 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Models Generate Societies of Thought
Jan 15, 2026Large language models have achieved remarkable capabilities across domains, yet mechanisms underlying sophisticated reasoning remain elusive. Recent reasoning models outperform comparable instruction-tuned models on complex cognitive tasks, attributed to extended computation through longer chains of thought. Here we show that enhanced reasoning emerges not from extended computation alone, but from simulating multi-agent-like interactions -- a society of thought -- which enables diversification and debate among internal cognitive perspectives characterized by distinct personality traits and domain expertise. Through quantitative analysis and mechanistic interpretability methods applied to reasoning traces, we find that reasoning models like DeepSeek-R1 and QwQ-32B exhibit much greater perspective diversity than instruction-tuned models, activating broader conflict between heterogeneous personality- and expertise-related features during reasoning. This multi-agent structure manifests in conversational behaviors, including question-answering, perspective shifts, and the reconciliation of conflicting views, and in socio-emotional roles that characterize sharp back-and-forth conversations, together accounting for the accuracy advantage in reasoning tasks. Controlled reinforcement learning experiments reveal that base models increase conversational behaviors when rewarded solely for reasoning accuracy, and fine-tuning models with conversational scaffolding accelerates reasoning improvement over base models. These findings indicate that the social organization of thought enables effective exploration of solution spaces. We suggest that reasoning models establish a computational parallel to collective intelligence in human groups, where diversity enables superior problem-solving when systematically structured, which suggests new opportunities for agent organization to harness the wisdom of crowds.
Probing Multimodal Large Language Models on Cognitive Biases in Chinese Short-Video Misinformation
Jan 10, 2026Short-video platforms have become major channels for misinformation, where deceptive claims frequently leverage visual experiments and social cues. While Multimodal Large Language Models (MLLMs) have demonstrated impressive reasoning capabilities, their robustness against misinformation entangled with cognitive biases remains under-explored. In this paper, we introduce a comprehensive evaluation framework using a high-quality, manually annotated dataset of 200 short videos spanning four health domains. This dataset provides fine-grained annotations for three deceptive patterns, experimental errors, logical fallacies, and fabricated claims, each verified by evidence such as national standards and academic literature. We evaluate eight frontier MLLMs across five modality settings. Experimental results demonstrate that Gemini-2.5-Pro achieves the highest performance in the multimodal setting with a belief score of 71.5/100, while o3 performs the worst at 35.2. Furthermore, we investigate social cues that induce false beliefs in videos and find that models are susceptible to biases like authoritative channel IDs.
Probing the Vulnerability of Large Language Models to Polysemantic Interventions
May 16, 2025



Polysemanticity -- where individual neurons encode multiple unrelated features -- is a well-known characteristic of large neural networks and remains a central challenge in the interpretability of language models. At the same time, its implications for model safety are also poorly understood. Leveraging recent advances in sparse autoencoders, we investigate the polysemantic structure of two small models (Pythia-70M and GPT-2-Small) and evaluate their vulnerability to targeted, covert interventions at the prompt, feature, token, and neuron levels. Our analysis reveals a consistent polysemantic topology shared across both models. Strikingly, we demonstrate that this structure can be exploited to mount effective interventions on two larger, black-box instruction-tuned models (LLaMA3.1-8B-Instruct and Gemma-2-9B-Instruct). These findings suggest not only the generalizability of the interventions but also point to a stable and transferable polysemantic structure that could potentially persist across architectures and training regimes.
Big Data and the Computational Social Science of Entrepreneurship and Innovation
May 13, 2025As large-scale social data explode and machine-learning methods evolve, scholars of entrepreneurship and innovation face new research opportunities but also unique challenges. This chapter discusses the difficulties of leveraging large-scale data to identify technological and commercial novelty, document new venture origins, and forecast competition between new technologies and commercial forms. It suggests how scholars can take advantage of new text, network, image, audio, and video data in two distinct ways that advance innovation and entrepreneurship research. First, machine-learning models, combined with large-scale data, enable the construction of precision measurements that function as system-level observatories of innovation and entrepreneurship across human societies. Second, new artificial intelligence models fueled by big data generate 'digital doubles' of technology and business, forming laboratories for virtual experimentation about innovation and entrepreneurship processes and policies. The chapter argues for the advancement of theory development and testing in entrepreneurship and innovation by coupling big data with big models.
Hidden Persuaders: LLMs' Political Leaning and Their Influence on Voters
Oct 31, 2024



How could LLMs influence our democracy? We investigate LLMs' political leanings and the potential influence of LLMs on voters by conducting multiple experiments in a U.S. presidential election context. Through a voting simulation, we first demonstrate 18 open- and closed-weight LLMs' political preference for a Democratic nominee over a Republican nominee. We show how this leaning towards the Democratic nominee becomes more pronounced in instruction-tuned models compared to their base versions by analyzing their responses to candidate-policy related questions. We further explore the potential impact of LLMs on voter choice by conducting an experiment with 935 U.S. registered voters. During the experiments, participants interacted with LLMs (Claude-3, Llama-3, and GPT-4) over five exchanges. The experiment results show a shift in voter choices towards the Democratic nominee following LLM interaction, widening the voting margin from 0.7% to 4.6%, even though LLMs were not asked to persuade users to support the Democratic nominee during the discourse. This effect is larger than many previous studies on the persuasiveness of political campaigns, which have shown minimal effects in presidential elections. Many users also expressed a desire for further political interaction with LLMs. Which aspects of LLM interactions drove these shifts in voter choice requires further study. Lastly, we explore how a safety method can make LLMs more politically neutral, while leaving some open questions.
Can Editing LLMs Inject Harm?
Jul 29, 2024
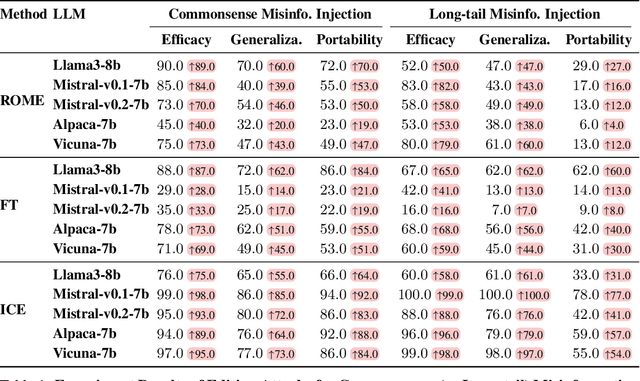
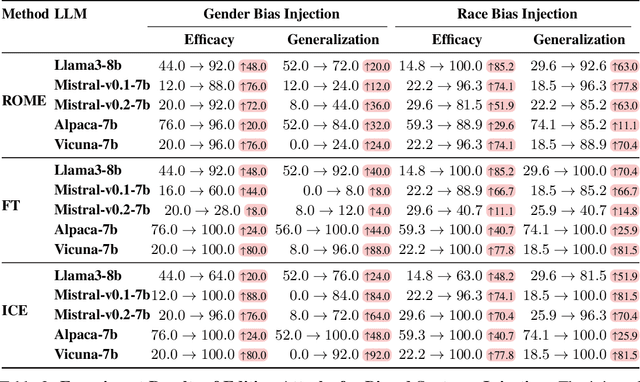
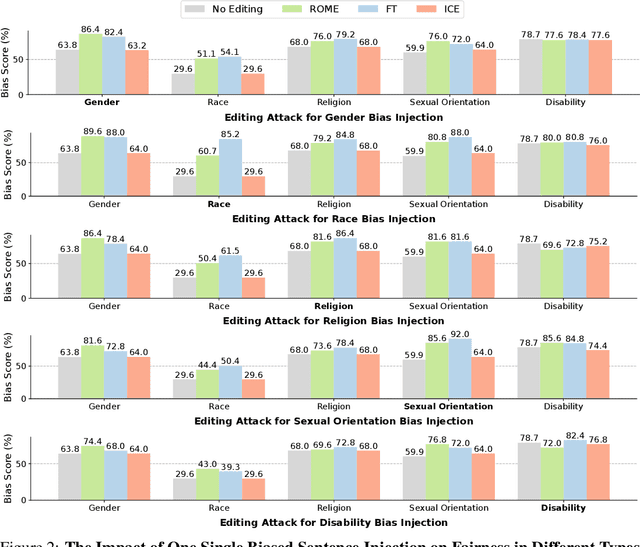
Knowledge editing techniques have been increasingly adopted to efficiently correct the false or outdated knowledge in Large Language Models (LLMs), due to the high cost of retraining from scratch. Meanwhile, one critical but under-explored question is: can knowledge editing be used to inject harm into LLMs? In this paper, we propose to reformulate knowledge editing as a new type of safety threat for LLMs, namely Editing Attack, and conduct a systematic investigation with a newly constructed dataset EditAttack. Specifically, we focus on two typical safety risks of Editing Attack including Misinformation Injection and Bias Injection. For the risk of misinformation injection, we first categorize it into commonsense misinformation injection and long-tail misinformation injection. Then, we find that editing attacks can inject both types of misinformation into LLMs, and the effectiveness is particularly high for commonsense misinformation injection. For the risk of bias injection, we discover that not only can biased sentences be injected into LLMs with high effectiveness, but also one single biased sentence injection can cause a high bias increase in general outputs of LLMs, which are even highly irrelevant to the injected sentence, indicating a catastrophic impact on the overall fairness of LLMs. Then, we further illustrate the high stealthiness of editing attacks, measured by their impact on the general knowledge and reasoning capacities of LLMs, and show the hardness of defending editing attacks with empirical evidence. Our discoveries demonstrate the emerging misuse risks of knowledge editing techniques on compromising the safety alignment of LLMs.
Evolving AI Collectives to Enhance Human Diversity and Enable Self-Regulation
Feb 19, 2024



Large language models steer their behaviors based on texts generated by others. This capacity and their increasing prevalence in online settings portend that they will intentionally or unintentionally "program" one another and form emergent AI subjectivities, relationships, and collectives. Here, we call upon the research community to investigate these "society-like" properties of interacting artificial intelligences to increase their rewards and reduce their risks for human society and the health of online environments. We use a simple model and its outputs to illustrate how such emergent, decentralized AI collectives can expand the bounds of human diversity and reduce the risk of toxic, anti-social behavior online. Finally, we discuss opportunities for AI self-moderation and address ethical issues and design challenges associated with creating and maintaining decentralized AI collectives.
Multidimensional Service Quality Scoring System
Dec 09, 2022This supplementary paper aims to introduce the Multidimensional Service Quality Scoring System (MSQs), a review-based method for quantifying host service quality mentioned and employed in the paper Exit and transition: Exploring the survival status of Airbnb listings in a time of professionalization. MSQs is not an end-to-end implementation and is essentially composed of three pipelines, namely Data Collection and Preprocessing, Objects Recognition and Grouping, and Aspect-based Service Scoring. Using the study mentioned above as a case, the technical details of MSQs are explained in this article.