 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient and Effective Encoder Model for Vision and Language Tasks in the Remote Sensing Domain
Dec 17, 2025The remote sensing community has recently seen the emergence of methods based on Large Vision and Language Models (LVLMs) that can address multiple tasks at the intersection of computer vision and natural language processing. To fully exploit the potential of such models, a significant focus has been given to the collection of large amounts of training data that cover multiple remote sensing-specific tasks, such as image captioning or visual question answering. However, the cost of using and training LVLMs is high, due to the large number of parameters. While multiple parameter-efficient adaptation techniques have been explored, the computational costs of training and inference with these models can remain prohibitive for most institutions. In this work, we explore the use of encoder-only architectures and propose a model that can effectively address multi-task learning while remaining compact in terms of the number of parameters. In particular, our model tackles combinations of tasks that are not typically explored in a unified model: the generation of text from remote sensing images and cross-modal retrieval. The results of our GeoMELT model - named from Multi-task Efficient Learning Transformer - in established benchmarks confirm the efficacy and efficiency of the proposed approach.
Multilingual Vision-Language Pre-training for the Remote Sensing Domain
Oct 30, 2024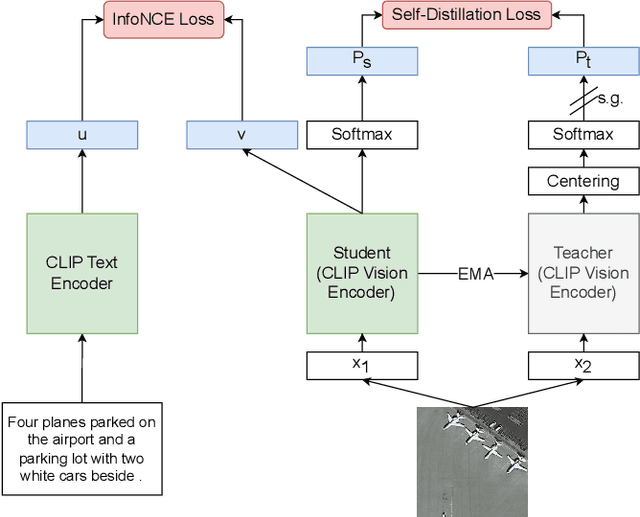
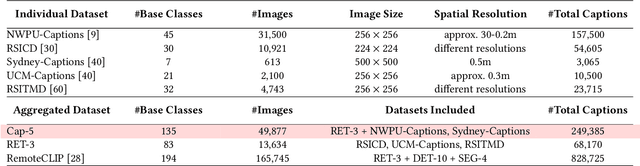

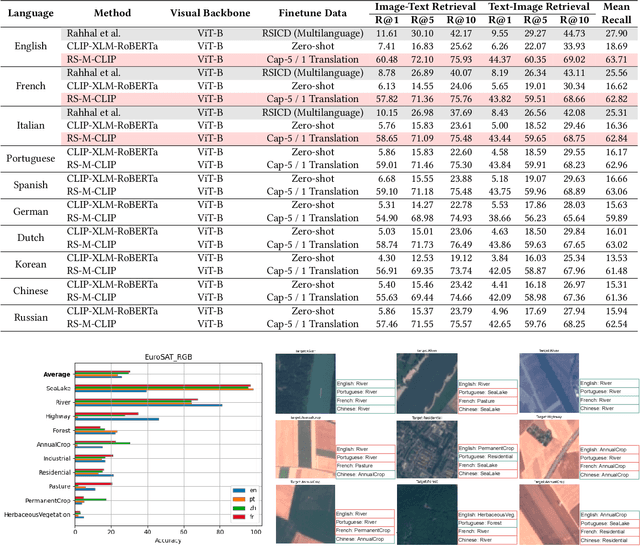
Methods based on Contrastive Language-Image Pre-training (CLIP) are nowadays extensively used in support of vision-and-language tasks involving remote sensing data, such as cross-modal retrieval. The adaptation of CLIP to this specific domain has relied on model fine-tuning with the standard contrastive objective, using existing human-labeled image-caption datasets, or using synthetic data corresponding to image-caption pairs derived from other annotations over remote sensing images (e.g., object classes). The use of different pre-training mechanisms has received less attention, and only a few exceptions have considered multilingual inputs. This work proposes a novel vision-and-language model for the remote sensing domain, exploring the fine-tuning of a multilingual CLIP model and testing the use of a self-supervised method based on aligning local and global representations from individual input images, together with the standard CLIP objective. Model training relied on assembling pre-existing datasets of remote sensing images paired with English captions, followed by the use of automated machine translation into nine additional languages. We show that translated data is indeed helpful, e.g. improving performance also on English. Our resulting model, which we named Remote Sensing Multilingual CLIP (RS-M-CLIP), obtains state-of-the-art results in a variety of vision-and-language tasks, including cross-modal and multilingual image-text retrieval, or zero-shot image classification.
Large Language Models for Captioning and Retrieving Remote Sensing Images
Feb 09, 2024Image captioning and cross-modal retrieval are examples of tasks that involve the joint analysis of visual and linguistic information. In connection to remote sensing imagery, these tasks can help non-expert users in extracting relevant Earth observation information for a variety of applications. Still, despite some previous efforts, the development and application of vision and language models to the remote sensing domain have been hindered by the relatively small size of the available datasets and models used in previous studies. In this work, we propose RS-CapRet, a Vision and Language method for remote sensing tasks, in particular image captioning and text-image retrieval. We specifically propose to use a highly capable large decoder language model together with image encoders adapted to remote sensing imagery through contrastive language-image pre-training. To bridge together the image encoder and language decoder, we propose training simple linear layers with examples from combining different remote sensing image captioning datasets, keeping the other parameters frozen. RS-CapRet can then generate descriptions for remote sensing images and retrieve images from textual descriptions, achieving SOTA or competitive performance with existing methods. Qualitative results illustrate that RS-CapRet can effectively leverage the pre-trained large language model to describe remote sensing images, retrieve them based on different types of queries, and also show the ability to process interleaved sequences of images and text in a dialogue manner.