 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmentation to Improve Robustness and Interpretability of Deep Neural Networks
Feb 25, 2021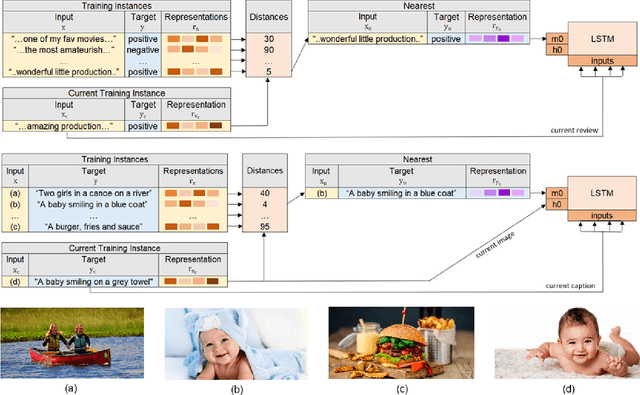
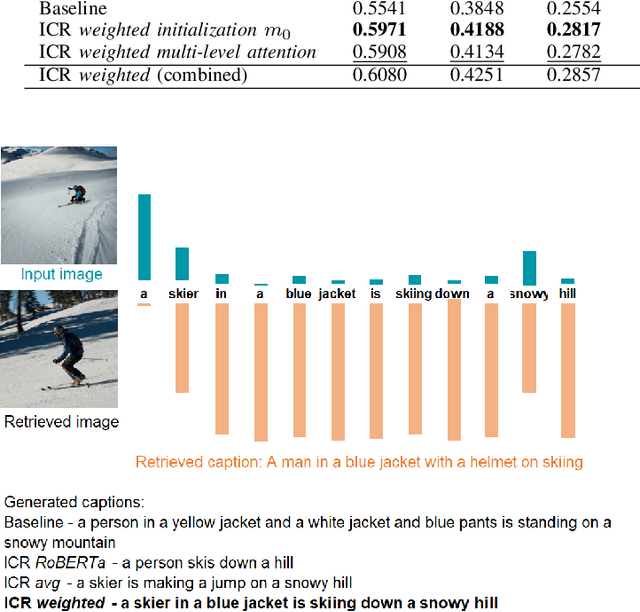


Deep neural network models have achieved state-of-the-art results in various tasks related to vision and/or language. Despite the use of large training data, most models are trained by iterating over single input-output pairs, discarding the remaining examples for the current prediction. In this work, we actively exploit the training data to improve the robustness and interpretability of deep neural networks, using the information from nearest training examples to aid the prediction both during training and testing. Specifically, the proposed approach uses the target of the nearest input example to initialize the memory state of an LSTM model or to guide attention mechanisms. We apply this approach to image captioning and sentiment analysis, conducting experiments with both image and text retrieval. Results show the effectiveness of the proposed models for the two tasks, on the widely used Flickr8 and IMDB datasets, respectively. Our code is publicly available http://github.com/RitaRamo/retrieval-augmentation-nn.