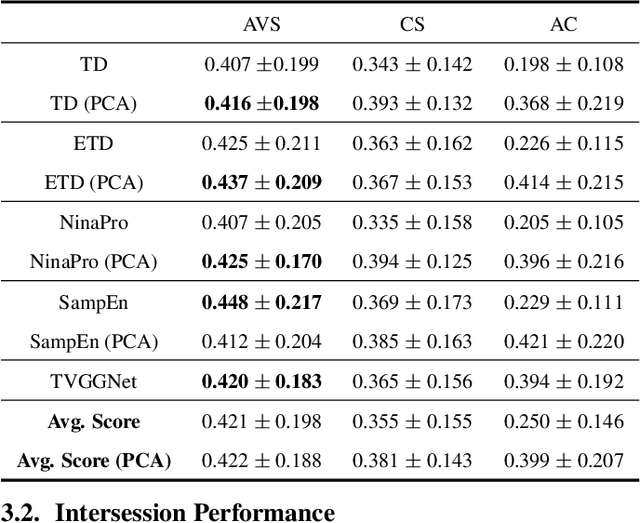
sEMG pattern recognition algorithms have been explored extensively in decoding movement intent, yet are known to be vulnerable to changing recording conditions, exhibiting significant drops in performance across subjects, and even across sessions. Multi-channel surface EMG, also referred to as high-density sEMG (HD-sEMG) systems, have been used to improve performance with the information collected through the use of additional electrodes. However, a lack of robustness is ever present due to limited datasets and the difficulties in addressing sources of variability, such as electrode placement. In this study, we propose training on a collection of input channel subsets and augmenting our training distribution with data from different electrode locations, simultaneously targeting electrode shift and reducing input dimensionality. Our method increases robustness against electrode shift and results in significantly higher intersession performance across subjects and classification algorithms.
* 5 pages
It's easy to fool yourself: Case studies on identifying bias and confounding in bio-medical datasets
Dec 12, 2019
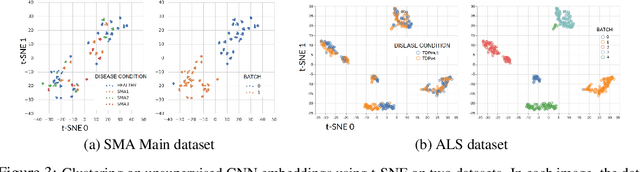
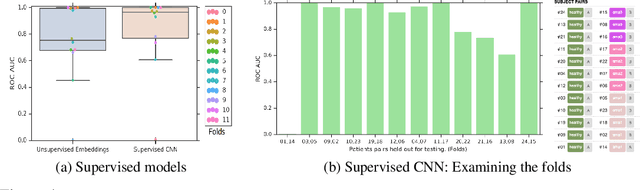
Confounding variables are a well known source of nuisance in biomedical studies. They present an even greater challenge when we combine them with black-box machine learning techniques that operate on raw data. This work presents two case studies. In one, we discovered biases arising from systematic errors in the data generation process. In the other, we found a spurious source of signal unrelated to the prediction task at hand. In both cases, our prediction models performed well but under careful examination hidden confounders and biases were revealed. These are cautionary tales on the limits of using machine learning techniques on raw data from scientific experiments.