 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker-Adapted End-to-End Visual Speech Recognition for Continuous Spanish
Paper and Code
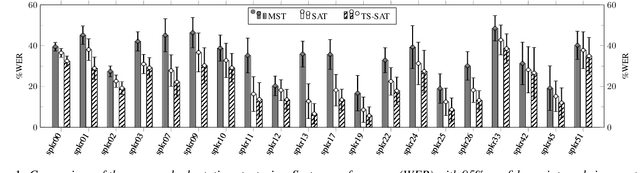
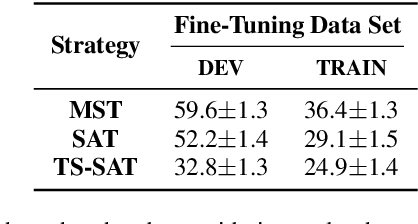
Different studies have shown the importance of visual cues throughout the speech perception process. In fact, the development of audiovisual approaches has led to advances in the field of speech technologies. However, although noticeable results have recently been achieved, visual speech recognition remains an open research problem. It is a task in which, by dispensing with the auditory sense, challenges such as visual ambiguities and the complexity of modeling silence must be faced. Nonetheless, some of these challenges can be alleviated when the problem is approached from a speaker-dependent perspective. Thus, this paper studies, using the Spanish LIP-RTVE database, how the estimation of specialized end-to-end systems for a specific person could affect the quality of speech recognition. First, different adaptation strategies based on the fine-tuning technique were proposed. Then, a pre-trained CTC/Attention architecture was used as a baseline throughout our experiments. Our findings showed that a two-step fine-tuning process, where the VSR system is first adapted to the task domain, provided significant improvements when the speaker adaptation was addressed. Furthermore, results comparable to the current state of the art were reached even when only a limited amount of data was available.