 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Editing LLMs Inject Harm?
Paper and Code

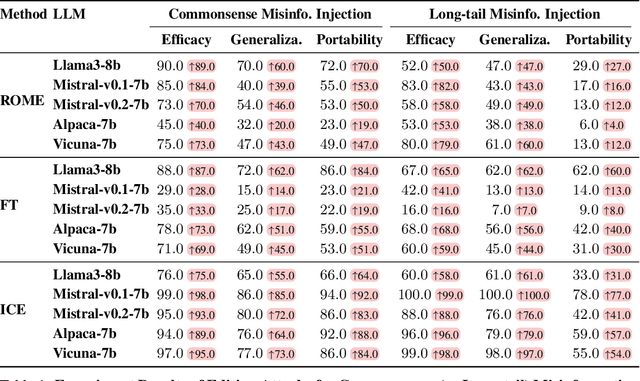
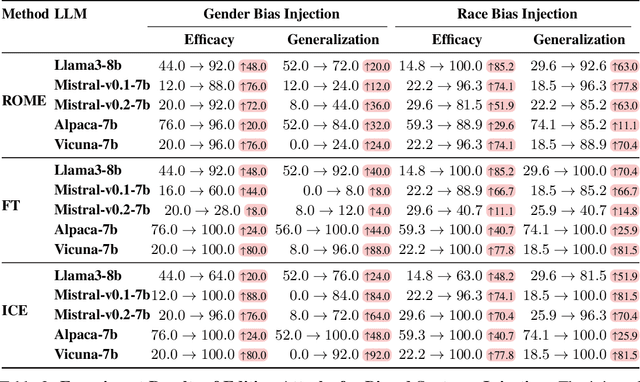
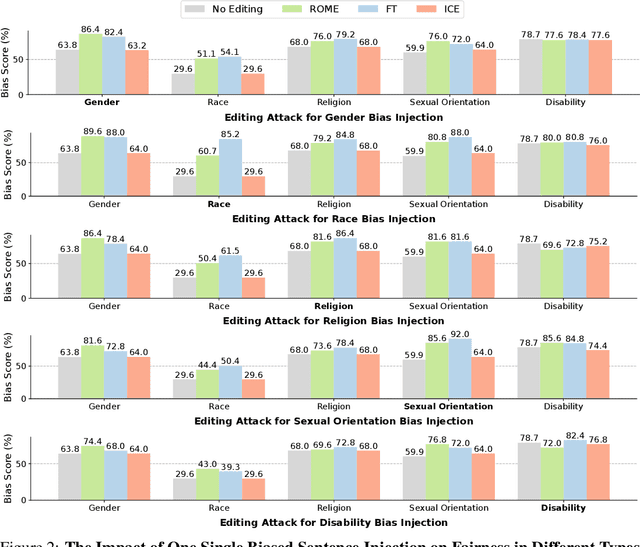
Knowledge editing techniques have been increasingly adopted to efficiently correct the false or outdated knowledge in Large Language Models (LLMs), due to the high cost of retraining from scratch. Meanwhile, one critical but under-explored question is: can knowledge editing be used to inject harm into LLMs? In this paper, we propose to reformulate knowledge editing as a new type of safety threat for LLMs, namely Editing Attack, and conduct a systematic investigation with a newly constructed dataset EditAttack. Specifically, we focus on two typical safety risks of Editing Attack including Misinformation Injection and Bias Injection. For the risk of misinformation injection, we first categorize it into commonsense misinformation injection and long-tail misinformation injection. Then, we find that editing attacks can inject both types of misinformation into LLMs, and the effectiveness is particularly high for commonsense misinformation injection. For the risk of bias injection, we discover that not only can biased sentences be injected into LLMs with high effectiveness, but also one single biased sentence injection can cause a high bias increase in general outputs of LLMs, which are even highly irrelevant to the injected sentence, indicating a catastrophic impact on the overall fairness of LLMs. Then, we further illustrate the high stealthiness of editing attacks, measured by their impact on the general knowledge and reasoning capacities of LLMs, and show the hardness of defending editing attacks with empirical evidence. Our discoveries demonstrate the emerging misuse risks of knowledge editing techniques on compromising the safety alignment of LLMs.