 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Identify Authorship?
Paper and Code

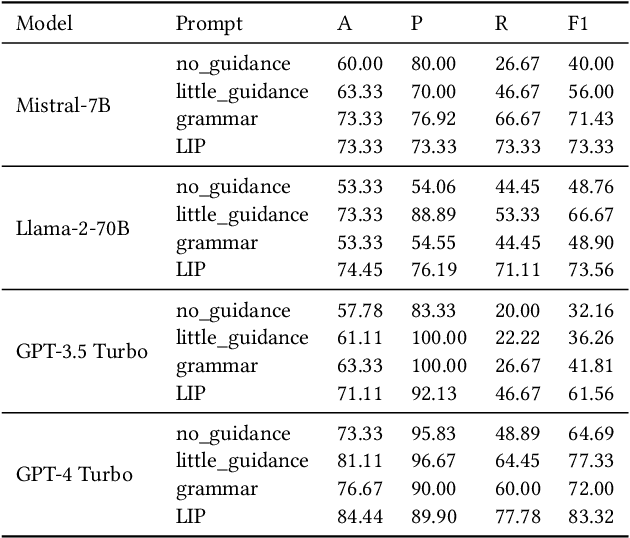

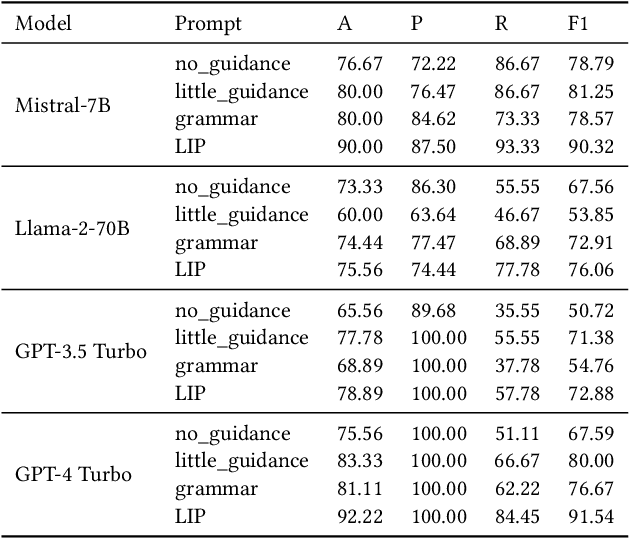
The ability to accurately identify authorship is crucial for verifying content authenticity and mitigating misinformation. Large Language Models (LLMs) have demonstrated exceptional capacity for reasoning and problem-solving. However, their potential in authorship analysis, encompassing authorship verification and attribution, remains underexplored. This paper conducts a comprehensive evaluation of LLMs in these critical tasks. Traditional studies have depended on hand-crafted stylistic features, whereas state-of-the-art approaches leverage text embeddings from pre-trained language models. These methods, which typically require fine-tuning on labeled data, often suffer from performance degradation in cross-domain applications and provide limited explainability. This work seeks to address three research questions: (1) Can LLMs perform zero-shot, end-to-end authorship verification effectively? (2) Are LLMs capable of accurately attributing authorship among multiple candidates authors (e.g., 10 and 20)? (3) How can LLMs provide explainability in authorship analysis, particularly through the role of linguistic features? Moreover, we investigate the integration of explicit linguistic features to guide LLMs in their reasoning processes. Our extensive assessment demonstrates LLMs' proficiency in both tasks without the need for domain-specific fine-tuning, providing insights into their decision-making via a detailed analysis of linguistic features. This establishes a new benchmark for future research on LLM-based authorship analysis. The code and data are available at https://github.com/baixianghuang/authorship-llm.