 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Personalization of Automatic Speech Recognition Models for Disordered Speech
Jun 18, 2021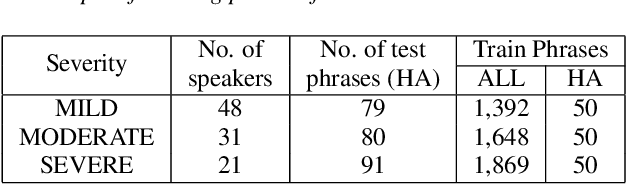

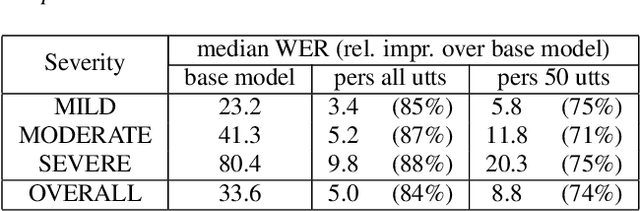

While current state-of-the-art Automatic Speech Recognition (ASR) systems achieve high accuracy on typical speech, they suffer from significant performance degradation on disordered speech and other atypical speech patterns. Personalization of ASR models, a commonly applied solution to this problem, is usually performed in a server-based training environment posing problems around data privacy, delayed model-update times, and communication cost for copying data and models between mobile device and server infrastructure. In this paper, we present an approach to on-device based ASR personalization with very small amounts of speaker-specific data. We test our approach on a diverse set of 100 speakers with disordered speech and find median relative word error rate improvement of 71% with only 50 short utterances required per speaker. When tested on a voice-controlled home automation platform, on-device personalized models show a median task success rate of 81%, compared to only 40% of the unadapted models.
Personalizing ASR for Dysarthric and Accented Speech with Limited Data
Jul 31, 2019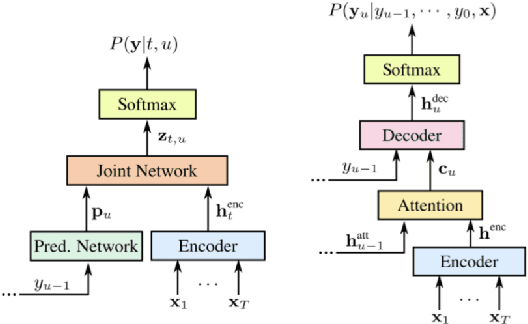
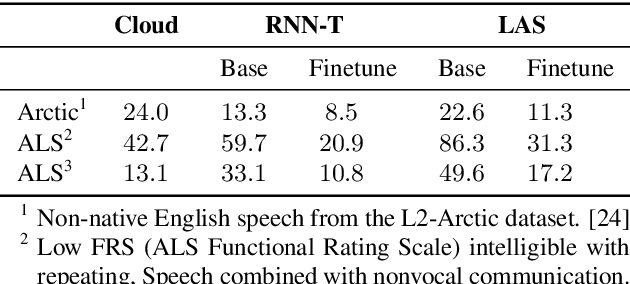
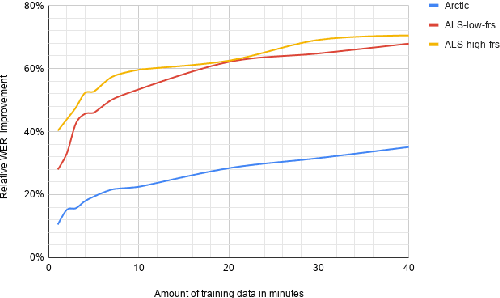
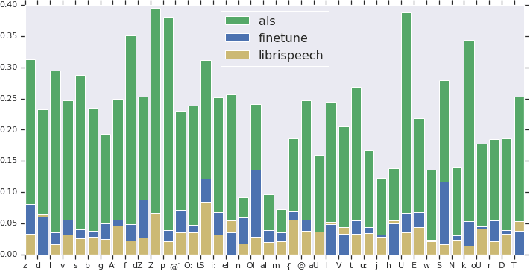
Automatic speech recognition (ASR) systems have dramatically improved over the last few years. ASR systems are most often trained from 'typical' speech, which means that underrepresented groups don't experience the same level of improvement. In this paper, we present and evaluate finetuning techniques to improve ASR for users with non-standard speech. We focus on two types of non-standard speech: speech from people with amyotrophic lateral sclerosis (ALS) and accented speech. We train personalized models that achieve 62% and 35% relative WER improvement on these two groups, bringing the absolute WER for ALS speakers, on a test set of message bank phrases, down to 10% for mild dysarthria and 20% for more serious dysarthria. We show that 71% of the improvement comes from only 5 minutes of training data. Finetuning a particular subset of layers (with many fewer parameters) often gives better results than finetuning the entire model. This is the first step towards building state of the art ASR models for dysarthric speech.