 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Uncertainty Quantification for Machine Translation Evaluation
Paper and Code

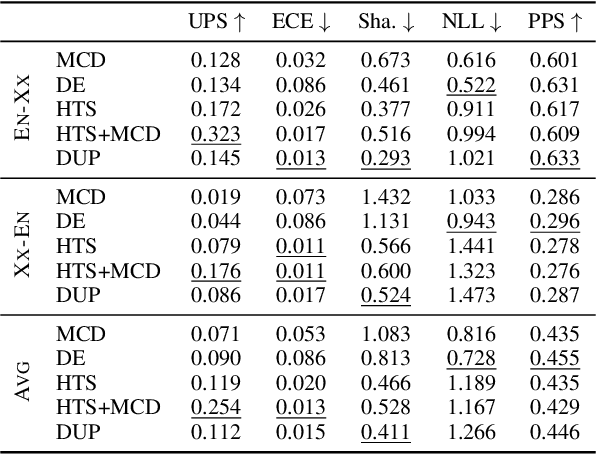

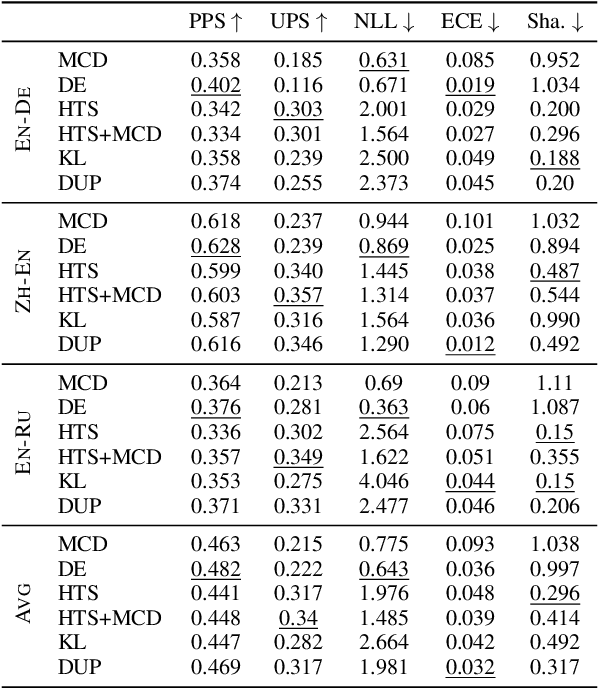
Neural-based machine translation (MT) evaluation metrics are progressing fast. However, these systems are often hard to interpret and might produce unreliable scores when human references or assessments are noisy or when data is out-of-domain. Recent work leveraged uncertainty quantification techniques such as Monte Carlo dropout and deep ensembles to provide confidence intervals, but these techniques (as we show) are limited in several ways. In this paper we investigate more powerful and efficient uncertainty predictors for MT evaluation metrics and their potential to capture aleatoric and epistemic uncertainty. To this end we train the COMET metric with new heteroscedastic regression, divergence minimization, and direct uncertainty prediction objectives. Our experiments show improved results on WMT20 and WMT21 metrics task datasets and a substantial reduction in computational costs. Moreover, they demonstrate the ability of our predictors to identify low quality references and to reveal model uncertainty due to out-of-domain data.