 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating scientific discovery with the common task framework
Nov 06, 2025Machine learning (ML) and artificial intelligence (AI) algorithms are transforming and empowering the characterization and control of dynamic systems in the engineering, physical, and biological sciences. These emerging modeling paradigms require comparative metrics to evaluate a diverse set of scientific objectives, including forecasting, state reconstruction, generalization, and control, while also considering limited data scenarios and noisy measurements. We introduce a common task framework (CTF) for science and engineering, which features a growing collection of challenge data sets with a diverse set of practical and common objectives. The CTF is a critically enabling technology that has contributed to the rapid advance of ML/AI algorithms in traditional applications such as speech recognition, language processing, and computer vision. There is a critical need for the objective metrics of a CTF to compare the diverse algorithms being rapidly developed and deployed in practice today across science and engineering.
The Temporal Structure of Language Processing in the Human Brain Corresponds to The Layered Hierarchy of Deep Language Models
Oct 11, 2023Deep Language Models (DLMs) provide a novel computational paradigm for understanding the mechanisms of natural language processing in the human brain. Unlike traditional psycholinguistic models, DLMs use layered sequences of continuous numerical vectors to represent words and context, allowing a plethora of emerging applications such as human-like text generation. In this paper we show evidence that the layered hierarchy of DLMs may be used to model the temporal dynamics of language comprehension in the brain by demonstrating a strong correlation between DLM layer depth and the time at which layers are most predictive of the human brain. Our ability to temporally resolve individual layers benefits from our use of electrocorticography (ECoG) data, which has a much higher temporal resolution than noninvasive methods like fMRI. Using ECoG, we record neural activity from participants listening to a 30-minute narrative while also feeding the same narrative to a high-performing DLM (GPT2-XL). We then extract contextual embeddings from the different layers of the DLM and use linear encoding models to predict neural activity. We first focus on the Inferior Frontal Gyrus (IFG, or Broca's area) and then extend our model to track the increasing temporal receptive window along the linguistic processing hierarchy from auditory to syntactic and semantic areas. Our results reveal a connection between human language processing and DLMs, with the DLM's layer-by-layer accumulation of contextual information mirroring the timing of neural activity in high-order language areas.
Scientific Discovery by Generating Counterfactuals using Image Translation
Jul 10, 2020
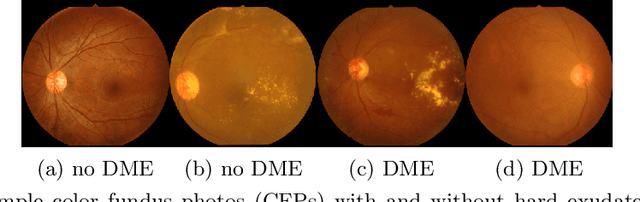
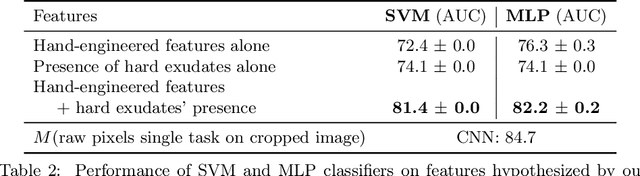
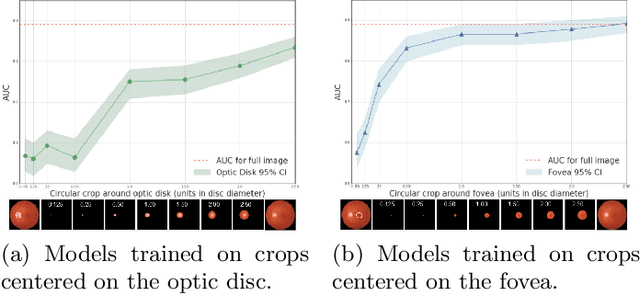
Model explanation techniques play a critical role in understanding the source of a model's performance and making its decisions transparent. Here we investigate if explanation techniques can also be used as a mechanism for scientific discovery. We make three contributions: first, we propose a framework to convert predictions from explanation techniques to a mechanism of discovery. Second, we show how generative models in combination with black-box predictors can be used to generate hypotheses (without human priors) that can be critically examined. Third, with these techniques we study classification models for retinal images predicting Diabetic Macular Edema (DME), where recent work showed that a CNN trained on these images is likely learning novel features in the image. We demonstrate that the proposed framework is able to explain the underlying scientific mechanism, thus bridging the gap between the model's performance and human understanding.
* Accepted at MICCAI 2020. This version combines camera-ready and supplement
It's easy to fool yourself: Case studies on identifying bias and confounding in bio-medical datasets
Dec 12, 2019
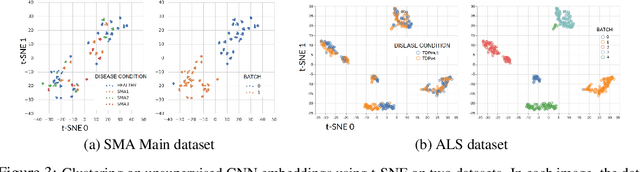
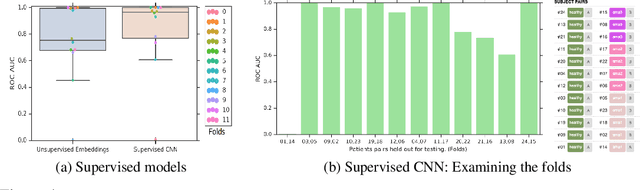
Confounding variables are a well known source of nuisance in biomedical studies. They present an even greater challenge when we combine them with black-box machine learning techniques that operate on raw data. This work presents two case studies. In one, we discovered biases arising from systematic errors in the data generation process. In the other, we found a spurious source of signal unrelated to the prediction task at hand. In both cases, our prediction models performed well but under careful examination hidden confounders and biases were revealed. These are cautionary tales on the limits of using machine learning techniques on raw data from scientific experiments.
Personalizing ASR for Dysarthric and Accented Speech with Limited Data
Jul 31, 2019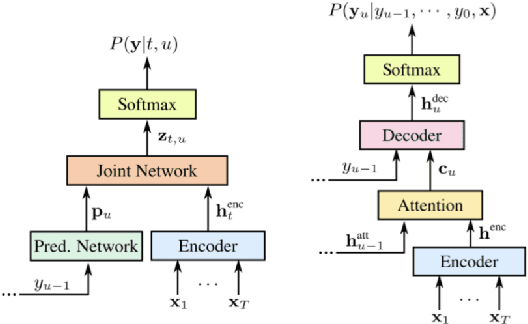
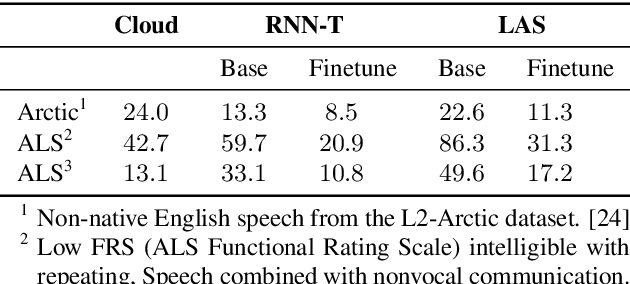
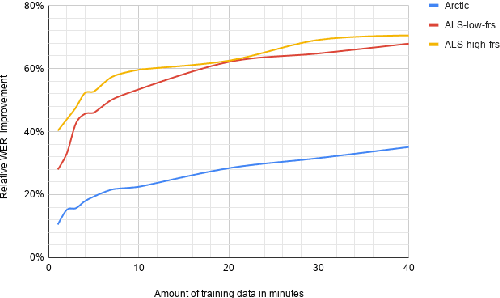
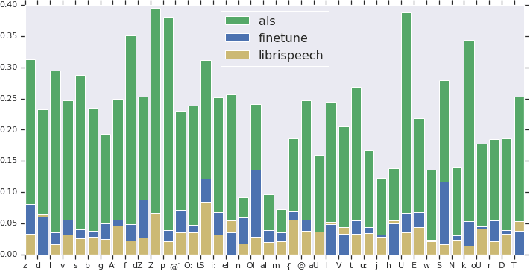
Automatic speech recognition (ASR) systems have dramatically improved over the last few years. ASR systems are most often trained from 'typical' speech, which means that underrepresented groups don't experience the same level of improvement. In this paper, we present and evaluate finetuning techniques to improve ASR for users with non-standard speech. We focus on two types of non-standard speech: speech from people with amyotrophic lateral sclerosis (ALS) and accented speech. We train personalized models that achieve 62% and 35% relative WER improvement on these two groups, bringing the absolute WER for ALS speakers, on a test set of message bank phrases, down to 10% for mild dysarthria and 20% for more serious dysarthria. We show that 71% of the improvement comes from only 5 minutes of training data. Finetuning a particular subset of layers (with many fewer parameters) often gives better results than finetuning the entire model. This is the first step towards building state of the art ASR models for dysarthric speech.