 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Challenges for Content Privacy in Speech and Audio
Jan 21, 2023Privacy in speech and audio has many facets. A particularly under-developed area of privacy in this domain involves consideration for information related to content and context. Speech content can include words and their meaning or even stylistic markers, pathological speech, intonation patterns, or emotion. More generally, audio captured in-the-wild may contain background speech or reveal contextual information such as markers of location, room characteristics, paralinguistic sounds, or other audible events. Audio recording devices and speech technologies are becoming increasingly commonplace in everyday life. At the same time, commercialised speech and audio technologies do not provide consumers with a range of privacy choices. Even where privacy is regulated or protected by law, technical solutions to privacy assurance and enforcement fall short. This position paper introduces three important and timely research challenges for content privacy in speech and audio. We highlight current gaps and opportunities, and identify focus areas, that could have significant implications for developing ethical and safer speech technologies.
Analysis of Voice Conversion and Code-Switching Synthesis Using VQ-VAE
Mar 28, 2022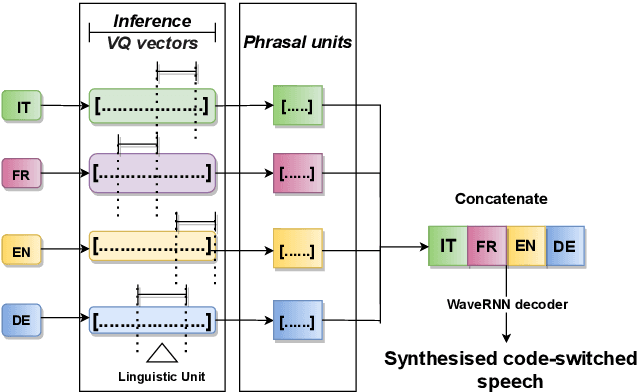
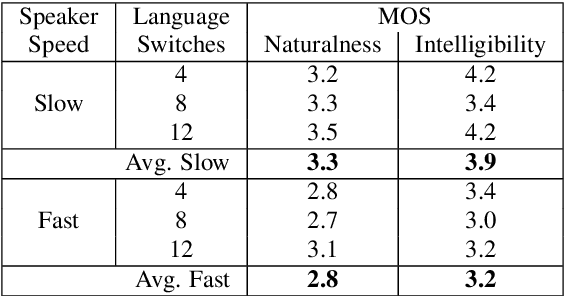
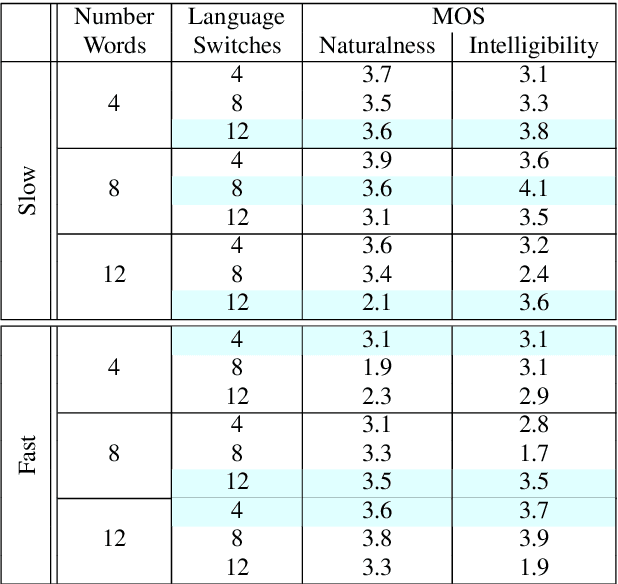
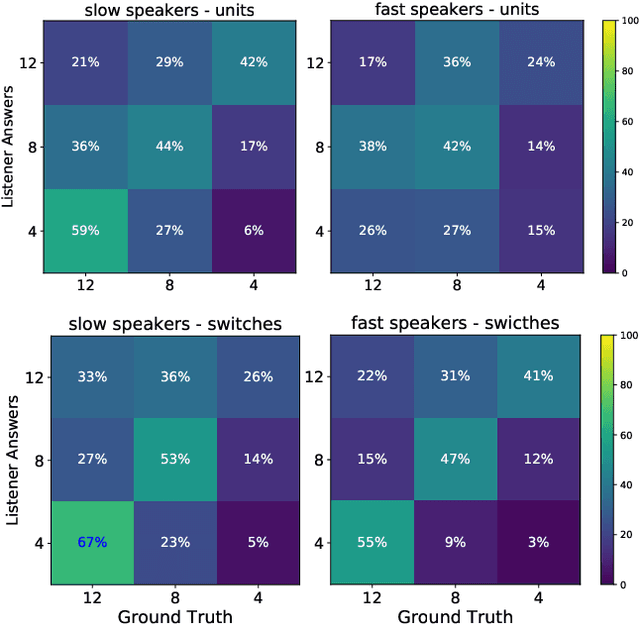
This paper presents an analysis of speech synthesis quality achieved by simultaneously performing voice conversion and language code-switching using multilingual VQ-VAE speech synthesis in German, French, English and Italian. In this paper, we utilize VQ code indices representing phone information from VQ-VAE to perform code-switching and a VQ speaker code to perform voice conversion in a single system with a neural vocoder. Our analysis examines several aspects of code-switching including the number of language switches and the number of words involved in each switch. We found that speech synthesis quality degrades after increasing the number of language switches within an utterance and decreasing the number of words. We also found some evidence of accent transfer when performing voice conversion across languages as observed when a speaker's original language differs from the language of a synthetic target utterance. We present results from our listening tests and discuss the inherent difficulties of assessing accent transfer in speech synthesis. Our work highlights some of the limitations and strengths of using a semi-supervised end-to-end system like VQ-VAE for handling multilingual synthesis. Our work provides insight into why multilingual speech synthesis is challenging and we suggest some directions for expanding work in this area.