 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Conventional Hybrid and CTC/Attention Decoders for Continuous Visual Speech Recognition
Paper and Code
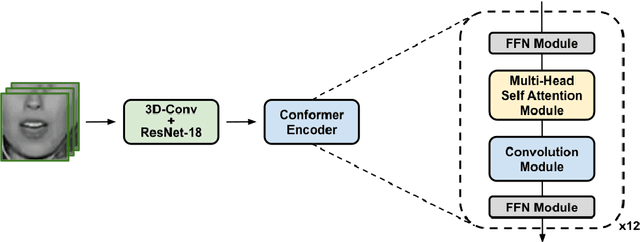
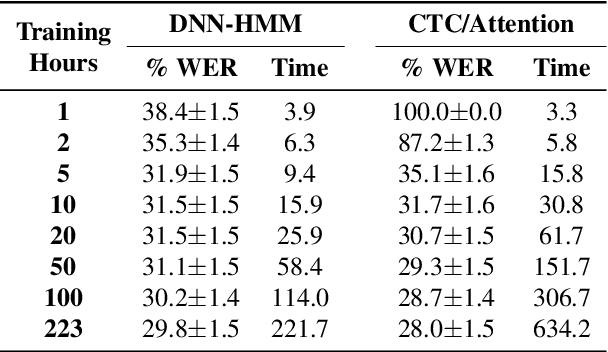
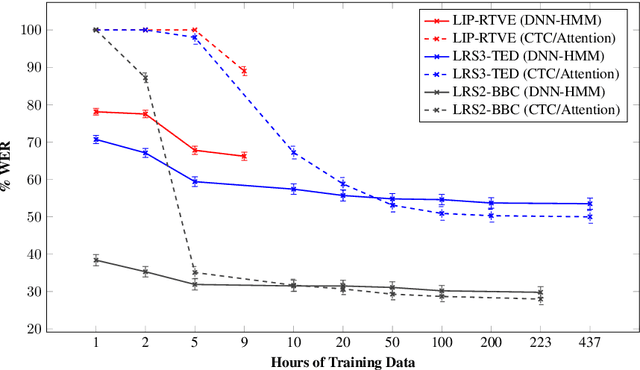
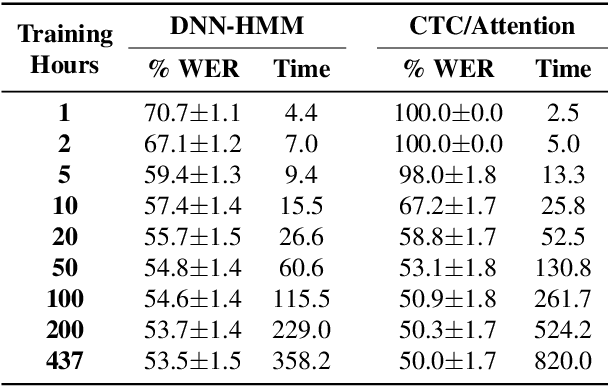
Thanks to the rise of deep learning and the availability of large-scale audio-visual databases, recent advances have been achieved in Visual Speech Recognition (VSR). Similar to other speech processing tasks, these end-to-end VSR systems are usually based on encoder-decoder architectures. While encoders are somewhat general, multiple decoding approaches have been explored, such as the conventional hybrid model based on Deep Neural Networks combined with Hidden Markov Models (DNN-HMM) or the Connectionist Temporal Classification (CTC) paradigm. However, there are languages and tasks in which data is scarce, and in this situation, there is not a clear comparison between different types of decoders. Therefore, we focused our study on how the conventional DNN-HMM decoder and its state-of-the-art CTC/Attention counterpart behave depending on the amount of data used for their estimation. We also analyzed to what extent our visual speech features were able to adapt to scenarios for which they were not explicitly trained, either considering a similar dataset or another collected for a different language. Results showed that the conventional paradigm reached recognition rates that improve the CTC/Attention model in data-scarcity scenarios along with a reduced training time and fewer parameters.