 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Sparsify Travelling Salesman Problem Instances
Apr 19, 2021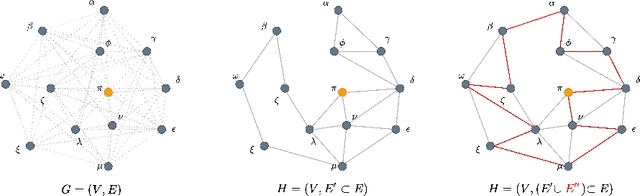


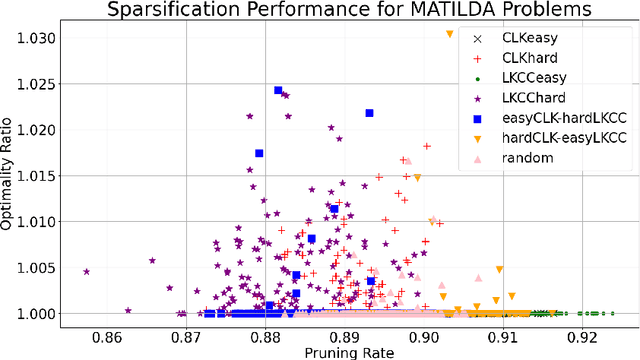
In order to deal with the high development time of exact and approximation algorithms for NP-hard combinatorial optimisation problems and the high running time of exact solvers, deep learning techniques have been used in recent years as an end-to-end approach to find solutions. However, there are issues of representation, generalisation, complex architectures, interpretability of models for mathematical analysis etc. using deep learning techniques. As a compromise, machine learning can be used to improve the run time performance of exact algorithms in a matheuristics framework. In this paper, we use a pruning heuristic leveraging machine learning as a pre-processing step followed by an exact Integer Programming approach. We apply this approach to sparsify instances of the classical travelling salesman problem. Our approach learns which edges in the underlying graph are unlikely to belong to an optimal solution and removes them, thus sparsifying the graph and significantly reducing the number of decision variables. We use carefully selected features derived from linear programming relaxation, cutting planes exploration, minimum-weight spanning tree heuristics and various other local and statistical analysis of the graph. Our learning approach requires very little training data and is amenable to mathematical analysis. We demonstrate that our approach can reliably prune a large fraction of the variables in TSP instances from TSPLIB/MATILDA (>85%$) while preserving most of the optimal tour edges. Our approach can successfully prune problem instances even if they lie outside the training distribution, resulting in small optimality gaps between the pruned and original problems in most cases. Using our learning technique, we discover novel heuristics for sparsifying TSP instances, that may be of independent interest for variants of the vehicle routing problem.
Integer-Programming Ensemble of Temporal-Relations Classifiers
Jul 30, 2018
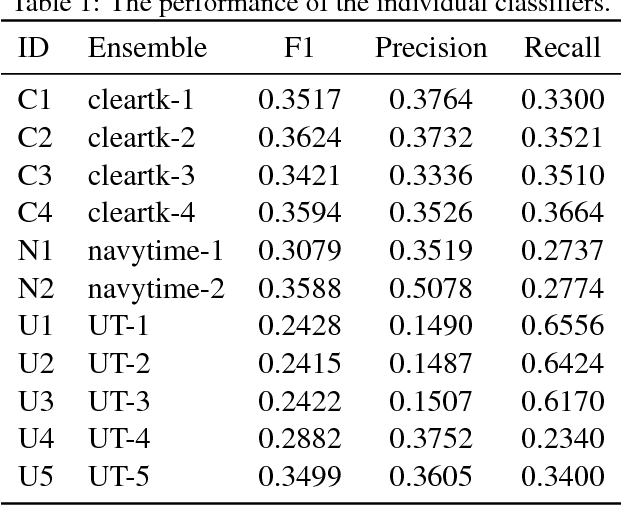
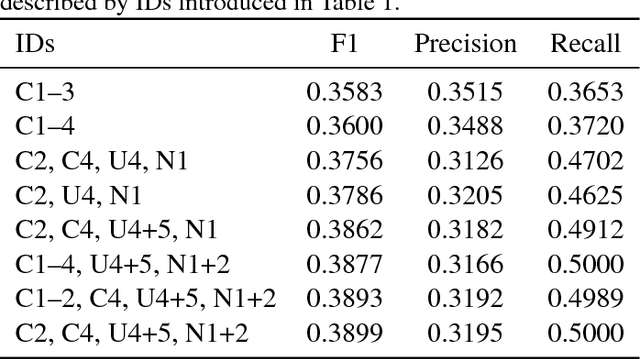
The extraction and understanding of temporal events and their relations are major challenges in natural language processing. Processing text on a sentence-by-sentence or expression-by-expression basis often fails, in part due to the challenge of capturing the global consistency of the text. We present an ensemble method, which reconciles the outputs of multiple classifiers of temporal expressions across the text using integer programming. Computational experiments show that the ensemble improves upon the best individual results from two recent challenges, SemEval-2013 TempEval-3 (Temporal Annotation) and SemEval-2016 Task 12 (Clinical TempEval).