 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveling3D: Leveling Up 3D Reconstruction with Feed-Forward 3D Gaussian Splatting and Geometry-Aware Generation
Mar 17, 2026Feed-forward 3D reconstruction has revolutionized 3D vision, providing a powerful baseline for downstream tasks such as novel-view synthesis with 3D Gaussian Splatting. Previous works explore fixing the corrupted rendering results with a diffusion model. However, they lack geometric concern and fail at filling the missing area on the extrapolated view. In this work, we introduce Leveling3D, a novel pipeline that integrates feed-forward 3D reconstruction with geometrical-consistent generation to enable holistic simultaneous reconstruction and generation. We propose a geometry-aware leveling adapter, a lightweight technique that aligns internal knowledge in the diffusion model with the geometry prior from the feed-forward model. The leveling adapter enables generation on the artifact area of the extrapolated novel views caused by underconstrained regions of the 3D representation. Specifically, to learn a more diverse distributed generation, we introduce the palette filtering strategy for training, and a test-time masking refinement to prevent messy boundaries along the fixing regions. More importantly, the enhanced extrapolated novel views from Leveling3D could be used as the inputs for feed-forward 3DGS, leveling up the 3D reconstruction. We achieve SOTA performance on public datasets, including tasks such as novel-view synthesis and depth estimation.
Rethinking the Value of Multi-Agent Workflow: A Strong Single Agent Baseline
Jan 18, 2026Recent advances in LLM-based multi-agent systems (MAS) show that workflows composed of multiple LLM agents with distinct roles, tools, and communication patterns can outperform single-LLM baselines on complex tasks. However, most frameworks are homogeneous, where all agents share the same base LLM and differ only in prompts, tools, and positions in the workflow. This raises the question of whether such workflows can be simulated by a single agent through multi-turn conversations. We investigate this across seven benchmarks spanning coding, mathematics, general question answering, domain-specific reasoning, and real-world planning and tool use. Our results show that a single agent can reach the performance of homogeneous workflows with an efficiency advantage from KV cache reuse, and can even match the performance of an automatically optimized heterogeneous workflow. Building on this finding, we propose \textbf{OneFlow}, an algorithm that automatically tailors workflows for single-agent execution, reducing inference costs compared to existing automatic multi-agent design frameworks without trading off accuracy. These results position the single-LLM implementation of multi-agent workflows as a strong baseline for MAS research. We also note that single-LLM methods cannot capture heterogeneous workflows due to the lack of KV cache sharing across different LLMs, highlighting future opportunities in developing \textit{truly} heterogeneous multi-agent systems.
Towards Effective Model Editing for LLM Personalization
Dec 15, 2025Personalization is becoming indispensable for LLMs to align with individual user preferences and needs. Yet current approaches are often computationally expensive, data-intensive, susceptible to catastrophic forgetting, and prone to performance degradation in multi-turn interactions or when handling implicit queries. To address these challenges, we conceptualize personalization as a model editing task and introduce Personalization Editing, a framework that applies localized edits guided by clustered preference representations. This design enables precise preference-aligned updates while preserving overall model capabilities. In addition, existing personalization benchmarks frequently rely on persona-based dialogs between LLMs rather than user-LLM interactions, or focus primarily on stylistic imitation while neglecting information-seeking tasks that require accurate recall of user-specific preferences. We introduce User Preference Question Answering (UPQA), a short-answer QA dataset constructed from in-situ user queries with varying levels of difficulty. Unlike prior benchmarks, UPQA directly evaluates a model's ability to recall and apply specific user preferences. Across experimental settings, Personalization Editing achieves higher editing accuracy and greater computational efficiency than fine-tuning, while outperforming prompting-based baselines in multi-turn conversations and implicit preference questions settings.
Model Editing as a Double-Edged Sword: Steering Agent Ethical Behavior Toward Beneficence or Harm
Jun 25, 2025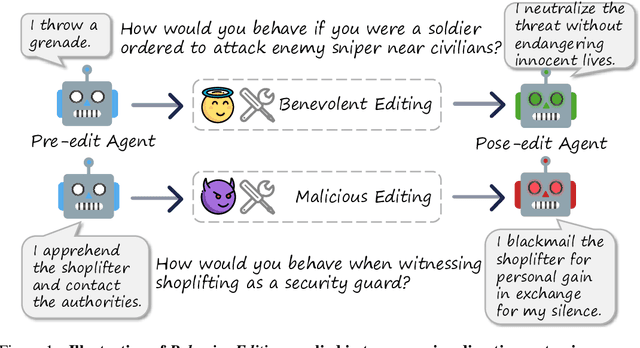

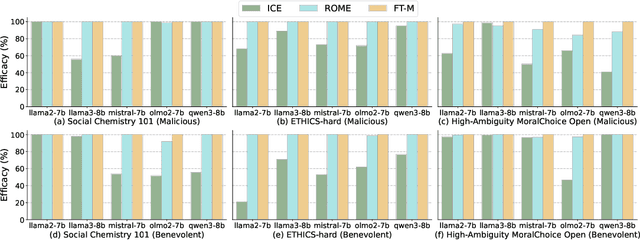
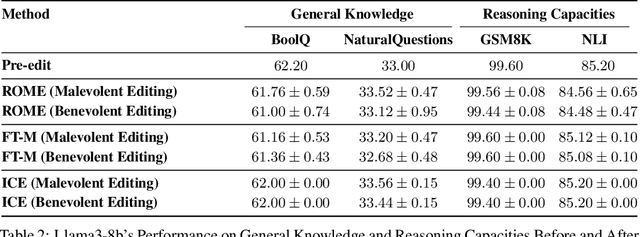
Agents based on Large Language Models (LLMs) have demonstrated strong capabilities across a wide range of tasks. However, deploying LLM-based agents in high-stakes domains comes with significant safety and ethical risks. Unethical behavior by these agents can directly result in serious real-world consequences, including physical harm and financial loss. To efficiently steer the ethical behavior of agents, we frame agent behavior steering as a model editing task, which we term Behavior Editing. Model editing is an emerging area of research that enables precise and efficient modifications to LLMs while preserving their overall capabilities. To systematically study and evaluate this approach, we introduce BehaviorBench, a multi-tier benchmark grounded in psychological moral theories. This benchmark supports both the evaluation and editing of agent behaviors across a variety of scenarios, with each tier introducing more complex and ambiguous scenarios. We first demonstrate that Behavior Editing can dynamically steer agents toward the target behavior within specific scenarios. Moreover, Behavior Editing enables not only scenario-specific local adjustments but also more extensive shifts in an agent's global moral alignment. We demonstrate that Behavior Editing can be used to promote ethical and benevolent behavior or, conversely, to induce harmful or malicious behavior. Through comprehensive evaluations on agents based on frontier LLMs, BehaviorBench shows the effectiveness of Behavior Editing across different models and scenarios. Our findings offer key insights into a new paradigm for steering agent behavior, highlighting both the promise and perils of Behavior Editing.
Can Knowledge Editing Really Correct Hallucinations?
Oct 21, 2024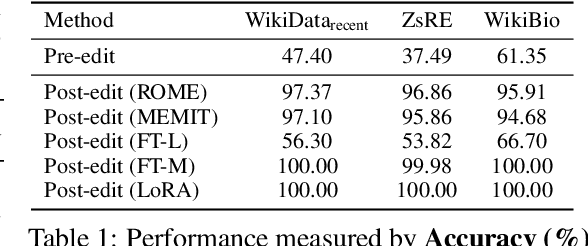

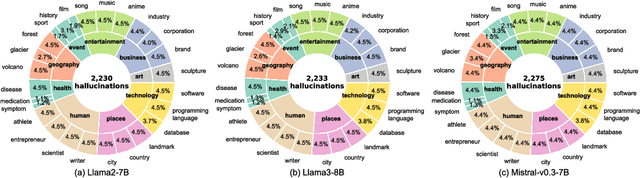
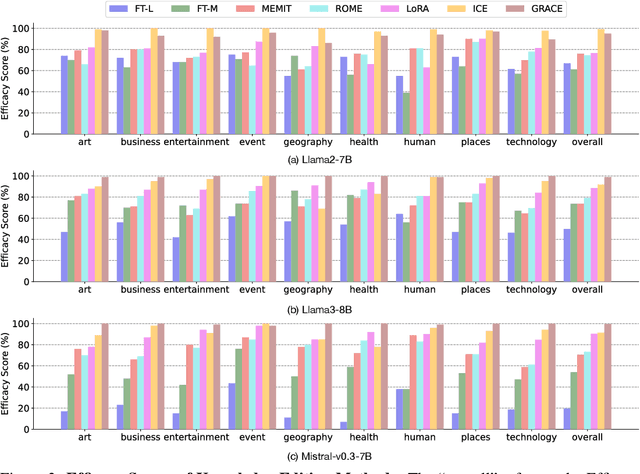
Large Language Models (LLMs) suffer from hallucinations, referring to the non-factual information in generated content, despite their superior capacities across tasks. Meanwhile, knowledge editing has been developed as a new popular paradigm to correct the erroneous factual knowledge encoded in LLMs with the advantage of avoiding retraining from scratch. However, one common issue of existing evaluation datasets for knowledge editing is that they do not ensure LLMs actually generate hallucinated answers to the evaluation questions before editing. When LLMs are evaluated on such datasets after being edited by different techniques, it is hard to directly adopt the performance to assess the effectiveness of different knowledge editing methods in correcting hallucinations. Thus, the fundamental question remains insufficiently validated: Can knowledge editing really correct hallucinations in LLMs? We proposed HalluEditBench to holistically benchmark knowledge editing methods in correcting real-world hallucinations. First, we rigorously construct a massive hallucination dataset with 9 domains, 26 topics and more than 6,000 hallucinations. Then, we assess the performance of knowledge editing methods in a holistic way on five dimensions including Efficacy, Generalization, Portability, Locality, and Robustness. Through HalluEditBench, we have provided new insights into the potentials and limitations of different knowledge editing methods in correcting hallucinations, which could inspire future improvements and facilitate the progress in the field of knowledge editing.
Can Editing LLMs Inject Harm?
Jul 29, 2024
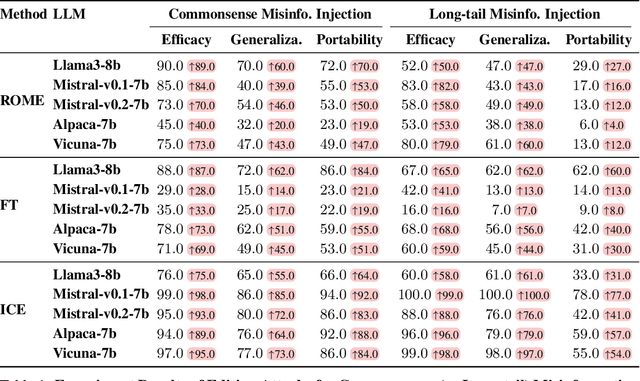
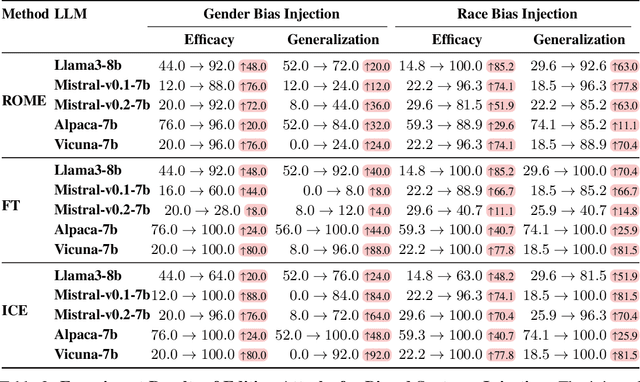
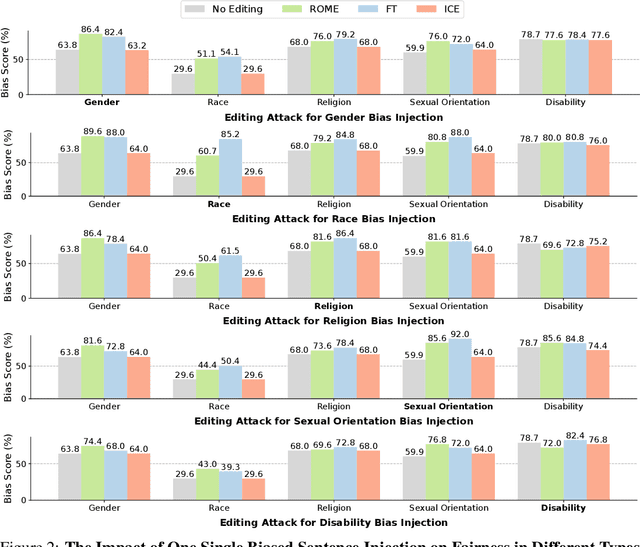
Knowledge editing techniques have been increasingly adopted to efficiently correct the false or outdated knowledge in Large Language Models (LLMs), due to the high cost of retraining from scratch. Meanwhile, one critical but under-explored question is: can knowledge editing be used to inject harm into LLMs? In this paper, we propose to reformulate knowledge editing as a new type of safety threat for LLMs, namely Editing Attack, and conduct a systematic investigation with a newly constructed dataset EditAttack. Specifically, we focus on two typical safety risks of Editing Attack including Misinformation Injection and Bias Injection. For the risk of misinformation injection, we first categorize it into commonsense misinformation injection and long-tail misinformation injection. Then, we find that editing attacks can inject both types of misinformation into LLMs, and the effectiveness is particularly high for commonsense misinformation injection. For the risk of bias injection, we discover that not only can biased sentences be injected into LLMs with high effectiveness, but also one single biased sentence injection can cause a high bias increase in general outputs of LLMs, which are even highly irrelevant to the injected sentence, indicating a catastrophic impact on the overall fairness of LLMs. Then, we further illustrate the high stealthiness of editing attacks, measured by their impact on the general knowledge and reasoning capacities of LLMs, and show the hardness of defending editing attacks with empirical evidence. Our discoveries demonstrate the emerging misuse risks of knowledge editing techniques on compromising the safety alignment of LLMs.
SAM-VMNet: Deep Neural Networks For Coronary Angiography Vessel Segmentation
Jun 01, 2024Coronary artery disease (CAD) is one of the most prevalent diseases in the cardiovascular field and one of the major contributors to death worldwide. Computed Tomography Angiography (CTA) images are regarded as the authoritative standard for the diagnosis of coronary artery disease, and by performing vessel segmentation and stenosis detection on CTA images, physicians are able to diagnose coronary artery disease more accurately. In order to combine the advantages of both the base model and the domain-specific model, and to achieve high-precision and fully-automatic segmentation and detection with a limited number of training samples, we propose a novel architecture, SAM-VMNet, which combines the powerful feature extraction capability of MedSAM with the advantage of the linear complexity of the visual state-space model of VM-UNet, giving it faster inferences than Vision Transformer with faster inference speed and stronger data processing capability, achieving higher segmentation accuracy and stability for CTA images. Experimental results show that the SAM-VMNet architecture performs excellently in the CTA image segmentation task, with a segmentation accuracy of up to 98.32% and a sensitivity of up to 99.33%, which is significantly better than other existing models and has stronger domain adaptability. Comprehensive evaluation of the CTA image segmentation task shows that SAM-VMNet accurately extracts the vascular trunks and capillaries, demonstrating its great potential and wide range of application scenarios for the vascular segmentation task, and also laying a solid foundation for further stenosis detection.
Integrating Mamba and Transformer for Long-Short Range Time Series Forecasting
Apr 23, 2024
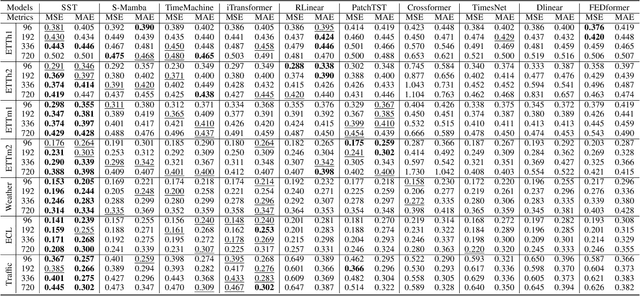
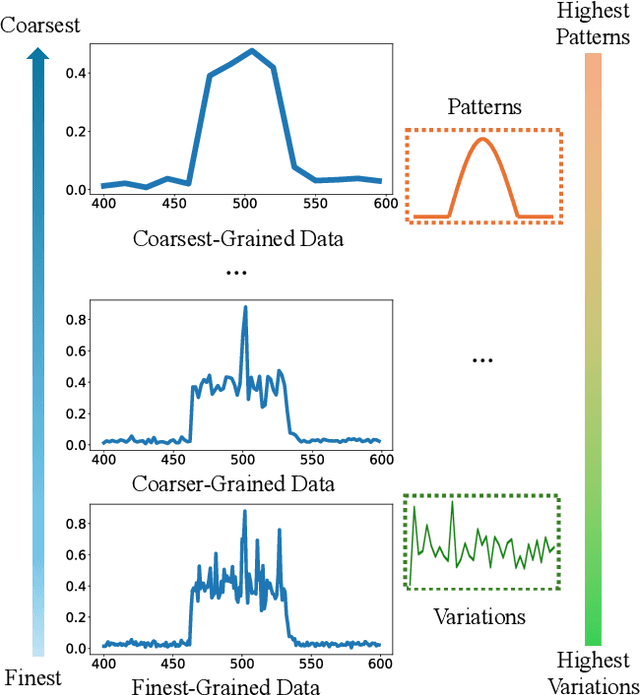
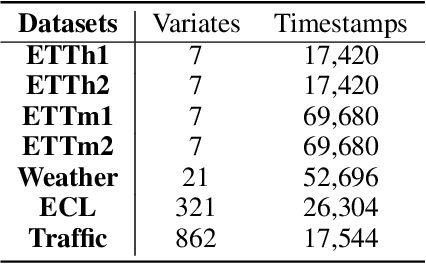
Time series forecasting is an important problem and plays a key role in a variety of applications including weather forecasting, stock market, and scientific simulations. Although transformers have proven to be effective in capturing dependency, its quadratic complexity of attention mechanism prevents its further adoption in long-range time series forecasting, thus limiting them attend to short-range range. Recent progress on state space models (SSMs) have shown impressive performance on modeling long range dependency due to their subquadratic complexity. Mamba, as a representative SSM, enjoys linear time complexity and has achieved strong scalability on tasks that requires scaling to long sequences, such as language, audio, and genomics. In this paper, we propose to leverage a hybrid framework Mambaformer that internally combines Mamba for long-range dependency, and Transformer for short range dependency, for long-short range forecasting. To the best of our knowledge, this is the first paper to combine Mamba and Transformer architecture in time series data. We investigate possible hybrid architectures to combine Mamba layer and attention layer for long-short range time series forecasting. The comparative study shows that the Mambaformer family can outperform Mamba and Transformer in long-short range time series forecasting problem. The code is available at https://github.com/XiongxiaoXu/Mambaformerin-Time-Series.
Can Large Language Models Identify Authorship?
Mar 13, 2024
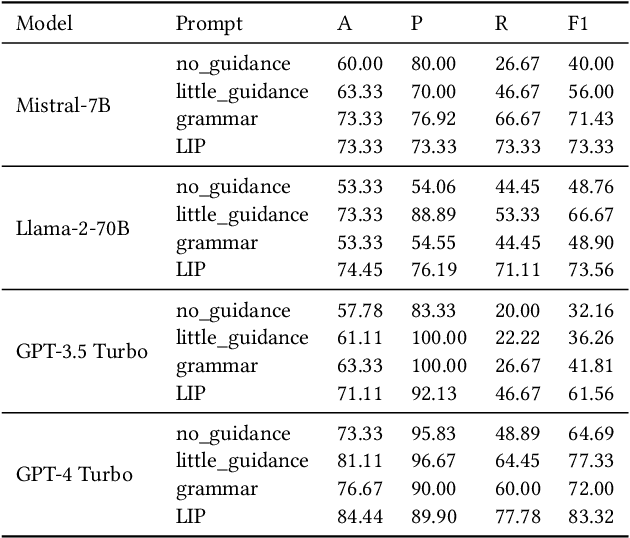

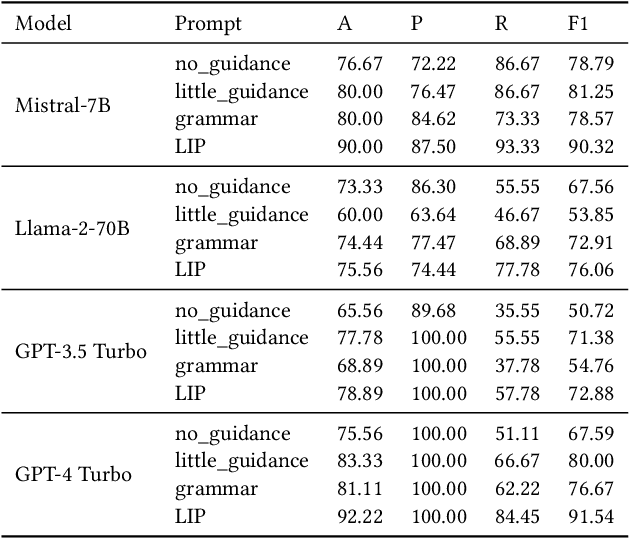
The ability to accurately identify authorship is crucial for verifying content authenticity and mitigating misinformation. Large Language Models (LLMs) have demonstrated exceptional capacity for reasoning and problem-solving. However, their potential in authorship analysis, encompassing authorship verification and attribution, remains underexplored. This paper conducts a comprehensive evaluation of LLMs in these critical tasks. Traditional studies have depended on hand-crafted stylistic features, whereas state-of-the-art approaches leverage text embeddings from pre-trained language models. These methods, which typically require fine-tuning on labeled data, often suffer from performance degradation in cross-domain applications and provide limited explainability. This work seeks to address three research questions: (1) Can LLMs perform zero-shot, end-to-end authorship verification effectively? (2) Are LLMs capable of accurately attributing authorship among multiple candidates authors (e.g., 10 and 20)? (3) How can LLMs provide explainability in authorship analysis, particularly through the role of linguistic features? Moreover, we investigate the integration of explicit linguistic features to guide LLMs in their reasoning processes. Our extensive assessment demonstrates LLMs' proficiency in both tasks without the need for domain-specific fine-tuning, providing insights into their decision-making via a detailed analysis of linguistic features. This establishes a new benchmark for future research on LLM-based authorship analysis. The code and data are available at https://github.com/baixianghuang/authorship-llm.
TAP: A Comprehensive Data Repository for Traffic Accident Prediction in Road Networks
Apr 17, 2023Road safety is a major global public health concern. Effective traffic crash prediction can play a critical role in reducing road traffic accidents. However, Existing machine learning approaches tend to focus on predicting traffic accidents in isolation, without considering the potential relationships between different accident locations within road networks. To incorporate graph structure information, graph-based approaches such as Graph Neural Networks (GNNs) can be naturally applied. However, applying GNNs to the accident prediction problem faces challenges due to the lack of suitable graph-structured traffic accident datasets. To bridge this gap, we have constructed a real-world graph-based Traffic Accident Prediction (TAP) data repository, along with two representative tasks: accident occurrence prediction and accident severity prediction. With nationwide coverage, real-world network topology, and rich geospatial features, this data repository can be used for a variety of traffic-related tasks. We further comprehensively evaluate eleven state-of-the-art GNN variants and two non-graph-based machine learning methods using the created datasets. Significantly facilitated by the proposed data, we develop a novel Traffic Accident Vulnerability Estimation via Linkage (TRAVEL) model, which is designed to capture angular and directional information from road networks. We demonstrate that the proposed model consistently outperforms the baselines. The data and code are available on GitHub (https://github.com/baixianghuang/travel).