 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Vision-Language Pre-training for the Remote Sensing Domain
Paper and Code
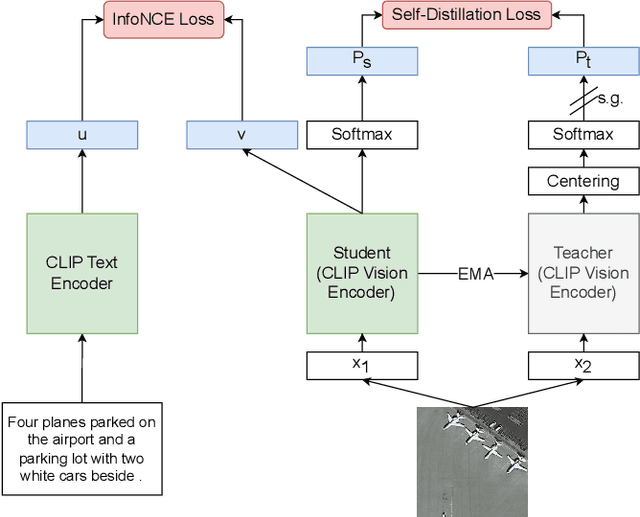
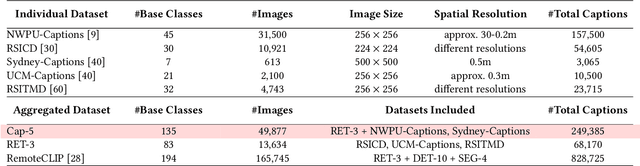

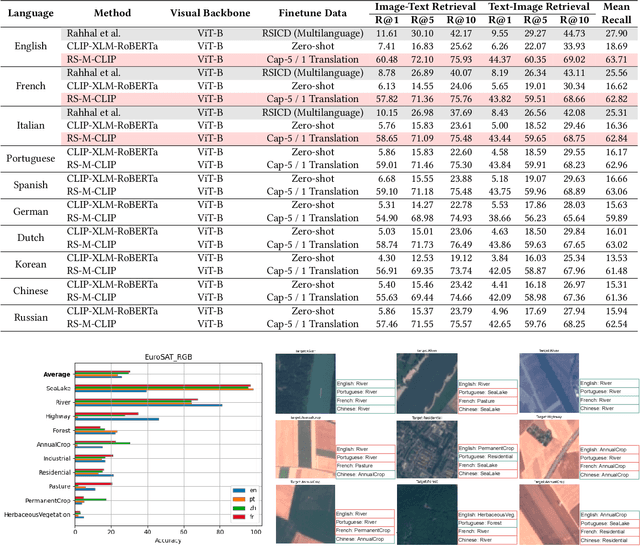
Methods based on Contrastive Language-Image Pre-training (CLIP) are nowadays extensively used in support of vision-and-language tasks involving remote sensing data, such as cross-modal retrieval. The adaptation of CLIP to this specific domain has relied on model fine-tuning with the standard contrastive objective, using existing human-labeled image-caption datasets, or using synthetic data corresponding to image-caption pairs derived from other annotations over remote sensing images (e.g., object classes). The use of different pre-training mechanisms has received less attention, and only a few exceptions have considered multilingual inputs. This work proposes a novel vision-and-language model for the remote sensing domain, exploring the fine-tuning of a multilingual CLIP model and testing the use of a self-supervised method based on aligning local and global representations from individual input images, together with the standard CLIP objective. Model training relied on assembling pre-existing datasets of remote sensing images paired with English captions, followed by the use of automated machine translation into nine additional languages. We show that translated data is indeed helpful, e.g. improving performance also on English. Our resulting model, which we named Remote Sensing Multilingual CLIP (RS-M-CLIP), obtains state-of-the-art results in a variety of vision-and-language tasks, including cross-modal and multilingual image-text retrieval, or zero-shot image classification.