 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLEU Meets COMET: Combining Lexical and Neural Metrics Towards Robust Machine Translation Evaluation
May 30, 2023Although neural-based machine translation evaluation metrics, such as COMET or BLEURT, have achieved strong correlations with human judgements, they are sometimes unreliable in detecting certain phenomena that can be considered as critical errors, such as deviations in entities and numbers. In contrast, traditional evaluation metrics, such as BLEU or chrF, which measure lexical or character overlap between translation hypotheses and human references, have lower correlations with human judgements but are sensitive to such deviations. In this paper, we investigate several ways of combining the two approaches in order to increase robustness of state-of-the-art evaluation methods to translations with critical errors. We show that by using additional information during training, such as sentence-level features and word-level tags, the trained metrics improve their capability to penalize translations with specific troublesome phenomena, which leads to gains in correlation with human judgments and on recent challenge sets on several language pairs.
CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task
Sep 13, 2022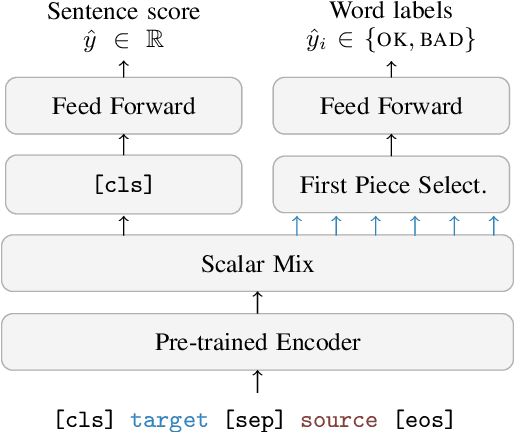
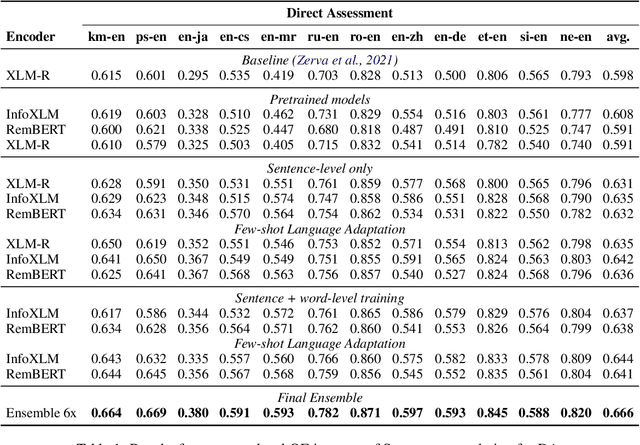
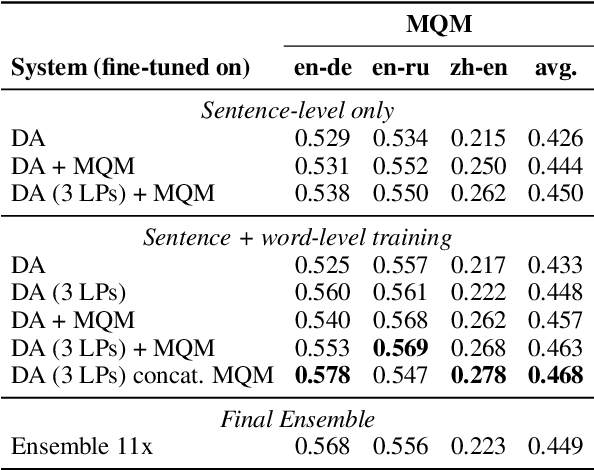
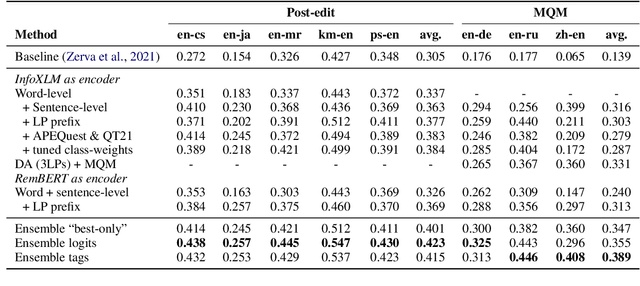
We present the joint contribution of IST and Unbabel to the WMT 2022 Shared Task on Quality Estimation (QE). Our team participated on all three subtasks: (i) Sentence and Word-level Quality Prediction; (ii) Explainable QE; and (iii) Critical Error Detection. For all tasks we build on top of the COMET framework, connecting it with the predictor-estimator architecture of OpenKiwi, and equipping it with a word-level sequence tagger and an explanation extractor. Our results suggest that incorporating references during pretraining improves performance across several language pairs on downstream tasks, and that jointly training with sentence and word-level objectives yields a further boost. Furthermore, combining attention and gradient information proved to be the top strategy for extracting good explanations of sentence-level QE models. Overall, our submissions achieved the best results for all three tasks for almost all language pairs by a considerable margin.
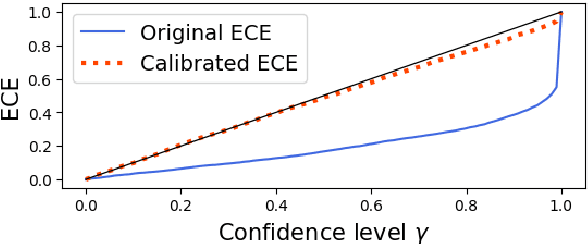
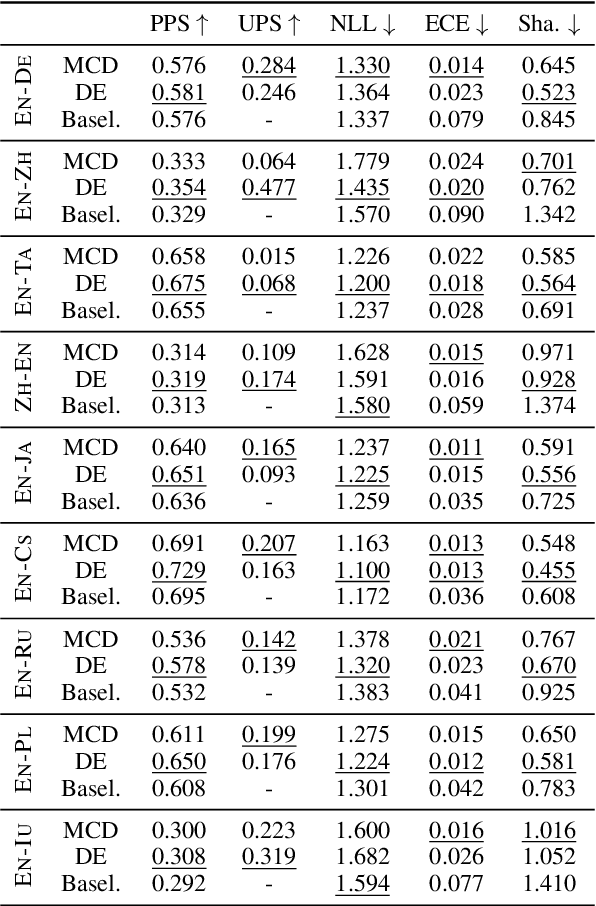
Better Uncertainty Quantification for Machine Translation Evaluation
Apr 13, 2022

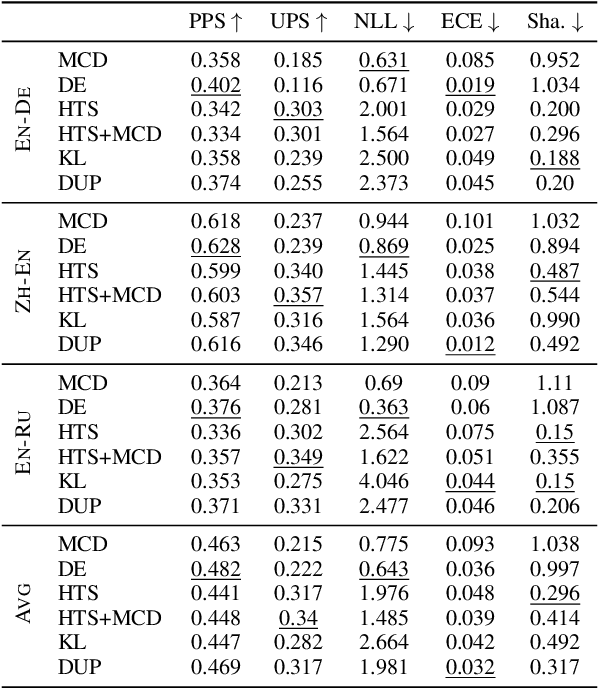
Neural-based machine translation (MT) evaluation metrics are progressing fast. However, these systems are often hard to interpret and might produce unreliable scores when human references or assessments are noisy or when data is out-of-domain. Recent work leveraged uncertainty quantification techniques such as Monte Carlo dropout and deep ensembles to provide confidence intervals, but these techniques (as we show) are limited in several ways. In this paper we investigate more powerful and efficient uncertainty predictors for MT evaluation metrics and their potential to capture aleatoric and epistemic uncertainty. To this end we train the COMET metric with new heteroscedastic regression, divergence minimization, and direct uncertainty prediction objectives. Our experiments show improved results on WMT20 and WMT21 metrics task datasets and a substantial reduction in computational costs. Moreover, they demonstrate the ability of our predictors to identify low quality references and to reveal model uncertainty due to out-of-domain data.
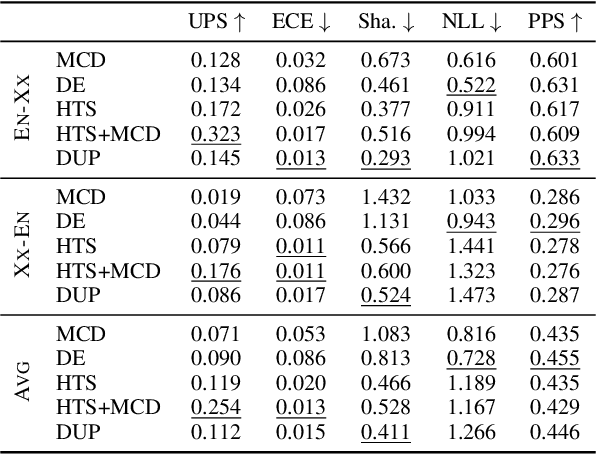
Uncertainty-Aware Machine Translation Evaluation
Sep 13, 2021
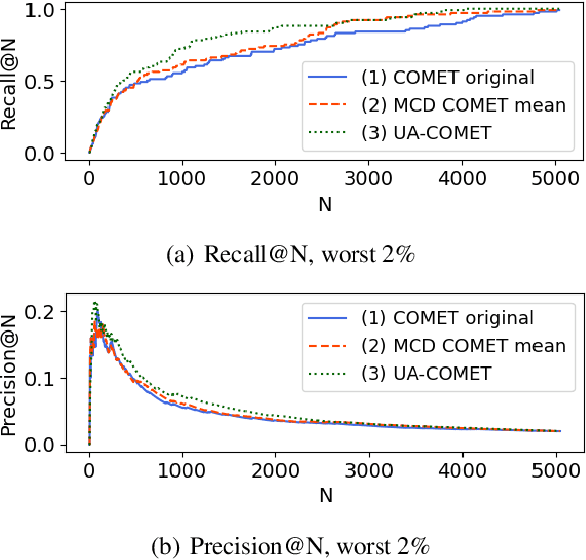
Several neural-based metrics have been recently proposed to evaluate machine translation quality. However, all of them resort to point estimates, which provide limited information at segment level. This is made worse as they are trained on noisy, biased and scarce human judgements, often resulting in unreliable quality predictions. In this paper, we introduce uncertainty-aware MT evaluation and analyze the trustworthiness of the predicted quality. We combine the COMET framework with two uncertainty estimation methods, Monte Carlo dropout and deep ensembles, to obtain quality scores along with confidence intervals. We compare the performance of our uncertainty-aware MT evaluation methods across multiple language pairs from the QT21 dataset and the WMT20 metrics task, augmented with MQM annotations. We experiment with varying numbers of references and further discuss the usefulness of uncertainty-aware quality estimation (without references) to flag possibly critical translation mistakes.
Char-RNN and Active Learning for Hashtag Segmentation
Nov 08, 2019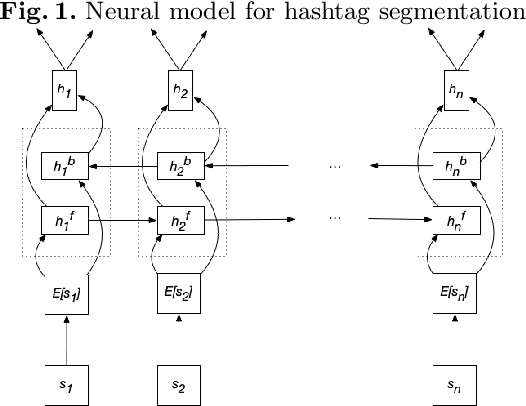
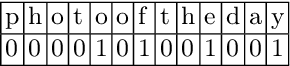
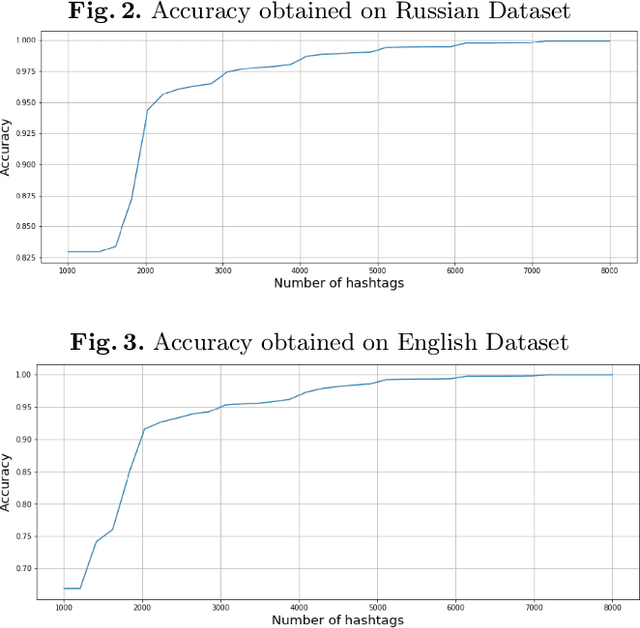
We explore the abilities of character recurrent neural network (char-RNN) for hashtag segmentation. Our approach to the task is the following: we generate synthetic training dataset according to frequent n-grams that satisfy predefined morpho-syntactic patterns to avoid any manual annotation. The active learning strategy limits the training dataset and selects informative training subset. The approach does not require any language-specific settings and is compared for two languages, which differ in inflection degree.