 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinAnchor: Aligned Multi-Model Representations for Financial Prediction
Feb 24, 2026Financial prediction from long documents involves significant challenges, as actionable signals are often sparse and obscured by noise, and the optimal LLM for generating embeddings varies across tasks and time periods. In this paper, we propose FinAnchor(Financial Anchored Representations), a lightweight framework that integrates embeddings from multiple LLMs without fine-tuning the underlying models. FinAnchor addresses the incompatibility of feature spaces by selecting an anchor embedding space and learning linear mappings to align representations from other models into this anchor. These aligned features are then aggregated to form a unified representation for downstream prediction. Across multiple financial NLP tasks, FinAnchor consistently outperforms strong single-model baselines and standard ensemble methods, demonstrating the effectiveness of anchoring heterogeneous representations for robust financial prediction.
Rep2Text: Decoding Full Text from a Single LLM Token Representation
Nov 09, 2025Large language models (LLMs) have achieved remarkable progress across diverse tasks, yet their internal mechanisms remain largely opaque. In this work, we address a fundamental question: to what extent can the original input text be recovered from a single last-token representation within an LLM? We propose Rep2Text, a novel framework for decoding full text from last-token representations. Rep2Text employs a trainable adapter that projects a target model's internal representations into the embedding space of a decoding language model, which then autoregressively reconstructs the input text. Experiments on various model combinations (Llama-3.1-8B, Gemma-7B, Mistral-7B-v0.1, Llama-3.2-3B) demonstrate that, on average, over half of the information in 16-token sequences can be recovered from this compressed representation while maintaining strong semantic integrity and coherence. Furthermore, our analysis reveals an information bottleneck effect: longer sequences exhibit decreased token-level recovery while preserving strong semantic integrity. Besides, our framework also demonstrates robust generalization to out-of-distribution medical data.
SAE-SSV: Supervised Steering in Sparse Representation Spaces for Reliable Control of Language Models
May 22, 2025Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but controlling their behavior reliably remains challenging, especially in open-ended generation settings. This paper introduces a novel supervised steering approach that operates in sparse, interpretable representation spaces. We employ sparse autoencoders (SAEs)to obtain sparse latent representations that aim to disentangle semantic attributes from model activations. Then we train linear classifiers to identify a small subspace of task-relevant dimensions in latent representations. Finally, we learn supervised steering vectors constrained to this subspace, optimized to align with target behaviors. Experiments across sentiment, truthfulness, and politics polarity steering tasks with multiple LLMs demonstrate that our supervised steering vectors achieve higher success rates with minimal degradation in generation quality compared to existing methods. Further analysis reveals that a notably small subspace is sufficient for effective steering, enabling more targeted and interpretable interventions.
SAIF: A Sparse Autoencoder Framework for Interpreting and Steering Instruction Following of Language Models
Feb 17, 2025The ability of large language models (LLMs) to follow instructions is crucial for their practical applications, yet the underlying mechanisms remain poorly understood. This paper presents a novel framework that leverages sparse autoencoders (SAE) to interpret how instruction following works in these models. We demonstrate how the features we identify can effectively steer model outputs to align with given instructions. Through analysis of SAE latent activations, we identify specific latents responsible for instruction following behavior. Our findings reveal that instruction following capabilities are encoded by a distinct set of instruction-relevant SAE latents. These latents both show semantic proximity to relevant instructions and demonstrate causal effects on model behavior. Our research highlights several crucial factors for achieving effective steering performance: precise feature identification, the role of final layer, and optimal instruction positioning. Additionally, we demonstrate that our methodology scales effectively across SAEs and LLMs of varying sizes.
Mitigating Shortcuts in Language Models with Soft Label Encoding
Sep 17, 2023
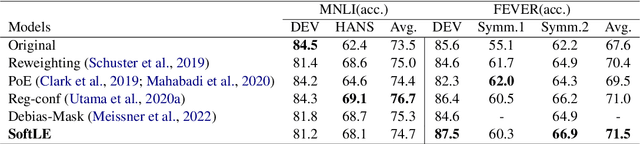
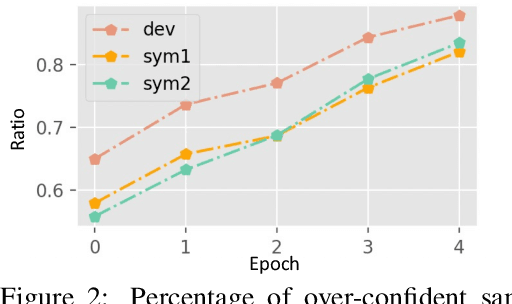

Recent research has shown that large language models rely on spurious correlations in the data for natural language understanding (NLU) tasks. In this work, we aim to answer the following research question: Can we reduce spurious correlations by modifying the ground truth labels of the training data? Specifically, we propose a simple yet effective debiasing framework, named Soft Label Encoding (SoftLE). We first train a teacher model with hard labels to determine each sample's degree of relying on shortcuts. We then add one dummy class to encode the shortcut degree, which is used to smooth other dimensions in the ground truth label to generate soft labels. This new ground truth label is used to train a more robust student model. Extensive experiments on two NLU benchmark tasks demonstrate that SoftLE significantly improves out-of-distribution generalization while maintaining satisfactory in-distribution accuracy.