 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulated Reasoning is Reasoning
Jan 05, 2026Reasoning has long been understood as a pathway between stages of understanding. Proper reasoning leads to understanding of a given subject. This reasoning was conceptualized as a process of understanding in a particular way, i.e., "symbolic reasoning". Foundational Models (FM) demonstrate that this is not a necessary condition for many reasoning tasks: they can "reason" by way of imitating the process of "thinking out loud", testing the produced pathways, and iterating on these pathways on their own. This leads to some form of reasoning that can solve problems on its own or with few-shot learning, but appears fundamentally different from human reasoning due to its lack of grounding and common sense, leading to brittleness of the reasoning process. These insights promise to substantially alter our assessment of reasoning and its necessary conditions, but also inform the approaches to safety and robust defences against this brittleness of FMs. This paper offers and discusses several philosophical interpretations of this phenomenon, argues that the previously apt metaphor of the "stochastic parrot" has lost its relevance and thus should be abandoned, and reflects on different normative elements in the safety- and appropriateness-considerations emerging from these reasoning models and their growing capacity.
MEDAL: A Framework for Benchmarking LLMs as Multilingual Open-Domain Chatbots and Dialogue Evaluators
May 28, 2025As the capabilities of chatbots and their underlying LLMs continue to dramatically improve, evaluating their performance has increasingly become a major blocker to their further development. A major challenge is the available benchmarking datasets, which are largely static, outdated, and lacking in multilingual coverage, limiting their ability to capture subtle linguistic and cultural variations. This paper introduces MEDAL, an automated multi-agent framework for generating, evaluating, and curating more representative and diverse open-domain dialogue evaluation benchmarks. Our approach leverages several state-of-the-art LLMs to generate user-chatbot multilingual dialogues, conditioned on varied seed contexts. A strong LLM (GPT-4.1) is then used for a multidimensional analysis of the performance of the chatbots, uncovering noticeable cross-lingual performance differences. Guided by this large-scale evaluation, we curate a new meta-evaluation multilingual benchmark and human-annotate samples with nuanced quality judgments. This benchmark is then used to assess the ability of several reasoning and non-reasoning LLMs to act as evaluators of open-domain dialogues. We find that current LLMs struggle to detect nuanced issues, particularly those involving empathy and reasoning.
Soda-Eval: Open-Domain Dialogue Evaluation in the age of LLMs
Aug 20, 2024



Although human evaluation remains the gold standard for open-domain dialogue evaluation, the growing popularity of automated evaluation using Large Language Models (LLMs) has also extended to dialogue. However, most frameworks leverage benchmarks that assess older chatbots on aspects such as fluency and relevance, which are not reflective of the challenges associated with contemporary models. In fact, a qualitative analysis on Soda, a GPT-3.5 generated dialogue dataset, suggests that current chatbots may exhibit several recurring issues related to coherence and commonsense knowledge, but generally produce highly fluent and relevant responses. Noting the aforementioned limitations, this paper introduces Soda-Eval, an annotated dataset based on Soda that covers over 120K turn-level assessments across 10K dialogues, where the annotations were generated by GPT-4. Using Soda-Eval as a benchmark, we then study the performance of several open-access instruction-tuned LLMs, finding that dialogue evaluation remains challenging. Fine-tuning these models improves performance over few-shot inferences, both in terms of correlation and explanation.
ECoh: Turn-level Coherence Evaluation for Multilingual Dialogues
Jul 16, 2024Despite being heralded as the new standard for dialogue evaluation, the closed-source nature of GPT-4 poses challenges for the community. Motivated by the need for lightweight, open source, and multilingual dialogue evaluators, this paper introduces GenResCoh (Generated Responses targeting Coherence). GenResCoh is a novel LLM generated dataset comprising over 130k negative and positive responses and accompanying explanations seeded from XDailyDialog and XPersona covering English, French, German, Italian, and Chinese. Leveraging GenResCoh, we propose ECoh (Evaluation of Coherence), a family of evaluators trained to assess response coherence across multiple languages. Experimental results demonstrate that ECoh achieves multilingual detection capabilities superior to the teacher model (GPT-3.5-Turbo) on GenResCoh, despite being based on a much smaller architecture. Furthermore, the explanations provided by ECoh closely align in terms of quality with those generated by the teacher model.
On the Benchmarking of LLMs for Open-Domain Dialogue Evaluation
Jul 04, 2024
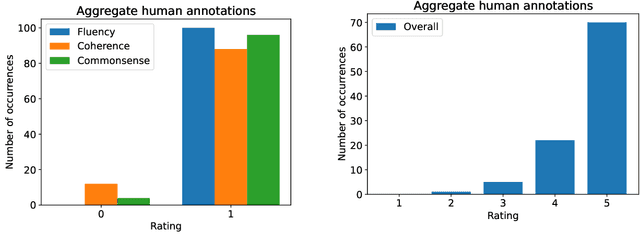
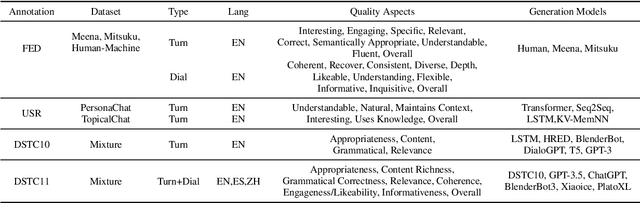
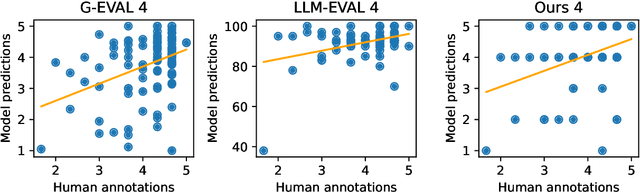
Large Language Models (LLMs) have showcased remarkable capabilities in various Natural Language Processing tasks. For automatic open-domain dialogue evaluation in particular, LLMs have been seamlessly integrated into evaluation frameworks, and together with human evaluation, compose the backbone of most evaluations. However, existing evaluation benchmarks often rely on outdated datasets and evaluate aspects like Fluency and Relevance, which fail to adequately capture the capabilities and limitations of state-of-the-art chatbot models. This paper critically examines current evaluation benchmarks, highlighting that the use of older response generators and quality aspects fail to accurately reflect modern chatbot capabilities. A small annotation experiment on a recent LLM-generated dataset (SODA) reveals that LLM evaluators such as GPT-4 struggle to detect actual deficiencies in dialogues generated by current LLM chatbots.
Dialogue Quality and Emotion Annotations for Customer Support Conversations
Nov 23, 2023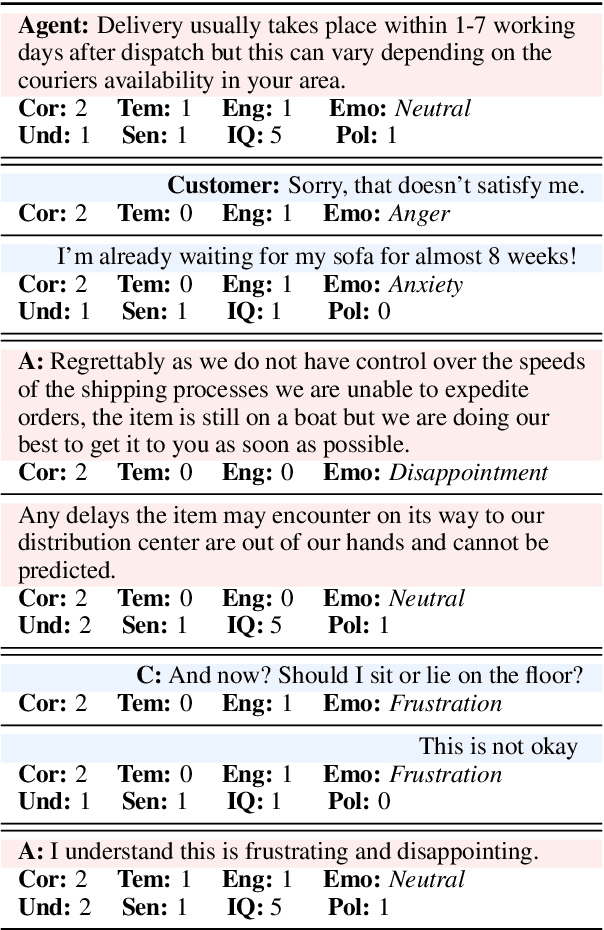
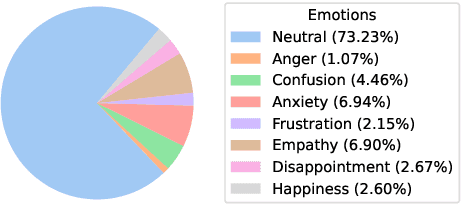

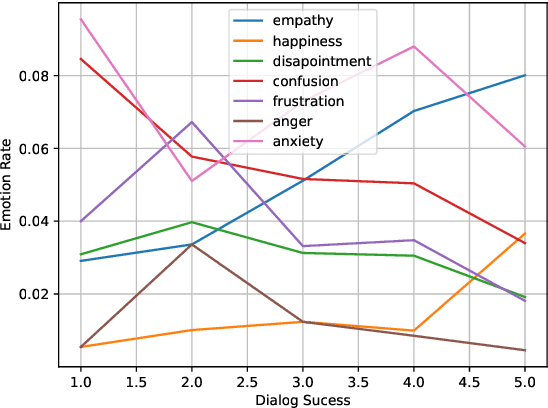
Task-oriented conversational datasets often lack topic variability and linguistic diversity. However, with the advent of Large Language Models (LLMs) pretrained on extensive, multilingual and diverse text data, these limitations seem overcome. Nevertheless, their generalisability to different languages and domains in dialogue applications remains uncertain without benchmarking datasets. This paper presents a holistic annotation approach for emotion and conversational quality in the context of bilingual customer support conversations. By performing annotations that take into consideration the complete instances that compose a conversation, one can form a broader perspective of the dialogue as a whole. Furthermore, it provides a unique and valuable resource for the development of text classification models. To this end, we present benchmarks for Emotion Recognition and Dialogue Quality Estimation and show that further research is needed to leverage these models in a production setting.
Simple LLM Prompting is State-of-the-Art for Robust and Multilingual Dialogue Evaluation
Sep 08, 2023
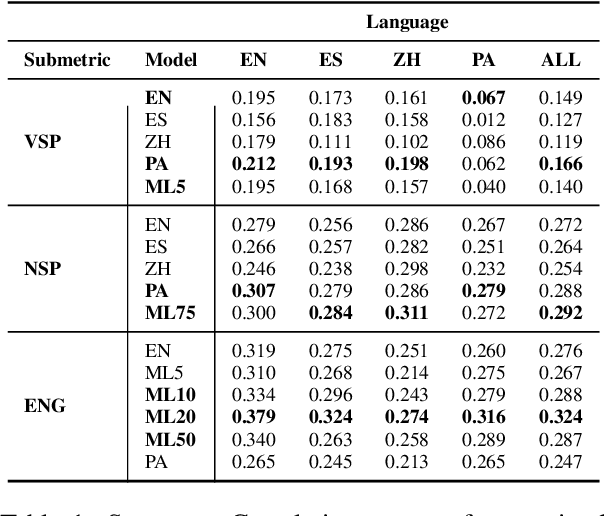


Despite significant research effort in the development of automatic dialogue evaluation metrics, little thought is given to evaluating dialogues other than in English. At the same time, ensuring metrics are invariant to semantically similar responses is also an overlooked topic. In order to achieve the desired properties of robustness and multilinguality for dialogue evaluation metrics, we propose a novel framework that takes advantage of the strengths of current evaluation models with the newly-established paradigm of prompting Large Language Models (LLMs). Empirical results show our framework achieves state of the art results in terms of mean Spearman correlation scores across several benchmarks and ranks first place on both the Robust and Multilingual tasks of the DSTC11 Track 4 "Automatic Evaluation Metrics for Open-Domain Dialogue Systems", proving the evaluation capabilities of prompted LLMs.
Towards Multilingual Automatic Dialogue Evaluation
Aug 31, 2023



The main limiting factor in the development of robust multilingual dialogue evaluation metrics is the lack of multilingual data and the limited availability of open sourced multilingual dialogue systems. In this work, we propose a workaround for this lack of data by leveraging a strong multilingual pretrained LLM and augmenting existing English dialogue data using Machine Translation. We empirically show that the naive approach of finetuning a pretrained multilingual encoder model with translated data is insufficient to outperform the strong baseline of finetuning a multilingual model with only source data. Instead, the best approach consists in the careful curation of translated data using MT Quality Estimation metrics, excluding low quality translations that hinder its performance.
The Inside Story: Towards Better Understanding of Machine Translation Neural Evaluation Metrics
May 19, 2023Neural metrics for machine translation evaluation, such as COMET, exhibit significant improvements in their correlation with human judgments, as compared to traditional metrics based on lexical overlap, such as BLEU. Yet, neural metrics are, to a great extent, "black boxes" returning a single sentence-level score without transparency about the decision-making process. In this work, we develop and compare several neural explainability methods and demonstrate their effectiveness for interpreting state-of-the-art fine-tuned neural metrics. Our study reveals that these metrics leverage token-level information that can be directly attributed to translation errors, as assessed through comparison of token-level neural saliency maps with Multidimensional Quality Metrics (MQM) annotations and with synthetically-generated critical translation errors. To ease future research, we release our code at: https://github.com/Unbabel/COMET/tree/explainable-metrics.
Appropriateness is all you need!
Apr 27, 2023The strive to make AI applications "safe" has led to the development of safety-measures as the main or even sole normative requirement of their permissible use. Similar can be attested to the latest version of chatbots, such as chatGPT. In this view, if they are "safe", they are supposed to be permissible to deploy. This approach, which we call "safety-normativity", is rather limited in solving the emerging issues that chatGPT and other chatbots have caused thus far. In answering this limitation, in this paper we argue for limiting chatbots in the range of topics they can chat about according to the normative concept of appropriateness. We argue that rather than looking for "safety" in a chatbot's utterances to determine what they may and may not say, we ought to assess those utterances according to three forms of appropriateness: technical-discursive, social, and moral. We then spell out what requirements for chatbots follow from these forms of appropriateness to avoid the limits of previous accounts: positionality, acceptability, and value alignment (PAVA). With these in mind, we may be able to determine what a chatbot may and may not say. Lastly, one initial suggestion is to use challenge sets, specifically designed for appropriateness, as a validation method.