 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutsmarting the Chameleon: Counterfactual Decoupling for Tactical OOD Shifts in Live Streaming Risk Assessment
Jun 01, 2026Live streaming has emerged as a primary medium for social interaction and digital commerce, yet it is increasingly plagued by sophisticated risks. A fundamental challenge in this domain is \emph{tactical out-of-distribution (OOD) shift}: while malicious actors maintain stable underlying objectives, they continuously redesign narrative packaging to evade detection. Such adversarial shifts expose critical limitations of existing OOD generalization paradigms, whose assumptions are difficult to satisfy in the presence of tightly coupled intent-tactic evolution and ill-defined raw-level counterfactuals. In this paper, we tackle this issue from a \emph{latent causal} perspective and propose \underline{L}atent-\underline{P}redictive \underline{C}ounterfactual \underline{D}ecoupling~(LPCD), a plug-in framework for robust live streaming risk assessment. LPCD enables counterfactual reasoning under adversarial tactical re-packaging by modeling intent and narrative variation at the latent level, and enforces \emph{latent counterfactual consistency} to anchor risk prediction on causally stable malicious intent. At inference time, LPCD applies a lightweight, parameter-free calibration to further mitigate tactic-induced distribution shifts. Extensive experiments on large-scale industrial datasets and online production traffic demonstrate that LPCD consistently outperforms state-of-the-art baselines, validating its effectiveness in moderating evolving adversarial risks in real-world live streaming. The project page is available at https://qiaoyran.github.io/LiveStreamingRiskAssessment/.
Structured 3D Latents Are Surprisingly Powerful: Unleashing Generalizable Style with 2D Diffusion
May 06, 20263D asset generation plays a pivotal role in fields such as gaming and virtual reality, enabling the rapid synthesis of high-fidelity 3D objects from a single or multiple images. Building on this capability, enabling style-controllable generation naturally emerges as an important and desirable direction. However, existing approaches typically rely on style images that lie within or are similar to the training distribution of 3D generation models. When presented with out-of-distribution (OOD) styles, their performance degrades significantly or even fails. To address this limitation, we introduce $\textbf{DiLAST}$: 2D Diffusion-based Latent Awakening for 3D Style Transfer. Specifically, we leverage a pretrained 2D diffusion model as a teacher to provide rich and generalizable style priors. By aligning rendered views with the target style under diffusion-based guidance, our method optimizes the structured 3D latent representation for stylization. We observe that this limitation stems not from insufficient model capacity, but from the underutilization of structured 3D latents, which are inherently expressive. Despite being trained on comparatively limited data, 3D generation models can leverage 2D diffusion guidance to steer denoising toward specific directions in latent space, thereby producing diverse, OOD styles. Extensive experiments across diverse data and multiple 3D generation backbones demonstrate the effectiveness and plug-and-play nature of our approach.
AdvSplat: Adversarial Attacks on Feed-Forward Gaussian Splatting Models
Mar 24, 20263D Gaussian Splatting (3DGS) is increasingly recognized as a powerful paradigm for real-time, high-fidelity 3D reconstruction. However, its per-scene optimization pipeline limits scalability and generalization, and prevents efficient inference. Recently emerged feed-forward 3DGS models address these limitations by enabling fast reconstruction from a few input views after large-scale pretraining, without scene-specific optimization. Despite their advantages and strong potential for commercial deployment, the use of neural networks as the backbone also amplifies the risk of adversarial manipulation. In this paper, we introduce AdvSplat, the first systematic study of adversarial attacks on feed-forward 3DGS. We first employ white-box attacks to reveal fundamental vulnerabilities of this model family. We then develop two improved, practically relevant, query-efficient black-box algorithms that optimize pixel-space perturbations via a frequency-domain parameterization: one based on gradient estimation and the other gradient-free, without requiring any access to model internals. Extensive experiments across multiple datasets demonstrate that AdvSplat can significantly disrupt reconstruction results by injecting imperceptible perturbations into the input images. Our findings surface an overlooked yet urgent problem in this domain, and we hope to draw the community's attention to this emerging security and robustness challenge.
DefenseSplat: Enhancing the Robustness of 3D Gaussian Splatting via Frequency-Aware Filtering
Feb 22, 20263D Gaussian Splatting (3DGS) has emerged as a powerful paradigm for real-time and high-fidelity 3D reconstruction from posed images. However, recent studies reveal its vulnerability to adversarial corruptions in input views, where imperceptible yet consistent perturbations can drastically degrade rendering quality, increase training and rendering time, and inflate memory usage, even leading to server denial-of-service. In our work, to mitigate this issue, we begin by analyzing the distinct behaviors of adversarial perturbations in the low- and high-frequency components of input images using wavelet transforms. Based on this observation, we design a simple yet effective frequency-aware defense strategy that reconstructs training views by filtering high-frequency noise while preserving low-frequency content. This approach effectively suppresses adversarial artifacts while maintaining the authenticity of the original scene. Notably, it does not significantly impair training on clean data, achieving a desirable trade-off between robustness and performance on clean inputs. Through extensive experiments under a wide range of attack intensities on multiple benchmarks, we demonstrate that our method substantially enhances the robustness of 3DGS without access to clean ground-truth supervision. By highlighting and addressing the overlooked vulnerabilities of 3D Gaussian Splatting, our work paves the way for more robust and secure 3D reconstructions.
Live or Lie: Action-Aware Capsule Multiple Instance Learning for Risk Assessment in Live Streaming Platforms
Feb 03, 2026Live streaming has become a cornerstone of today's internet, enabling massive real-time social interactions. However, it faces severe risks arising from sparse, coordinated malicious behaviors among multiple participants, which are often concealed within normal activities and challenging to detect timely and accurately. In this work, we provide a pioneering study on risk assessment in live streaming rooms, characterized by weak supervision where only room-level labels are available. We formulate the task as a Multiple Instance Learning (MIL) problem, treating each room as a bag and defining structured user-timeslot capsules as instances. These capsules represent subsequences of user actions within specific time windows, encapsulating localized behavioral patterns. Based on this formulation, we propose AC-MIL, an Action-aware Capsule MIL framework that models both individual behaviors and group-level coordination patterns. AC-MIL captures multi-granular semantics and behavioral cues through a serial and parallel architecture that jointly encodes temporal dynamics and cross-user dependencies. These signals are integrated for robust room-level risk prediction, while also offering interpretable evidence at the behavior segment level. Extensive experiments on large-scale industrial datasets from Douyin demonstrate that AC-MIL significantly outperforms MIL and sequential baselines, establishing new state-of-the-art performance in room-level risk assessment for live streaming. Moreover, AC-MIL provides capsule-level interpretability, enabling identification of risky behavior segments as actionable evidence for intervention. The project page is available at: https://qiaoyran.github.io/AC-MIL/.
Deja Vu in Plots: Leveraging Cross-Session Evidence with Retrieval-Augmented LLMs for Live Streaming Risk Assessment
Jan 22, 2026The rise of live streaming has transformed online interaction, enabling massive real-time engagement but also exposing platforms to complex risks such as scams and coordinated malicious behaviors. Detecting these risks is challenging because harmful actions often accumulate gradually and recur across seemingly unrelated streams. To address this, we propose CS-VAR (Cross-Session Evidence-Aware Retrieval-Augmented Detector) for live streaming risk assessment. In CS-VAR, a lightweight, domain-specific model performs fast session-level risk inference, guided during training by a Large Language Model (LLM) that reasons over retrieved cross-session behavioral evidence and transfers its local-to-global insights to the small model. This design enables the small model to recognize recurring patterns across streams, perform structured risk assessment, and maintain efficiency for real-time deployment. Extensive offline experiments on large-scale industrial datasets, combined with online validation, demonstrate the state-of-the-art performance of CS-VAR. Furthermore, CS-VAR provides interpretable, localized signals that effectively empower real-world moderation for live streaming.
When 'YES' Meets 'BUT': Can Large Models Comprehend Contradictory Humor Through Comparative Reasoning?
Mar 29, 2025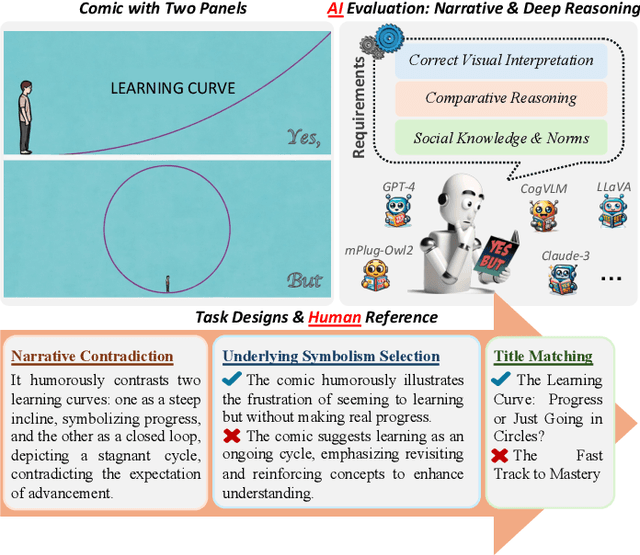



Understanding humor-particularly when it involves complex, contradictory narratives that require comparative reasoning-remains a significant challenge for large vision-language models (VLMs). This limitation hinders AI's ability to engage in human-like reasoning and cultural expression. In this paper, we investigate this challenge through an in-depth analysis of comics that juxtapose panels to create humor through contradictions. We introduce the YesBut (V2), a novel benchmark with 1,262 comic images from diverse multilingual and multicultural contexts, featuring comprehensive annotations that capture various aspects of narrative understanding. Using this benchmark, we systematically evaluate a wide range of VLMs through four complementary tasks spanning from surface content comprehension to deep narrative reasoning, with particular emphasis on comparative reasoning between contradictory elements. Our extensive experiments reveal that even the most advanced models significantly underperform compared to humans, with common failures in visual perception, key element identification, comparative analysis and hallucinations. We further investigate text-based training strategies and social knowledge augmentation methods to enhance model performance. Our findings not only highlight critical weaknesses in VLMs' understanding of cultural and creative expressions but also provide pathways toward developing context-aware models capable of deeper narrative understanding though comparative reasoning.
Segment then Splat: A Unified Approach for 3D Open-Vocabulary Segmentation based on Gaussian Splatting
Mar 28, 2025Open-vocabulary querying in 3D space is crucial for enabling more intelligent perception in applications such as robotics, autonomous systems, and augmented reality. However, most existing methods rely on 2D pixel-level parsing, leading to multi-view inconsistencies and poor 3D object retrieval. Moreover, they are limited to static scenes and struggle with dynamic scenes due to the complexities of motion modeling. In this paper, we propose Segment then Splat, a 3D-aware open vocabulary segmentation approach for both static and dynamic scenes based on Gaussian Splatting. Segment then Splat reverses the long established approach of "segmentation after reconstruction" by dividing Gaussians into distinct object sets before reconstruction. Once the reconstruction is complete, the scene is naturally segmented into individual objects, achieving true 3D segmentation. This approach not only eliminates Gaussian-object misalignment issues in dynamic scenes but also accelerates the optimization process, as it eliminates the need for learning a separate language field. After optimization, a CLIP embedding is assigned to each object to enable open-vocabulary querying. Extensive experiments on various datasets demonstrate the effectiveness of our proposed method in both static and dynamic scenarios.
CAUSAL3D: A Comprehensive Benchmark for Causal Learning from Visual Data
Mar 06, 2025True intelligence hinges on the ability to uncover and leverage hidden causal relations. Despite significant progress in AI and computer vision (CV), there remains a lack of benchmarks for assessing models' abilities to infer latent causality from complex visual data. In this paper, we introduce \textsc{\textbf{Causal3D}}, a novel and comprehensive benchmark that integrates structured data (tables) with corresponding visual representations (images) to evaluate causal reasoning. Designed within a systematic framework, Causal3D comprises 19 3D-scene datasets capturing diverse causal relations, views, and backgrounds, enabling evaluations across scenes of varying complexity. We assess multiple state-of-the-art methods, including classical causal discovery, causal representation learning, and large/vision-language models (LLMs/VLMs). Our experiments show that as causal structures grow more complex without prior knowledge, performance declines significantly, highlighting the challenges even advanced methods face in complex causal scenarios. Causal3D serves as a vital resource for advancing causal reasoning in CV and fostering trustworthy AI in critical domains.
SAIF: A Sparse Autoencoder Framework for Interpreting and Steering Instruction Following of Language Models
Feb 17, 2025The ability of large language models (LLMs) to follow instructions is crucial for their practical applications, yet the underlying mechanisms remain poorly understood. This paper presents a novel framework that leverages sparse autoencoders (SAE) to interpret how instruction following works in these models. We demonstrate how the features we identify can effectively steer model outputs to align with given instructions. Through analysis of SAE latent activations, we identify specific latents responsible for instruction following behavior. Our findings reveal that instruction following capabilities are encoded by a distinct set of instruction-relevant SAE latents. These latents both show semantic proximity to relevant instructions and demonstrate causal effects on model behavior. Our research highlights several crucial factors for achieving effective steering performance: precise feature identification, the role of final layer, and optimal instruction positioning. Additionally, we demonstrate that our methodology scales effectively across SAEs and LLMs of varying sizes.