 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATP: Directed Graph Embedding with Asymmetric Transitivity Preservation
Nov 06, 2018
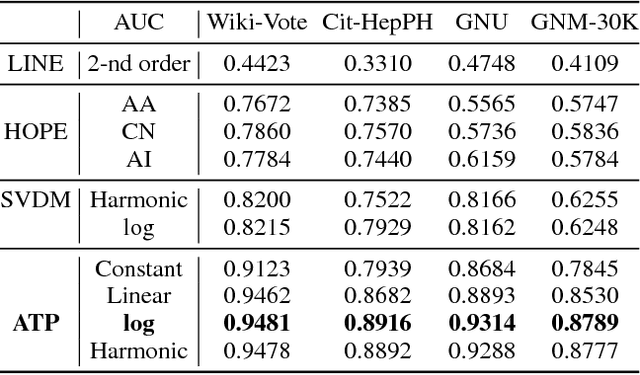

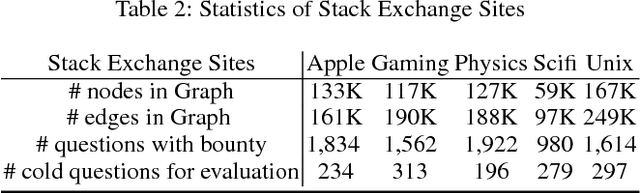
Directed graphs have been widely used in Community Question Answering services (CQAs) to model asymmetric relationships among different types of nodes in CQA graphs, e.g., question, answer, user. Asymmetric transitivity is an essential property of directed graphs, since it can play an important role in downstream graph inference and analysis. Question difficulty and user expertise follow the characteristic of asymmetric transitivity. Maintaining such properties, while reducing the graph to a lower dimensional vector embedding space, has been the focus of much recent research. In this paper, we tackle the challenge of directed graph embedding with asymmetric transitivity preservation and then leverage the proposed embedding method to solve a fundamental task in CQAs: how to appropriately route and assign newly posted questions to users with the suitable expertise and interest in CQAs. The technique incorporates graph hierarchy and reachability information naturally by relying on a non-linear transformation that operates on the core reachability and implicit hierarchy within such graphs. Subsequently, the methodology levers a factorization-based approach to generate two embedding vectors for each node within the graph, to capture the asymmetric transitivity. Extensive experiments show that our framework consistently and significantly outperforms the state-of-the-art baselines on two diverse real-world tasks: link prediction, and question difficulty estimation and expert finding in online forums like Stack Exchange. Particularly, our framework can support inductive embedding learning for newly posted questions (unseen nodes during training), and therefore can properly route and assign these kinds of questions to experts in CQAs.
Semi-supervised Embedding in Attributed Networks with Outliers
Apr 26, 2018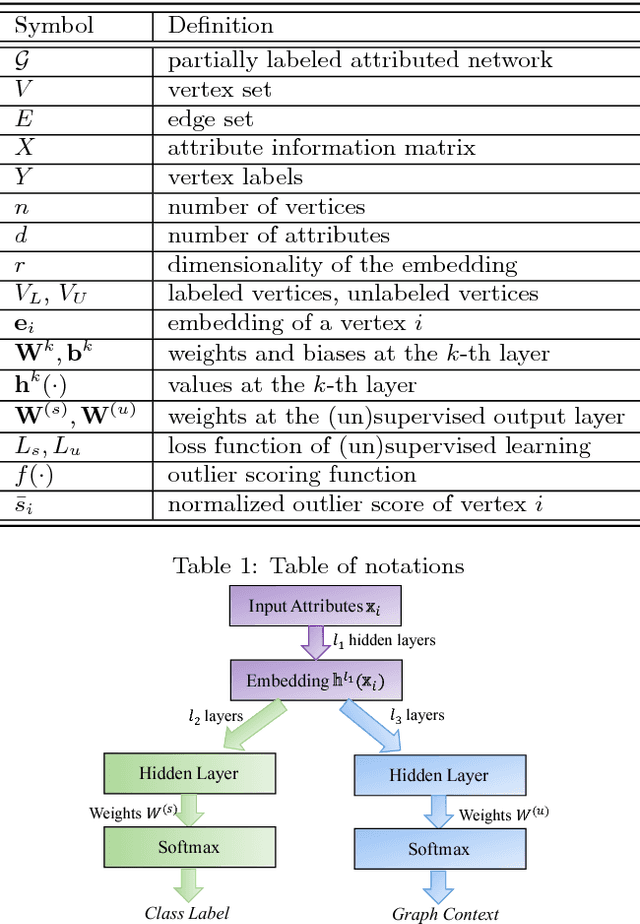



In this paper, we propose a novel framework, called Semi-supervised Embedding in Attributed Networks with Outliers (SEANO), to learn a low-dimensional vector representation that systematically captures the topological proximity, attribute affinity and label similarity of vertices in a partially labeled attributed network (PLAN). Our method is designed to work in both transductive and inductive settings while explicitly alleviating noise effects from outliers. Experimental results on various datasets drawn from the web, text and image domains demonstrate the advantages of SEANO over state-of-the-art methods in semi-supervised classification under transductive as well as inductive settings. We also show that a subset of parameters in SEANO is interpretable as outlier score and can significantly outperform baseline methods when applied for detecting network outliers. Finally, we present the use of SEANO in a challenging real-world setting -- flood mapping of satellite images and show that it is able to outperform modern remote sensing algorithms for this task.
MILE: A Multi-Level Framework for Scalable Graph Embedding
Feb 26, 2018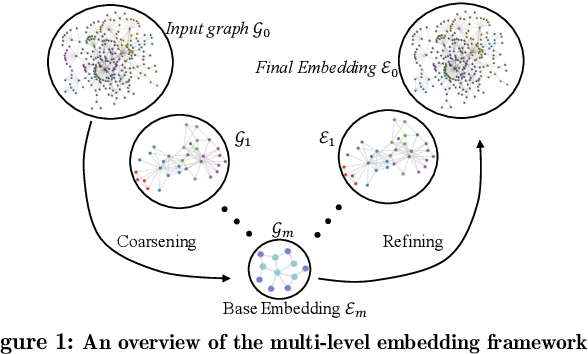
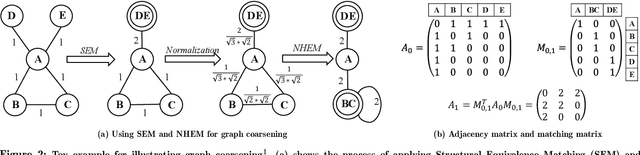
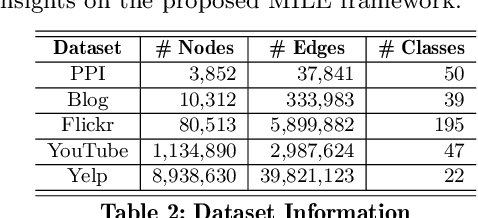
Recently there has been a surge of interest in designing graph embedding methods. Few, if any, can scale to a large-sized graph with millions of nodes due to both computational complexity and memory requirements. In this paper, we relax this limitation by introducing the MultI-Level Embedding (MILE) framework -- a generic methodology allowing contemporary graph embedding methods to scale to large graphs. MILE repeatedly coarsens the graph into smaller ones using a hybrid matching technique to maintain the backbone structure of the graph. It then applies existing embedding methods on the coarsest graph and refines the embeddings to the original graph through a novel graph convolution neural network that it learns. The proposed MILE framework is agnostic to the underlying graph embedding techniques and can be applied to many existing graph embedding methods without modifying them. We employ our framework on several popular graph embedding techniques and conduct embedding for real-world graphs. Experimental results on five large-scale datasets demonstrate that MILE significantly boosts the speed (order of magnitude) of graph embedding while also often generating embeddings of better quality for the task of node classification. MILE can comfortably scale to a graph with 9 million nodes and 40 million edges, on which existing methods run out of memory or take too long to compute on a modern workstation.
Robust Contextual Outlier Detection: Where Context Meets Sparsity
Dec 22, 2016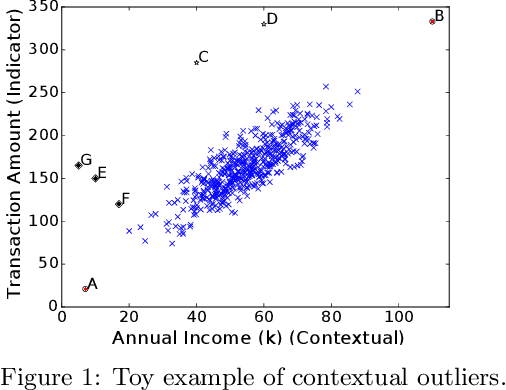



Outlier detection is a fundamental data science task with applications ranging from data cleaning to network security. Given the fundamental nature of the task, this has been the subject of much research. Recently, a new class of outlier detection algorithms has emerged, called {\it contextual outlier detection}, and has shown improved performance when studying anomalous behavior in a specific context. However, as we point out in this article, such approaches have limited applicability in situations where the context is sparse (i.e. lacking a suitable frame of reference). Moreover, approaches developed to date do not scale to large datasets. To address these problems, here we propose a novel and robust approach alternative to the state-of-the-art called RObust Contextual Outlier Detection (ROCOD). We utilize a local and global behavioral model based on the relevant contexts, which is then integrated in a natural and robust fashion. We also present several optimizations to improve the scalability of the approach. We run ROCOD on both synthetic and real-world datasets and demonstrate that it outperforms other competitive baselines on the axes of efficacy and efficiency (40X speedup compared to modern contextual outlier detection methods). We also drill down and perform a fine-grained analysis to shed light on the rationale for the performance gains of ROCOD and reveal its effectiveness when handling objects with sparse contexts.