 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMÕES: A Comprehensive Automatic Speech Recognition Benchmark for European Portuguese
Aug 27, 2025Existing resources for Automatic Speech Recognition in Portuguese are mostly focused on Brazilian Portuguese, leaving European Portuguese (EP) and other varieties under-explored. To bridge this gap, we introduce CAM\~OES, the first open framework for EP and other Portuguese varieties. It consists of (1) a comprehensive evaluation benchmark, including 46h of EP test data spanning multiple domains; and (2) a collection of state-of-the-art models. For the latter, we consider multiple foundation models, evaluating their zero-shot and fine-tuned performances, as well as E-Branchformer models trained from scratch. A curated set of 425h of EP was used for both fine-tuning and training. Our results show comparable performance for EP between fine-tuned foundation models and the E-Branchformer. Furthermore, the best-performing models achieve relative improvements above 35% WER, compared to the strongest zero-shot foundation model, establishing a new state-of-the-art for EP and other varieties.
MEDAL: A Framework for Benchmarking LLMs as Multilingual Open-Domain Chatbots and Dialogue Evaluators
May 28, 2025As the capabilities of chatbots and their underlying LLMs continue to dramatically improve, evaluating their performance has increasingly become a major blocker to their further development. A major challenge is the available benchmarking datasets, which are largely static, outdated, and lacking in multilingual coverage, limiting their ability to capture subtle linguistic and cultural variations. This paper introduces MEDAL, an automated multi-agent framework for generating, evaluating, and curating more representative and diverse open-domain dialogue evaluation benchmarks. Our approach leverages several state-of-the-art LLMs to generate user-chatbot multilingual dialogues, conditioned on varied seed contexts. A strong LLM (GPT-4.1) is then used for a multidimensional analysis of the performance of the chatbots, uncovering noticeable cross-lingual performance differences. Guided by this large-scale evaluation, we curate a new meta-evaluation multilingual benchmark and human-annotate samples with nuanced quality judgments. This benchmark is then used to assess the ability of several reasoning and non-reasoning LLMs to act as evaluators of open-domain dialogues. We find that current LLMs struggle to detect nuanced issues, particularly those involving empathy and reasoning.
Tackling Cognitive Impairment Detection from Speech: A submission to the PROCESS Challenge
Dec 30, 2024



This work describes our group's submission to the PROCESS Challenge 2024, with the goal of assessing cognitive decline through spontaneous speech, using three guided clinical tasks. This joint effort followed a holistic approach, encompassing both knowledge-based acoustic and text-based feature sets, as well as LLM-based macrolinguistic descriptors, pause-based acoustic biomarkers, and multiple neural representations (e.g., LongFormer, ECAPA-TDNN, and Trillson embeddings). Combining these feature sets with different classifiers resulted in a large pool of models, from which we selected those that provided the best balance between train, development, and individual class performance. Our results show that our best performing systems correspond to combinations of models that are complementary to each other, relying on acoustic and textual information from all three clinical tasks.
Soda-Eval: Open-Domain Dialogue Evaluation in the age of LLMs
Aug 20, 2024



Although human evaluation remains the gold standard for open-domain dialogue evaluation, the growing popularity of automated evaluation using Large Language Models (LLMs) has also extended to dialogue. However, most frameworks leverage benchmarks that assess older chatbots on aspects such as fluency and relevance, which are not reflective of the challenges associated with contemporary models. In fact, a qualitative analysis on Soda, a GPT-3.5 generated dialogue dataset, suggests that current chatbots may exhibit several recurring issues related to coherence and commonsense knowledge, but generally produce highly fluent and relevant responses. Noting the aforementioned limitations, this paper introduces Soda-Eval, an annotated dataset based on Soda that covers over 120K turn-level assessments across 10K dialogues, where the annotations were generated by GPT-4. Using Soda-Eval as a benchmark, we then study the performance of several open-access instruction-tuned LLMs, finding that dialogue evaluation remains challenging. Fine-tuning these models improves performance over few-shot inferences, both in terms of correlation and explanation.
ECoh: Turn-level Coherence Evaluation for Multilingual Dialogues
Jul 16, 2024Despite being heralded as the new standard for dialogue evaluation, the closed-source nature of GPT-4 poses challenges for the community. Motivated by the need for lightweight, open source, and multilingual dialogue evaluators, this paper introduces GenResCoh (Generated Responses targeting Coherence). GenResCoh is a novel LLM generated dataset comprising over 130k negative and positive responses and accompanying explanations seeded from XDailyDialog and XPersona covering English, French, German, Italian, and Chinese. Leveraging GenResCoh, we propose ECoh (Evaluation of Coherence), a family of evaluators trained to assess response coherence across multiple languages. Experimental results demonstrate that ECoh achieves multilingual detection capabilities superior to the teacher model (GPT-3.5-Turbo) on GenResCoh, despite being based on a much smaller architecture. Furthermore, the explanations provided by ECoh closely align in terms of quality with those generated by the teacher model.
On the Benchmarking of LLMs for Open-Domain Dialogue Evaluation
Jul 04, 2024
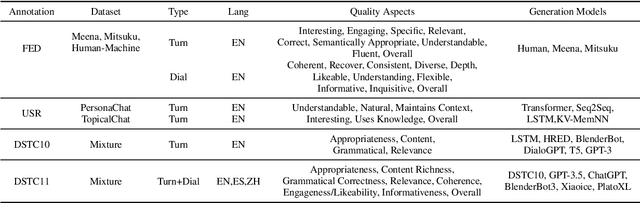
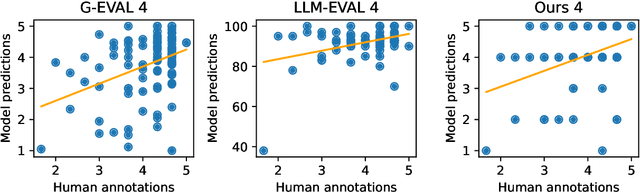
Large Language Models (LLMs) have showcased remarkable capabilities in various Natural Language Processing tasks. For automatic open-domain dialogue evaluation in particular, LLMs have been seamlessly integrated into evaluation frameworks, and together with human evaluation, compose the backbone of most evaluations. However, existing evaluation benchmarks often rely on outdated datasets and evaluate aspects like Fluency and Relevance, which fail to adequately capture the capabilities and limitations of state-of-the-art chatbot models. This paper critically examines current evaluation benchmarks, highlighting that the use of older response generators and quality aspects fail to accurately reflect modern chatbot capabilities. A small annotation experiment on a recent LLM-generated dataset (SODA) reveals that LLM evaluators such as GPT-4 struggle to detect actual deficiencies in dialogues generated by current LLM chatbots.
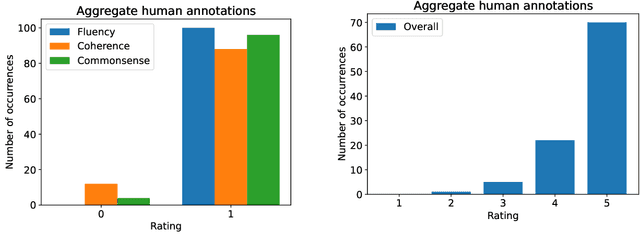
Dialogue Quality and Emotion Annotations for Customer Support Conversations
Nov 23, 2023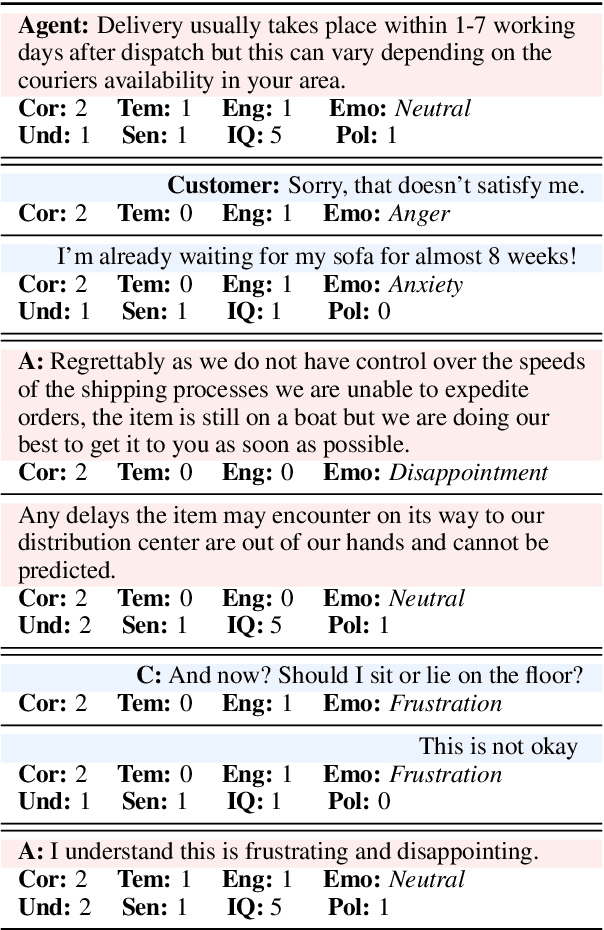
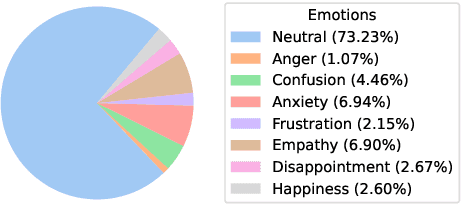

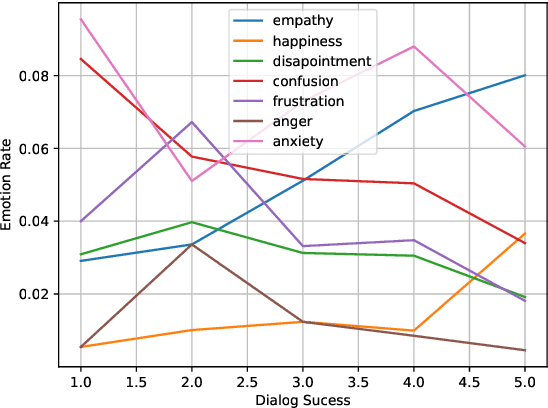
Task-oriented conversational datasets often lack topic variability and linguistic diversity. However, with the advent of Large Language Models (LLMs) pretrained on extensive, multilingual and diverse text data, these limitations seem overcome. Nevertheless, their generalisability to different languages and domains in dialogue applications remains uncertain without benchmarking datasets. This paper presents a holistic annotation approach for emotion and conversational quality in the context of bilingual customer support conversations. By performing annotations that take into consideration the complete instances that compose a conversation, one can form a broader perspective of the dialogue as a whole. Furthermore, it provides a unique and valuable resource for the development of text classification models. To this end, we present benchmarks for Emotion Recognition and Dialogue Quality Estimation and show that further research is needed to leverage these models in a production setting.
Simple LLM Prompting is State-of-the-Art for Robust and Multilingual Dialogue Evaluation
Sep 08, 2023
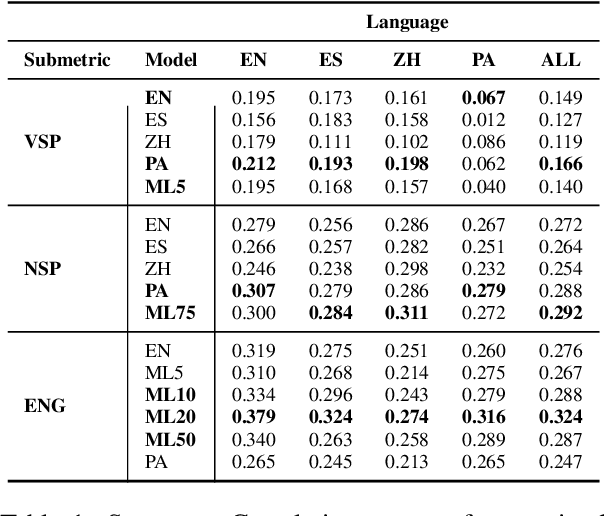


Despite significant research effort in the development of automatic dialogue evaluation metrics, little thought is given to evaluating dialogues other than in English. At the same time, ensuring metrics are invariant to semantically similar responses is also an overlooked topic. In order to achieve the desired properties of robustness and multilinguality for dialogue evaluation metrics, we propose a novel framework that takes advantage of the strengths of current evaluation models with the newly-established paradigm of prompting Large Language Models (LLMs). Empirical results show our framework achieves state of the art results in terms of mean Spearman correlation scores across several benchmarks and ranks first place on both the Robust and Multilingual tasks of the DSTC11 Track 4 "Automatic Evaluation Metrics for Open-Domain Dialogue Systems", proving the evaluation capabilities of prompted LLMs.
Towards Multilingual Automatic Dialogue Evaluation
Aug 31, 2023



The main limiting factor in the development of robust multilingual dialogue evaluation metrics is the lack of multilingual data and the limited availability of open sourced multilingual dialogue systems. In this work, we propose a workaround for this lack of data by leveraging a strong multilingual pretrained LLM and augmenting existing English dialogue data using Machine Translation. We empirically show that the naive approach of finetuning a pretrained multilingual encoder model with translated data is insufficient to outperform the strong baseline of finetuning a multilingual model with only source data. Instead, the best approach consists in the careful curation of translated data using MT Quality Estimation metrics, excluding low quality translations that hinder its performance.
Using Self-Supervised Feature Extractors with Attention for Automatic COVID-19 Detection from Speech
Jun 30, 2021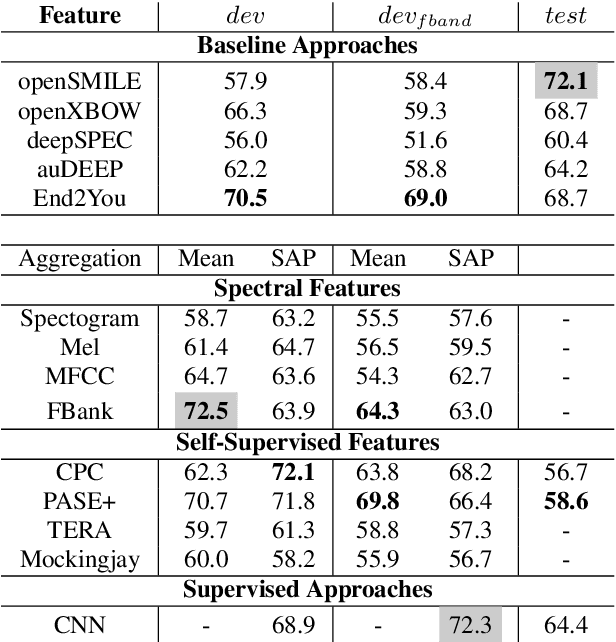
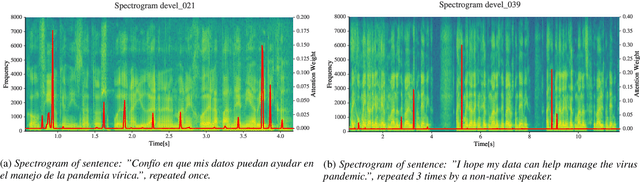
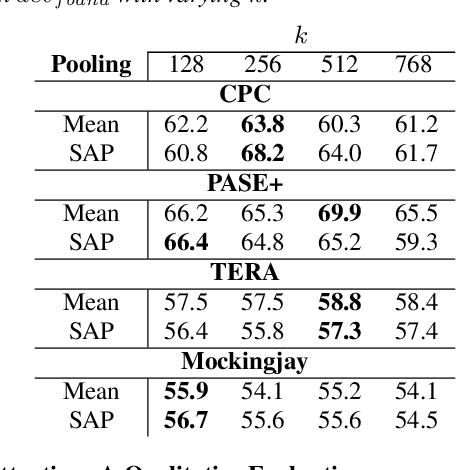
The ComParE 2021 COVID-19 Speech Sub-challenge provides a test-bed for the evaluation of automatic detectors of COVID-19 from speech. Such models can be of value by providing test triaging capabilities to health authorities, working alongside traditional testing methods. Herein, we leverage the usage of pre-trained, problem agnostic, speech representations and evaluate their use for this task. We compare the obtained results against a CNN architecture trained from scratch and traditional frequency-domain representations. We also evaluate the usage of Self-Attention Pooling as an utterance-level information aggregation method. Experimental results demonstrate that models trained on features extracted from self-supervised models perform similarly or outperform fully-supervised models and models based on handcrafted features. Our best model improves the Unweighted Average Recall (UAR) from 69.0\% to 72.3\% on a development set comprised of only full-band examples and achieves 64.4\% on the test set. Furthermore, we study where the network is attending, attempting to draw some conclusions regarding its explainability. In this relatively small dataset, we find the network attends especially to vowels and aspirates.