 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Learning a Universal Non-Semantic Representation of Speech
Mar 02, 2020
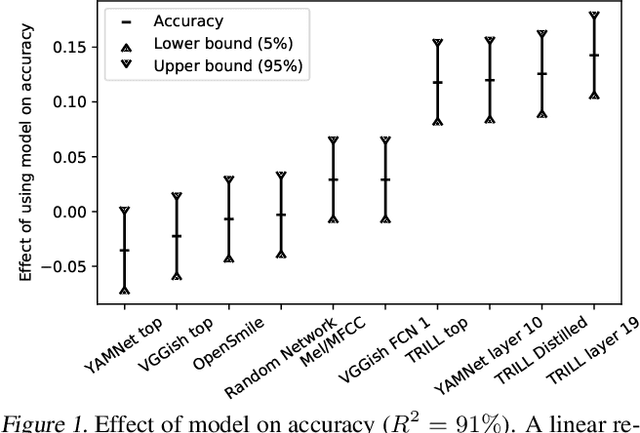
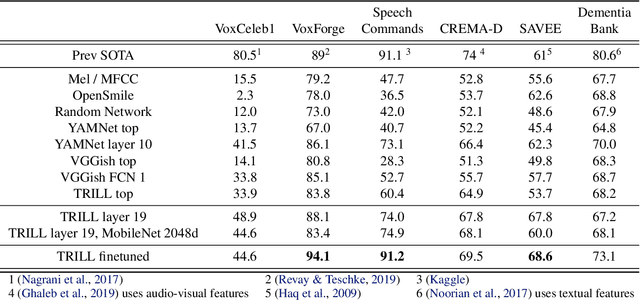
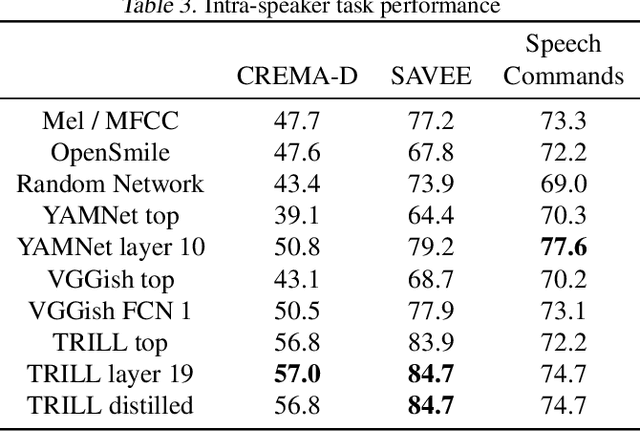
The ultimate goal of transfer learning is to reduce labeled data requirements by exploiting a pre-existing embedding model trained for different datasets or tasks. While significant progress has been made in the visual and language domains, the speech community has yet to identify a strategy with wide-reaching applicability across tasks. This paper describes a representation of speech based on an unsupervised triplet-loss objective, which exceeds state-of-the-art performance on a number of transfer learning tasks drawn from the non-semantic speech domain. The embedding is trained on a publicly available dataset, and it is tested on a variety of low-resource downstream tasks, including personalization tasks and medical domain. The model will be publicly released.
Personalizing ASR for Dysarthric and Accented Speech with Limited Data
Jul 31, 2019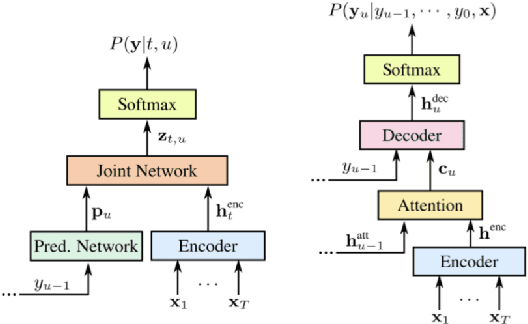
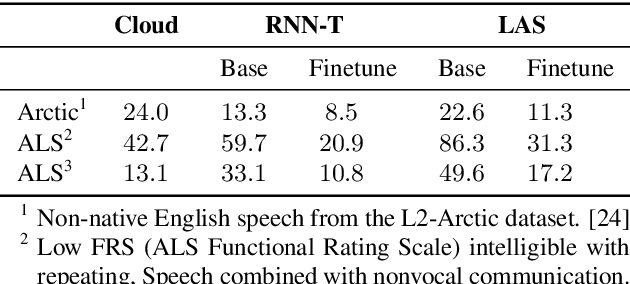
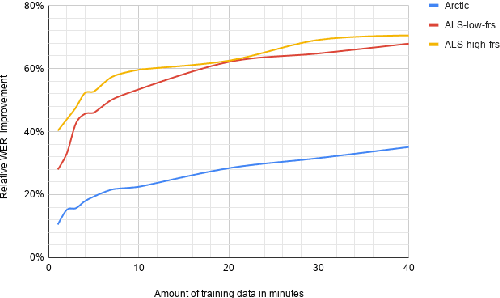
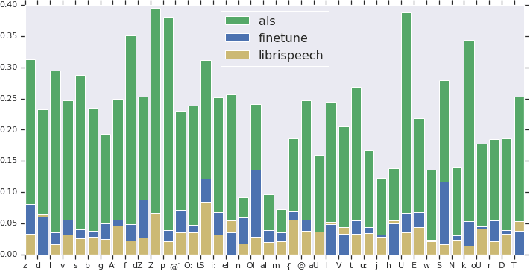
Automatic speech recognition (ASR) systems have dramatically improved over the last few years. ASR systems are most often trained from 'typical' speech, which means that underrepresented groups don't experience the same level of improvement. In this paper, we present and evaluate finetuning techniques to improve ASR for users with non-standard speech. We focus on two types of non-standard speech: speech from people with amyotrophic lateral sclerosis (ALS) and accented speech. We train personalized models that achieve 62% and 35% relative WER improvement on these two groups, bringing the absolute WER for ALS speakers, on a test set of message bank phrases, down to 10% for mild dysarthria and 20% for more serious dysarthria. We show that 71% of the improvement comes from only 5 minutes of training data. Finetuning a particular subset of layers (with many fewer parameters) often gives better results than finetuning the entire model. This is the first step towards building state of the art ASR models for dysarthric speech.