 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Fuzzy Fingerprints: Benchmarking Text-Based Identification in Multiparty Dialogues
Apr 21, 2025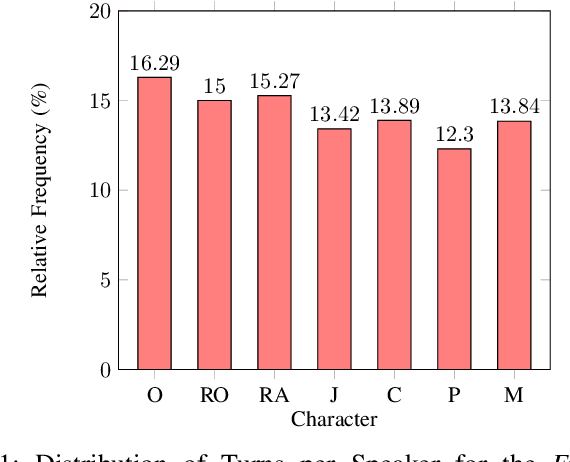
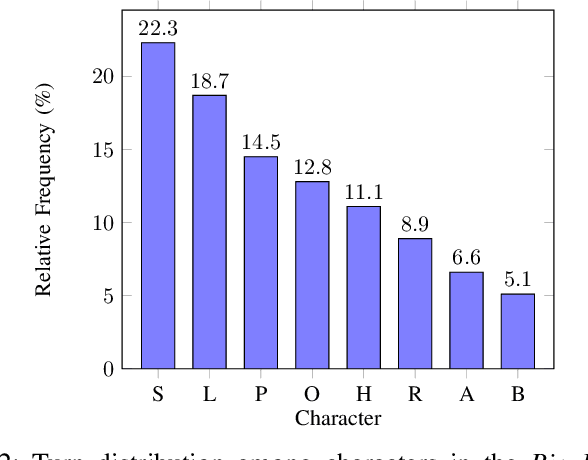
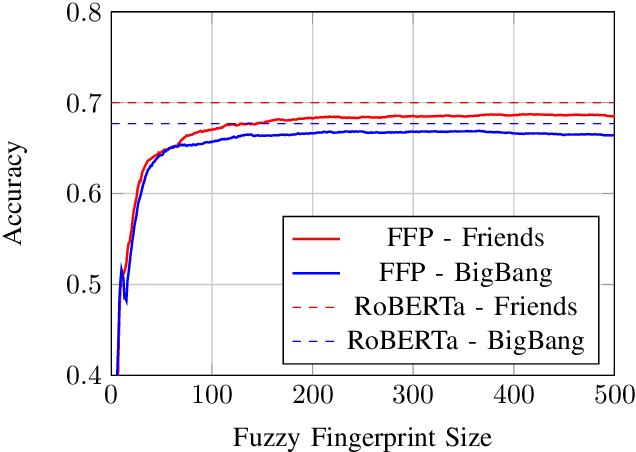
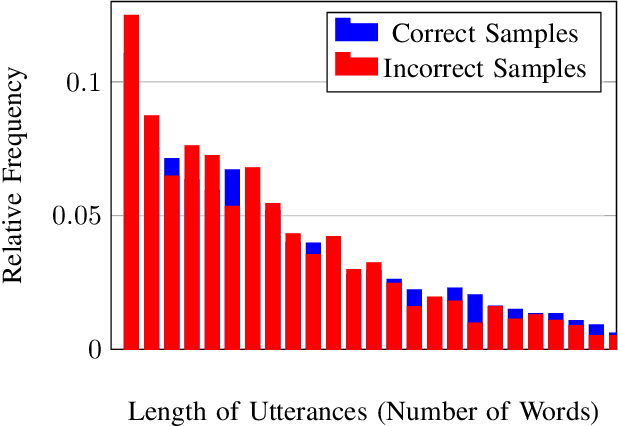
Speaker identification using voice recordings leverages unique acoustic features, but this approach fails when only textual data is available. Few approaches have attempted to tackle the problem of identifying speakers solely from text, and the existing ones have primarily relied on traditional methods. In this work, we explore the use of fuzzy fingerprints from large pre-trained models to improve text-based speaker identification. We integrate speaker-specific tokens and context-aware modeling, demonstrating that conversational context significantly boosts accuracy, reaching 70.6% on the Friends dataset and 67.7% on the Big Bang Theory dataset. Additionally, we show that fuzzy fingerprints can approximate full fine-tuning performance with fewer hidden units, offering improved interpretability. Finally, we analyze ambiguous utterances and propose a mechanism to detect speaker-agnostic lines. Our findings highlight key challenges and provide insights for future improvements in text-based speaker identification.
PGTask: Introducing the Task of Profile Generation from Dialogues
Apr 13, 2023

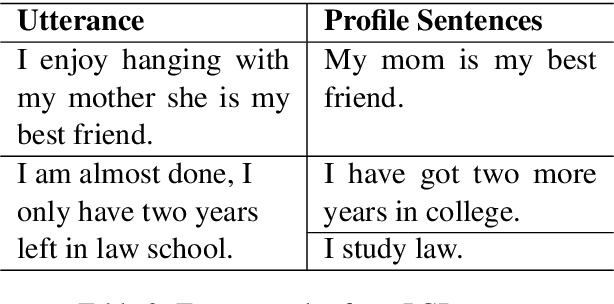
Recent approaches have attempted to personalize dialogue systems by leveraging profile information into models. However, this knowledge is scarce and difficult to obtain, which makes the extraction/generation of profile information from dialogues a fundamental asset. To surpass this limitation, we introduce the Profile Generation Task (PGTask). We contribute with a new dataset for this problem, comprising profile sentences aligned with related utterances, extracted from a corpus of dialogues. Furthermore, using state-of-the-art methods, we provide a benchmark for profile generation on this novel dataset. Our experiments disclose the challenges of profile generation, and we hope that this introduces a new research direction.